



论文标题:
LIFBENCH: Evaluating the Instruction Following Performance and Stability of Large Language Models in Long-Context Scenarios
论文链接:
https://arxiv.org/pdf/2411.07037
一句话总结:
这篇文章介绍了一个名为 LIFBENCH 的基准测试工具,用于评估大语言模型(LLM)在长文本输入场景下的指令遵循能力和稳定性。它还提出了一个配套的评估方法 LIFEVAL,用于自动、准确地评估模型的性能和稳定性。以下是文章的核心内容:
📌 研究背景与动机
背景:随着大语言模型(LLM)在自然语言处理(NLP)任务中的发展,它们在长文本输入下的指令遵循能力变得至关重要。然而,现有的基准测试很少关注长文本场景下的指令遵循能力或模型在不同输入下的稳定性。
动机:为了填补这一空白,作者提出了 LIFBENCH,一个可扩展的基准测试工具,专门用于评估 LLM 在长文本输入下的指令遵循能力和稳定性。
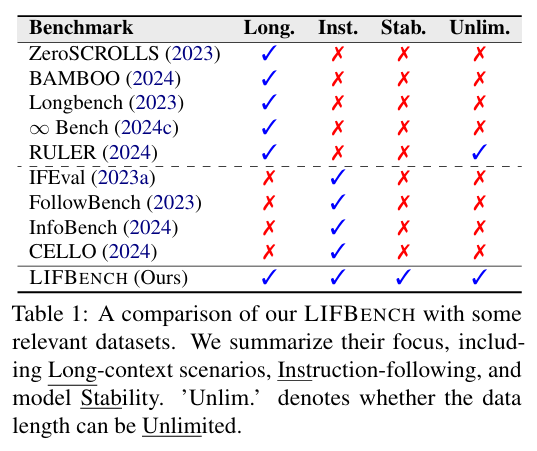
📝 LIFBENCH 基准测试
数据集设计:LIFBENCH 包含三个长文本场景(List、MultiDoc、OneDoc)和十一个不同的任务,涵盖了从列表中检索信息、处理多文档集合以及从单个长文档中提取关键信息等多种任务。这些任务通过自动化扩展方法生成了 2,766 条指令,覆盖了长度、表达方式和变量三个维度。
