
国内首个音乐 ChatGPT,Mureka再次迎来大升级。
Mureka 原有版本:
基座模型 Mureka V6:引入 ICL 技术,带来更开阔的声场,强化了人声质感和混音设计。
首款音乐推理大模型 Mureka O1:具备音乐思考能力,音乐结构更加连贯,乐器编排更加精准。
Mureka O1 发布后,更是一举超越 Suno,登顶全球音乐大模型 TOP 1。
而这次的Mureka V7,更强大、更完美:
-
音乐品质更好:旋律动机和编曲质量大幅提升,人声和乐器的真实感更强,做出来的每一首歌都好听。
-
音乐创新性更强:生成的作品对音乐从业者更具启发和创意
多种模型 自由创作
在模型界面,用户可以选择Mureka O1、Mureka V6和Mureka V7多个模型进行创作。
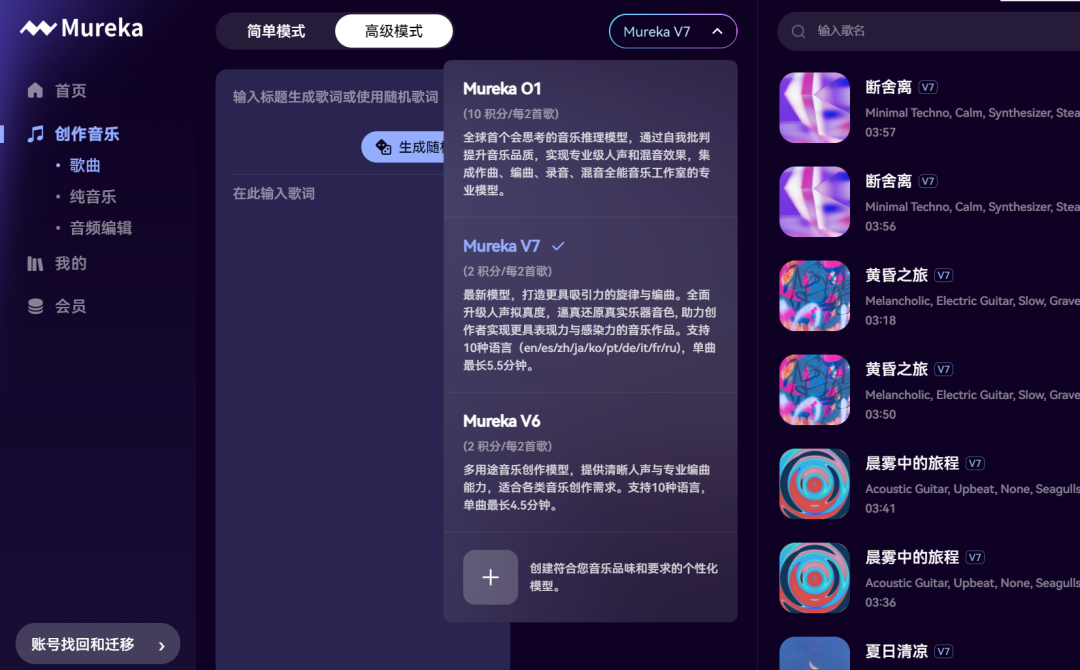
可以直接通过Mureka的网页端体验Mureka V7:
www.mureka.cn
打开Mureka官网,可以直接到达创作页面。歌曲创作有简单模式和高级模式。高级模式下,输入你想创作的歌曲名称,可以直接让AI生成相应的歌词。
