


总述
最近阅读了
@kaitoukito
本文基于Compute Capability 8.9的L20 GPU进行实验。CUDA Toolkit版本为12.2。
问题一:STG指令是否仍然Bypass L1缓存?
在大佬的文章中的结论部分提出了一个猜想:在较新的架构中 __stcg、__stwb、__stwt均可能命中 L1 Cache Line,而非简单的bypass L1 Cache。我们基于代码和Nsight Compute(ncu) Profile对这个猜想进行验证:
static const int _warpSize = 32;__global__ void cacheKernel(int* array_ptr) {int* thdPtr = array_ptr + threadIdx.x;int x = __ldca(thdPtr); // First Load, L1 Cache Miss, Load a cache line into L1__stwb(thdPtr, x + threadIdx.x);int complement_tid = _warpSize - 1 - threadIdx.x;int* complementPtr = array_ptr + complement_tid;int _x = __ldca(complementPtr); // If last STG evict cache line, this load will missing__stwb(thdPtr, _x + threadIdx.x);}int main(void) {// ...dim3 grid(1, 1, 1);dim3 block(_warpSize, 1, 1);cacheKernel<<<grid, block>>>(_dev);// ...}
我们启动一个非常简单的CUDA Kernel,这个Kernel里仅包含一个线程束(warp)。当这个Kernel开始执行时,唯一的一个Thread Block(仅仅包含一个warp)被调度到一个SM上,它首先加载一个Cache Line(32 * 4 = 128 byte)到SM的L1缓存中,然后执行STG指令修改这128Byte的内容,如果STG指令Bypass了L1,那么它需要先evict L1 Cache中原来的Cache Line,然后将结果写到所有SM共享的L2 Cache中去。那么,再次执行加载动作加载同样的位置时,仍然会发生一次L1 Cache Miss,读操作的L1缓存的命中率应该为0。
但实际的执行结果并不是这样,我们通过ncu对这个Kernel进行Profile发现,无论是__stwb,还是__stcg、__stwt ,两次加载指令的L1 Cache Hit Rate均为50%,如图1所示:
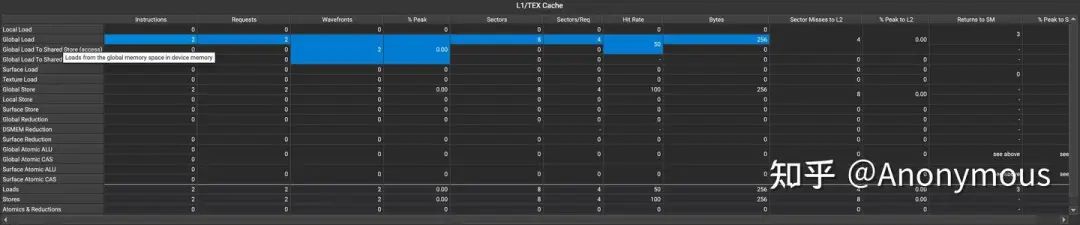
也就是说,第二次加载时一定命中了L1 Cache——这说明上一步STG指令并未evict L1 Cache Line。相反,它命中了L1 Cache,并且对L1 Cache做了修改。
由此我们可以提出几个问题:
-
L1缓存是每一个SM私有的,在执行写操作的时候,多个SM有可能需要写同一个Cache Line,那么,这就涉及到一致性问题,多个SM的L1缓存之间是否保持了一致性(Coherent)呢? -
写操作命中L1缓存后,行为是Write Back还是Write Through?如果是Write Back,那么现代GPU微架构需要还需要额外支持缓存的dirty位。 -
写操作如果没有命中L1缓存,其后续的行为是什么?是直接Write Through写到L2缓存,还是先做Write Allocate,然后像命中L1 Cache一样执行Write Back或Write Through?
针对这几个问题,我们进行进一步的探究。
问题二:L1缓存之间是否保持了一致性(Coherent)?
