
日期: 2025 年 7 月 23 日

Jailbreak迎来“最后一卷”?港科大用“内容评分”重塑大模型越狱评估范式

港科大团队提出GuidedBench评估框架,系统评估LLM越狱攻击方法,并使用该框架对10种主流Jailbreak方法在5个主流模型上的成功率进行评估,结果发现没有一种方法的攻击成功率超过30%。
Qwen3 新模型 Coder:性能、价格、可用性|全详解,包括官方没说的
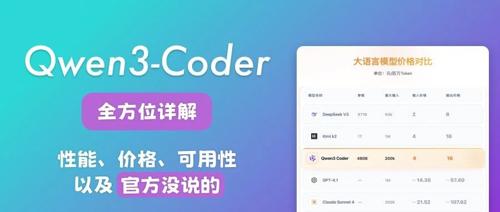
今天凌晨Qwen3-Coder发布最强代码模型,采用MoE架构,开源480B大小。性能上胜过Claude Sonnet4,价格图表对比明确,API及开发方式详述,还有自部署、CLI工具和调用示例等全面信息。
国产AI音乐王炸!Mureka V7 品质飞跃+TTS V1 打字造声音,网友:继 O1 超越 Suno 后再放大招!
Mureka V6
:引入 ICL 技术,带来更开阔的声场,强化了人声质感和混音设计。
首款音乐推理
多模态大模型在OCR生成上表现如何?多页文档理解数据集Doc-750K

2025年7月23日,北京晴。文章介绍了多模态大模型在OCR生成任务和长文档问答数据集方面的进展。前者评估了最新多模态模型在多种OCR生成任务上的表现;后者则针对多页理解问题,通过开源数据集Doc-750K研究提升模型处理复杂文档的能力。

阿里本周将发布首款自研AI眼镜,加入“百镜大战”丨智能涌现独家

阿里巴巴将发布首款自研AI眼镜,融合高德、支付宝等生态功能,计划在今年推出。这款产品将在硬件和软件上超越现有竞品,有望通过整合阿里内部多个业务单元的优势打破市场瓶颈。
保姆级教程:两步搭出Qwen3 Coder满血Claude Code版,OpenAI CodeX睡桥洞去吧

Qwen团队发布了新的Qwen3-Coder模型,参数480B,激活参数35B。该模型在Claude Code对话时表现优秀,并且可以接入多个平台使用。作者提供了详细的教程指南来帮助用户将Qwen3 Coder接入Claude Code、Gemini CLI以及Cline等工具。