任务示例:
– List 场景:从长列表中检索特定位置的元素。
– MultiDoc 场景:在多文档集合中找到重复文档或对文档进行分类。
– OneDoc 场景:从单个长文档中提取关键句子或回答问题。
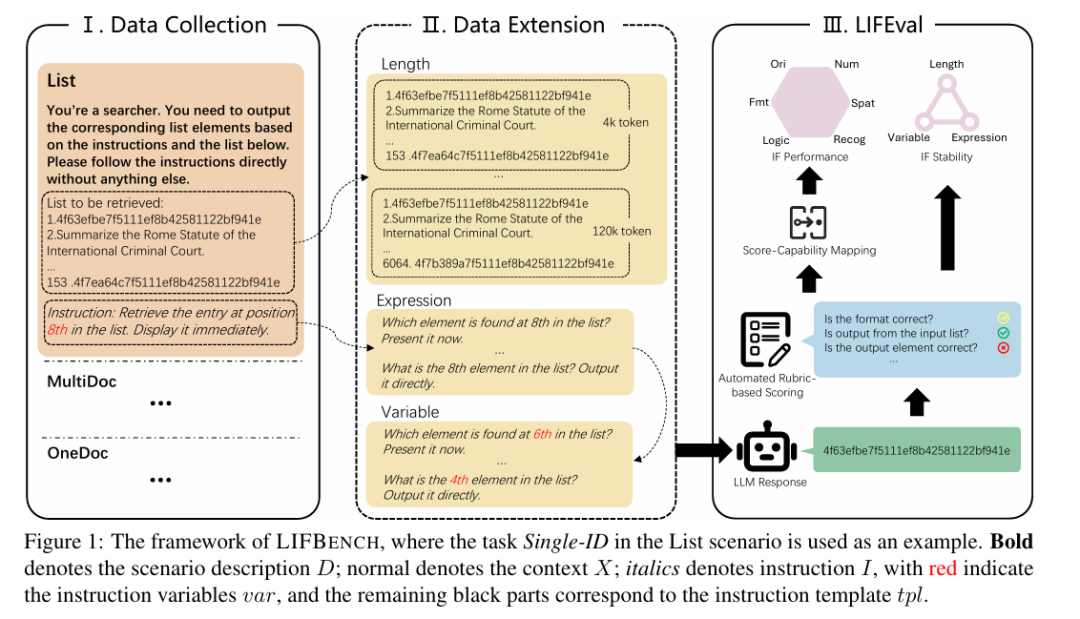
📝 LIFEVAL 评估方法
自动化评分:LIFEVAL 提供了一种基于评分标准的自动化评估方法,能够精确、自动地对复杂 LLM 响应进行评分,无需依赖 LLM 辅助评估或人工判断。
评分标准设计:每个任务都有一个评分标准,根据任务的重要性和复杂性分配权重。评分过程通过自动化程序完成,确保了评分的客观性和一致性。
稳定性评估:通过引入指令遵循稳定性(IFS)指标,从不同角度(如输入长度、表达方式和指令变量)评估模型的稳定性。

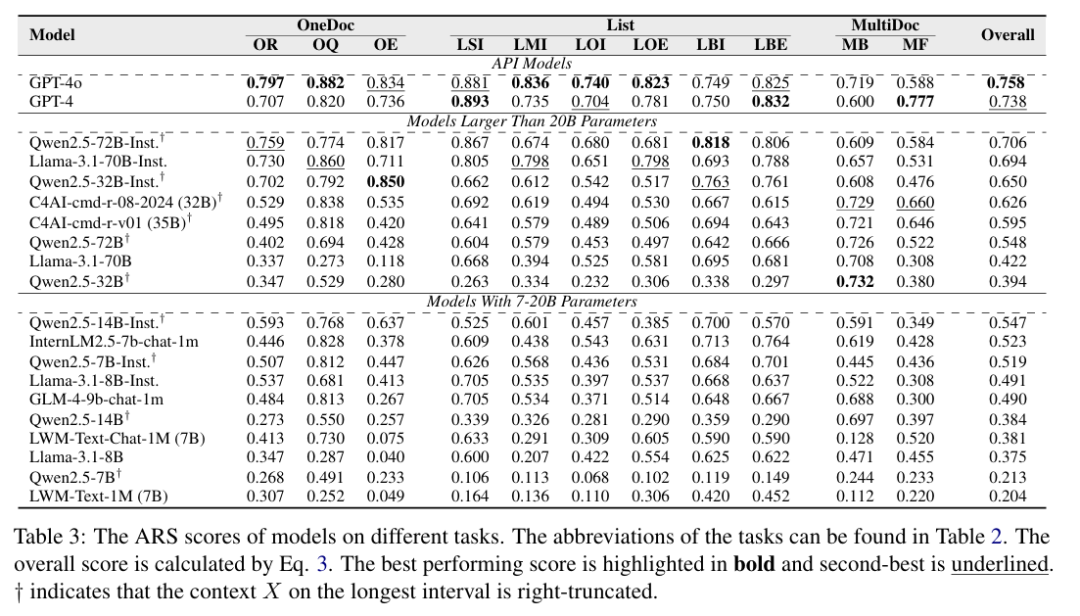
📊 实验结果
模型表现:作者对 20 种知名 LLM 进行了详细实验,包括 GPT-4、Llama、Qwen 等。结果显示,即使是表现最好的模型,其最高得分也只有 0.758,表明在长文本指令遵循方面仍有很大的提升空间。
关键发现:
– 指令微调的重要性:经过指令微调的模型(如 InternLM2.5-7b-chat-1m)表现优于未微调的模型,即使其参数规模较小。