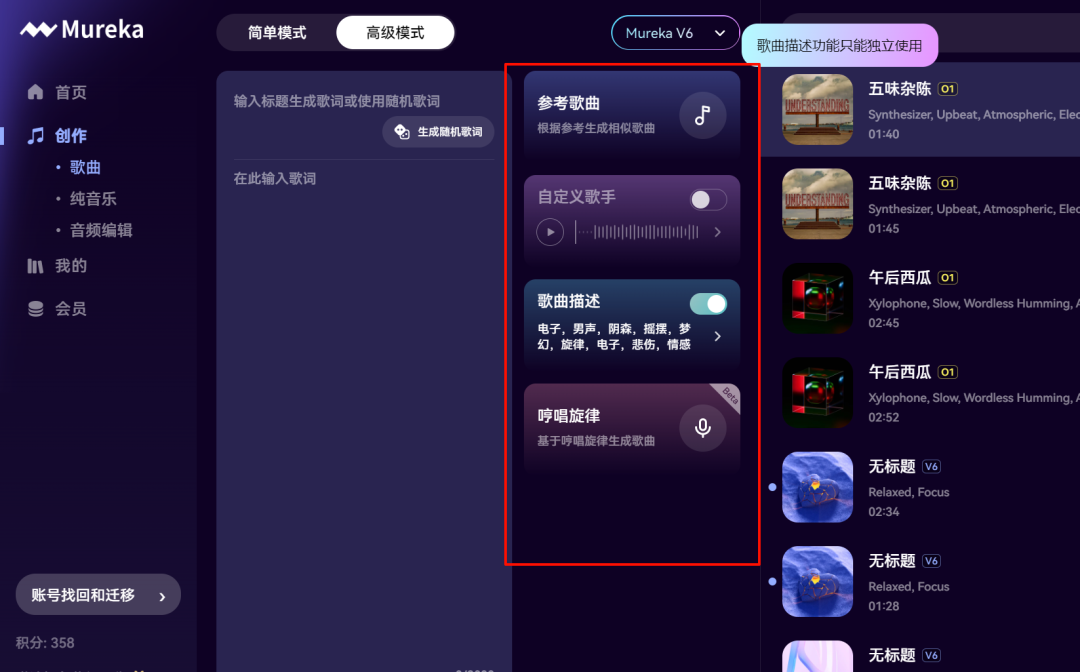
MurekaV7:创作一首【中国古风与Lo-Fi Hip Hop】融合的音乐。保留古筝和笛子作为主旋律乐器,但配上慵懒、舒缓的Lo-Fi鼓点和温暖的黑胶唱片底噪。前奏笛声一起,鸡皮疙瘩都出来了。
官方还提供了许多v7生成的有意思的例子:
-
倾诉衷肠的叙事型乡村音乐
-
婉约凄美的中国风歌曲
-
展现童趣的欢快儿歌
