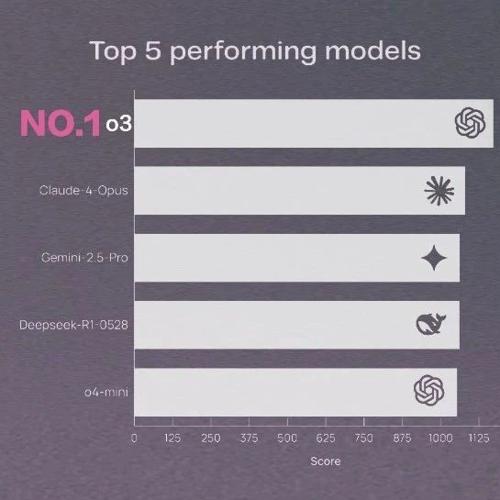
2025 年中丨大模型市场分析报告

本文分析了2025年大语言模型市场的发展现状及未来趋势,包括API支出的增长、企业重心从训练转向推理、代码生成成为AI杀手级应用等关键点。同时指出,开源模型在性能和部署复杂度上仍落后于闭源模型,导致其市场份额停滞不前。总体来看,新一代持久的AI业务正在成熟建立条件。
本文分析了2025年大语言模型市场的发展现状及未来趋势,包括API支出的增长、企业重心从训练转向推理、代码生成成为AI杀手级应用等关键点。同时指出,开源模型在性能和部署复杂度上仍落后于闭源模型,导致其市场份额停滞不前。总体来看,新一代持久的AI业务正在成熟建立条件。

MLNLP社区发布论文介绍LIFBENCH基准测试工具评估大语言模型在长文本输入场景下的指令遵循能力和稳定性,揭示现有模型不足,并提出未来研究方向。

阿里巴巴开源超强AI Agent模型Qwen3-Coder,在OpenAI基准测试中得分69.6%,参数量4800亿。它在代码领域表现突出,并且支持256K上下文窗口和大规模强化学习,还提供命令行工具方便使用。

AI玩具退货率高达40%,电商平台七天无理由退货政策加剧问题。产品大多在300-400元价位,依赖平台投流,存在响应延迟、联网困难等问题。多数厂商已线下铺货但销售仍受制约。
随着AI的广泛应用,搜索正在从人类直接使用的产品转变为支持AI运转的信息供给系统。未来,每个软件产品都将配备自己的搜索引擎,以满足不同的需求,如快速搜索和质量要求。
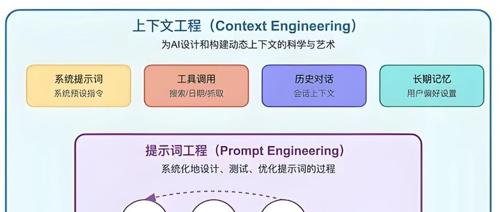
AI 智能体通过上下文工程管理‘心智世界’。它涉及信息选择、组织和注入方式,以及上下文的动态性、可扩展性和准确性,以高效填充LLM的上下文窗口。

Inception Labs发布Mercury模型,采用扩散技术一次性生成代码并纠正错误。它比传统工具快10倍,支持多语言语法树嵌入和双向注意力机制。该模型在线可试用。