我们通过如下代码验证这个问题:
static const int _warpSize = 32;static const int _pageSize = 4096;__device__ uint get_smid(void) {uint ret;asm("mov.u32 %0, %smid;" : "=r"(ret));return ret;}__global__ void cacheKernel(int* array_ptr, int* locked, int* result_ptr) {int* thdPtr = array_ptr + threadIdx.x;if (blockIdx.x == 0) {int x = __ldca(thdPtr); // Load cache line to SM0's L1 Cacheif (threadIdx.x == 0) {// *locked == 0: set *locked to 2 and return 0// *locked != 0: return *locked and condition True, execute while loopwhile (atomicCAS(locked, 0, 2) != 0);}__syncthreads();__stwb(thdPtr, x + threadIdx.x); // Flush to L2 Cache?__threadfence(); // Memory Barrier to force order: st -> atom.exchatomicExch(locked, 1); // set *locked to 1} else if (blockIdx.x == 1) {int x = __ldca(thdPtr); // Load cache line to SM1's L1 Cacheif (threadIdx.x == 0) {// *locked == 1: set *locked to 2 and return 1// *locked != 1: return *locked and condition True, execute while loopwhile (atomicCAS(locked, 1, 2) != 1);}__syncthreads();int _x = __ldca(thdPtr); // Load from L1// int _x = __ldcg(thdPtr); // Load from L2result_ptr[threadIdx.x] = x;result_ptr[threadIdx.x + _warpSize] = _x;}if (threadIdx.x == 0) {printf("Block %d on SM %u\n", blockIdx.x, get_smid());}}int main(void) {// ...int* _lock;cudaMalloc((void**)&_lock, _pageSize);cudaMemset(_lock, 0, _pageSize);dim3 grid(2, 1, 1);dim3 block(_warpSize, 1, 1);cacheKernel<<<grid, block>>>(_dev, _lock, _res);// ...}
这一次,我们启动两个ThreadBlock,每一个ThreadBlock仍然只包含一个warp,我们进一步通过CAS原语强制两个ThreadBlock的执行顺序,程序的执行逻辑大致如下:
-
ThreadBlock 0(TB0)和ThreadBlock 1(TB1)被调度到不同的SM上执行,TB0和TB1以一个随机的顺序将同一个Cache Line读取到各自SM的L1 Cache中(在MESI缓存一致性协议中,这叫做Shared State)。随后,TB0执行CAS操作成功,继续向下执行,TB1执行CAS操作失败,被阻塞。 -
TB0执行STG,修改Cache Line的内容。 -
TB0将lock变量置为1,此时TB1便能够解除阻塞状态,继续执行。 -
TB1再次读取Cache Line中的内容。
假设不同SM的L1 Cache之间保持了一致性,那么第2步中TB0执行写操作时,TB1中的Cache Line会变为Invalid,TB1在第4步中的读取不会命中L1 Cache,而是从TB0的L1 Cache(或Global L2 Cache)中获取更新后的值。
我们运行程序,并将__stwb依次替换为__stcg、__stwt进行实验,所有的实验结果竟然出奇的一致:
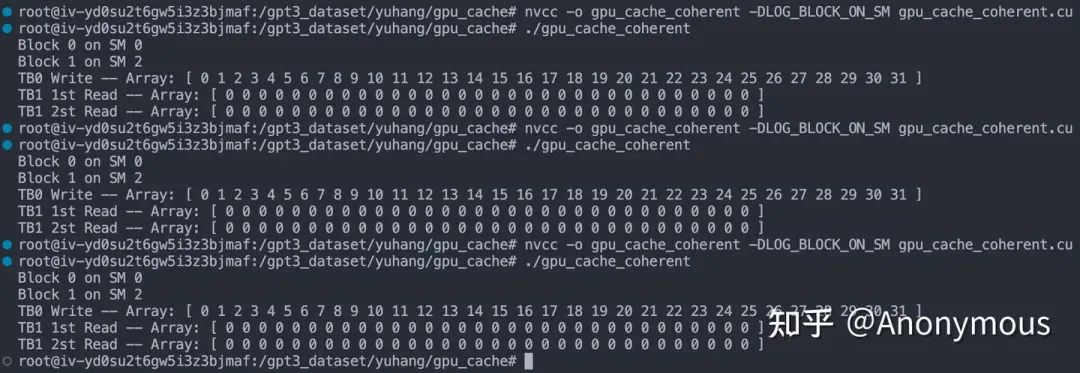
如图2所示,无论使用哪一种STG指令,TB1都不会读取到TB0更新后的值,也就是说,各个SM的L1 Cache之间,并不具有一致性,这与早期的GPU微架构的行为是一致的,这是一种设计上的权衡,由于GPU的SM数量众多,维护一致性的成本非常高昂。
问题三:STG命中L1缓存后,行为是Write Back还是Write Through?