– 模型大小的影响:较大的模型在某些能力(如原始内容处理、数值处理和空间感知)上表现更好,而格式相关的能力则对模型大小的依赖性较小。
– 输入长度的影响:随着输入长度的增加,大多数模型的性能显著下降,尤其是在超过 16k 或 32k token 时。
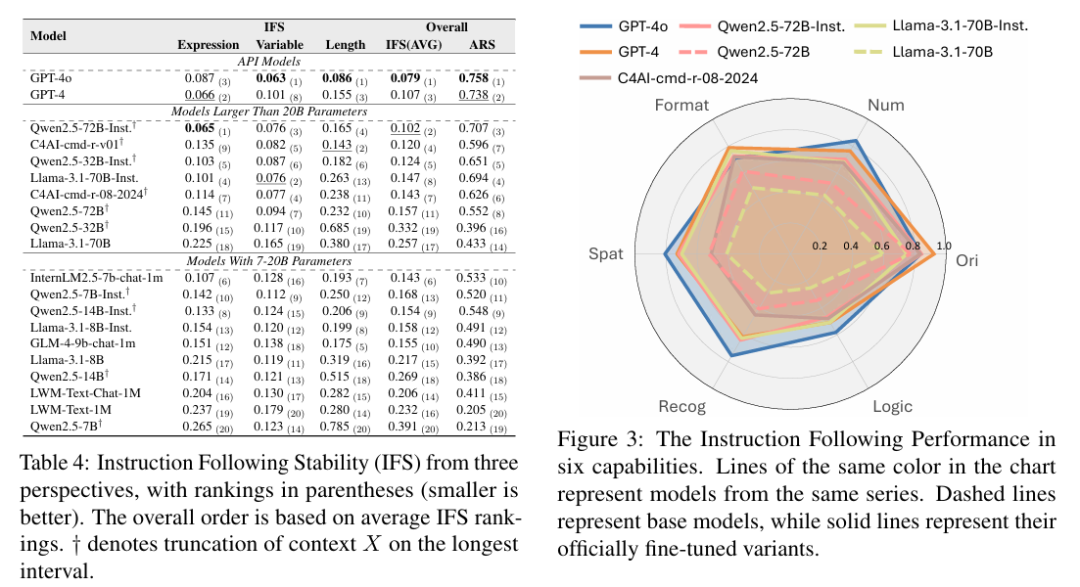
📈 模型稳定性分析
稳定性指标:IFS 指标显示,不同模型在不同输入长度下的稳定性表现各异。例如,GPT-4o 在表达方式上的稳定性较差,而 Llama-3.1-70B-Inst. 在指令变量上的稳定性表现较好。
稳定性与性能的关系:模型的稳定性与其任务完成能力并不总是成正比。例如,Qwen2.5-72B-Inst. 在某些情况下表现出比 GPT-4 更高的稳定性,尽管其整体性能略低。
📝 结论与展望
结论:LIFBENCH 和 LIFEVAL 为评估 LLM 在长文本输入下的指令遵循能力和稳定性提供了强大的工具。实验结果揭示了现有模型在长文本场景下的不足,为未来 LLM 的发展提供了宝贵的见解。
展望:作者指出,尽管 LIFBENCH 已经取得了一定的成果,但仍存在一些局限性,如对语义约束的支持不足、数据集规模有限等。他们鼓励社区使用提出的协议扩展评估集,并进行更广泛的分析。
📌 一句话总结
LIFBENCH 和 LIFEVAL 为评估大语言模型在长文本输入下的指令遵循能力和稳定性提供了一种系统化的方法,揭示了现有模型在长文本场景下的不足,并为未来的研究提供了方向。
(文:机器学习算法与自然语言处理)