修改上一段代码逻辑,让TB1在TB0执行STG指令后,直接从L2 Cache中读数据:
static const int _warpSize = 32;static const int _pageSize = 4096;__device__ uint get_smid(void) {uint ret;asm("mov.u32 %0, %smid;" : "=r"(ret));return ret;}__global__ void cacheKernel(int* array_ptr, int* locked, int* result_ptr) {int* thdPtr = array_ptr + threadIdx.x;if (blockIdx.x == 0) {int x = __ldca(thdPtr); // Load cache line to SM0's L1 Cacheif (threadIdx.x == 0) {// *locked == 0: set *locked to 2 and return 0// *locked != 0: return *locked and condition True, execute while loopwhile (atomicCAS(locked, 0, 2) != 0);}__syncthreads();__stwb(thdPtr, x + threadIdx.x); // Flush to L2 Cache?__threadfence(); // Memory Barrier to force order: st -> atom.exchatomicExch(locked, 1); // set *locked to 1} else if (blockIdx.x == 1) {if (threadIdx.x == 0) {// *locked == 1: set *locked to 2 and return 1// *locked != 1: return *locked and condition True, execute while loopwhile (atomicCAS(locked, 1, 2) != 1);}__syncthreads();int _x = __ldcg(thdPtr); // Load from L2result_ptr[threadIdx.x + _warpSize] = _x;}if (threadIdx.x == 0) {printf("Block %d on SM %u\n", blockIdx.x, get_smid());}}int main(void) {// ...int* _lock;cudaMalloc((void**)&_lock, _pageSize);cudaMemset(_lock, 0, _pageSize);dim3 grid(2, 1, 1);dim3 block(_warpSize, 1, 1);cacheKernel<<<grid, block>>>(_dev, _lock, _res);// ...}
如果是Write Back,L2 Cache中保存的应该是旧值,而Write Through会将修改进一步更新到L2 Cache,读取L2 Cache时我们获得的是新值。控制TB1直接从L2 Cache中读取这个Cache Line(实验进行了3次分别是__stwb、__stcg、__stwt的结果):
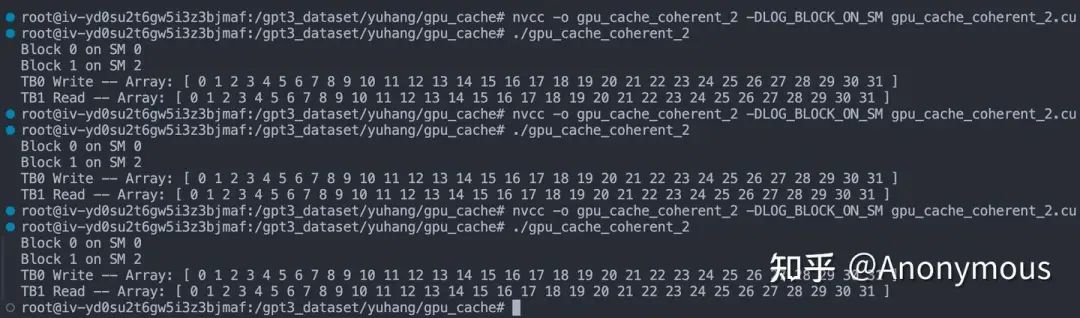
可以观察到,TB1读取的是更新后的值——STG命中L1 Cache后执行Write Through。
问题四:未命中L1时是否会发生Write Allocate?
我们通过如下代码来验证这个问题:
static const int _warpSize = 32;__global__ void cacheKernel(int* array_ptr) {int* thdPtr = array_ptr + threadIdx.x;__stwb(thdPtr, threadIdx.x);int complement_tid = _warpSize - 1 - threadIdx.x;int* complementPtr = array_ptr + complement_tid;int _x = __ldca(complementPtr);__stwb(thdPtr, _x + threadIdx.x);}int main(void) {// ...dim3 grid(1, 1, 1);dim3 block(_warpSize, 1, 1);cacheKernel<<<grid, block>>>(_dev);// ...}
这次,我们启动一个ThreadBlock,这个TB仅包含一个warp,它先执行一次STG操作,这次STG操作一定不会命中L1 Cache,如果未命中时发生了Allocate,那么下一次__ldca读取同样的位置时就会命中L1 Cache,反之则不会命中。通过ncu进行Profile,可以观察到L1 Cache的命中率为100%,使用三种STG指令能够得到完全一样的结果:
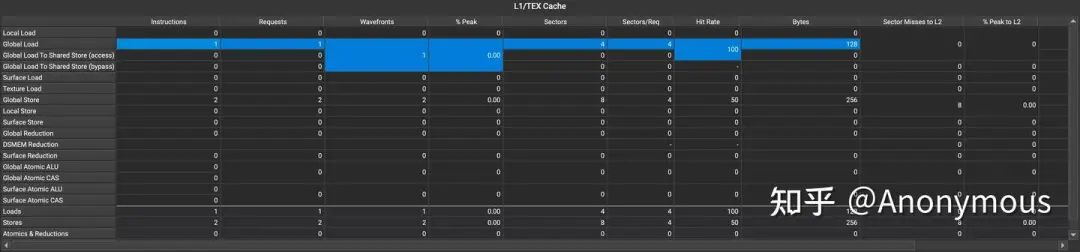
因此,我们可以断定:写操作未命中L1时,会先触发Write Allocate,然后照常执行Write Through。
结论
现代GPU微架构中的STG指令Cache Operator的行为可总结为:
-
命中L1 Cache时,执行Write Through。 -
未命中L1 Cache时,先执行Write Allocate,再执行Write Through。
此外,SM的L1 Cache之间并不具备一致性。但从单个SM的角度来说,其L1和L2 Cache之间是具备一致性的,不会出现dirty的现象,这是通过Write Through实现的,因此我们推测,现代GPU微架构可能还未支持缓存的dirty位。
遗留问题
-
目前并未发现__stwb、__stcg、__stwt三种Cache Operator在执行Global Store时的差异。在Local Store是否会有差异呢? -
由于L1 Cache并不具备一致性,那么类似于内存屏障的__threadfence()函数的具体作用又是什么呢?——保证SM Core对Memory的操作在L2 Cache/Global Memory上的顺序。 -
新版本的ncu中集成了C2C Profile的相关功能,C2C在传统的CPU微架构中用于分析缓存行竞争,这与缓存一致性有一定的关联,在ncu中,Compute Capalibity 9.0以上的Device才支持这种Profile,那么CC 9.0以上的设备是否支持全局或局部的一致性呢?——Compute Capalibity 9.0上的C2C指的是Chip to Chip,与Grace Hopper相关,与缓存无关。
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)