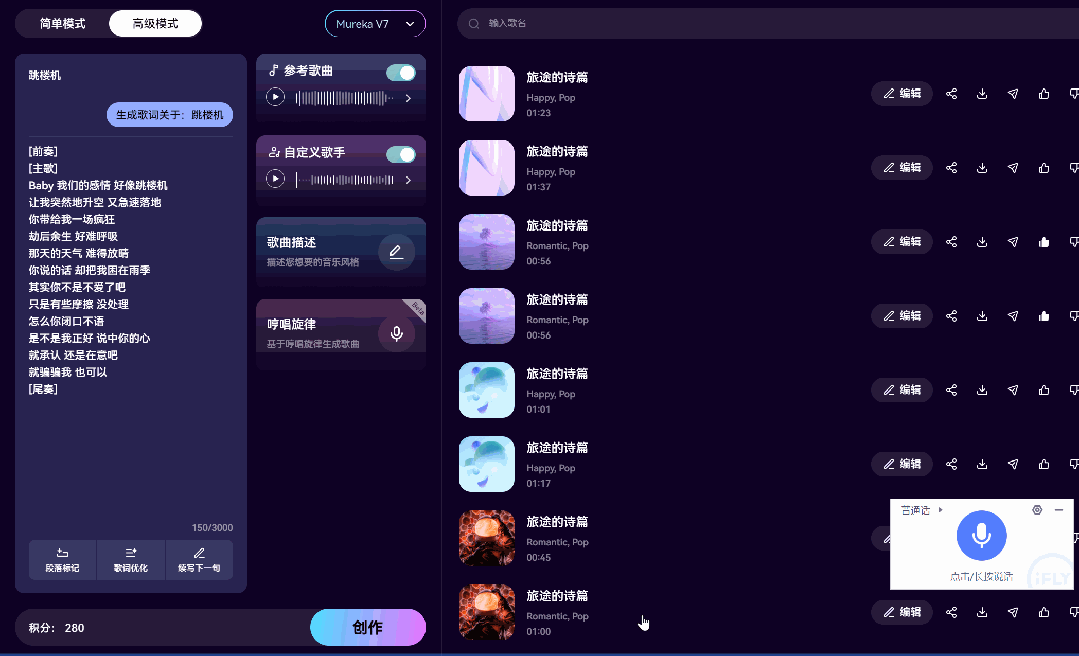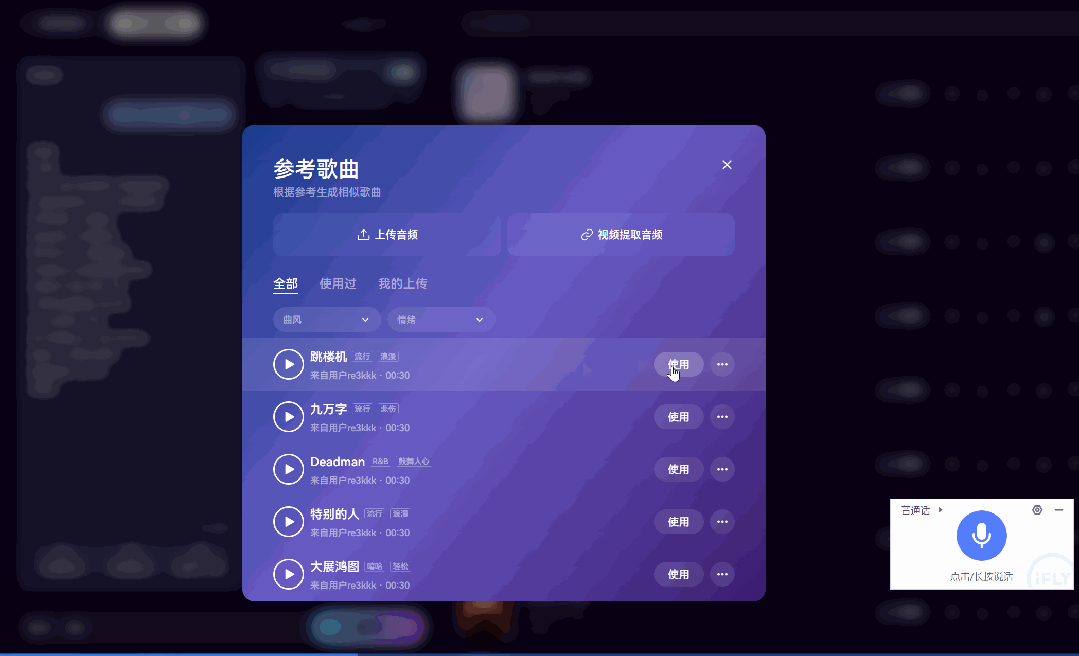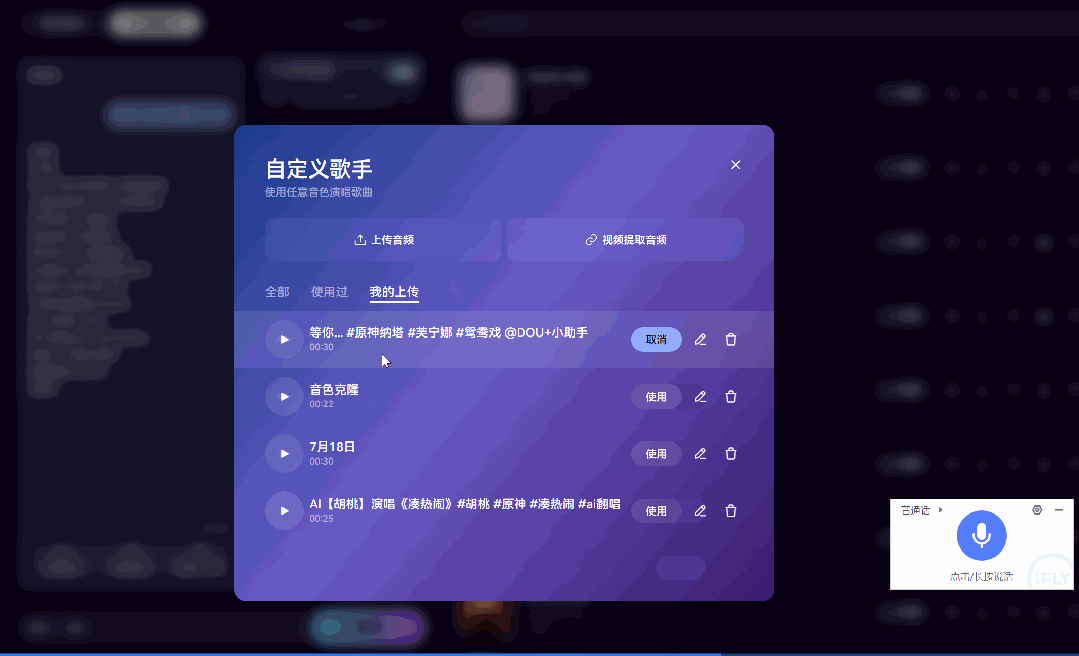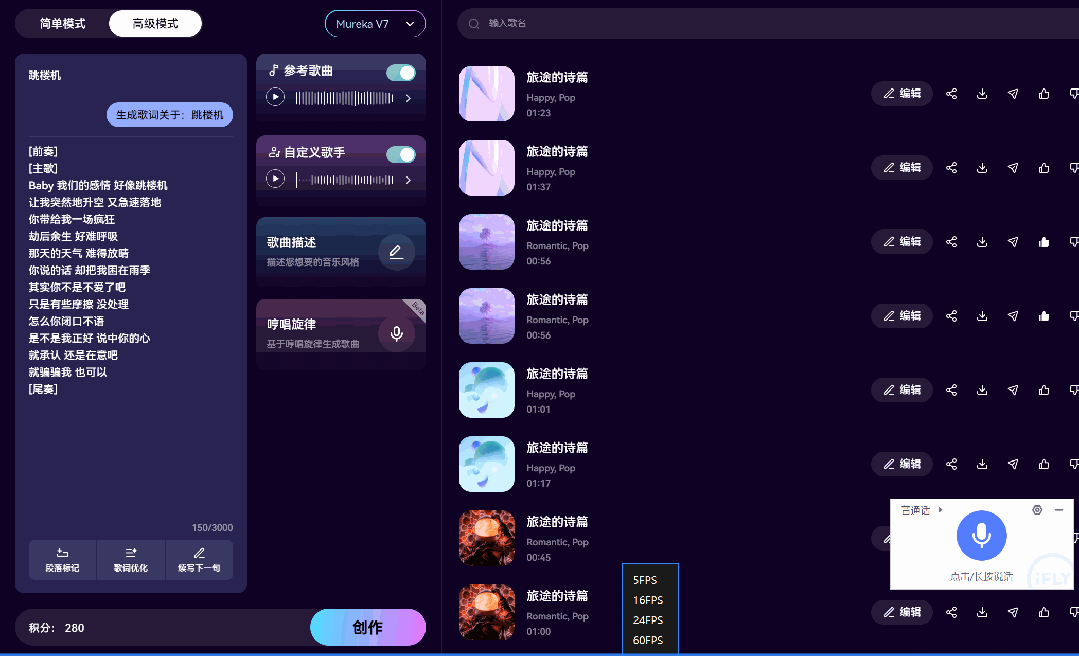
以上是直接提示生成音乐。但Mureka 还有参考歌曲功能:
你可以上传一首参考歌曲,或者直接粘贴抖音链接,Mureka V7 就能基于你提供的音乐风格、节奏、情绪,定向生成与之呼应的新作品。
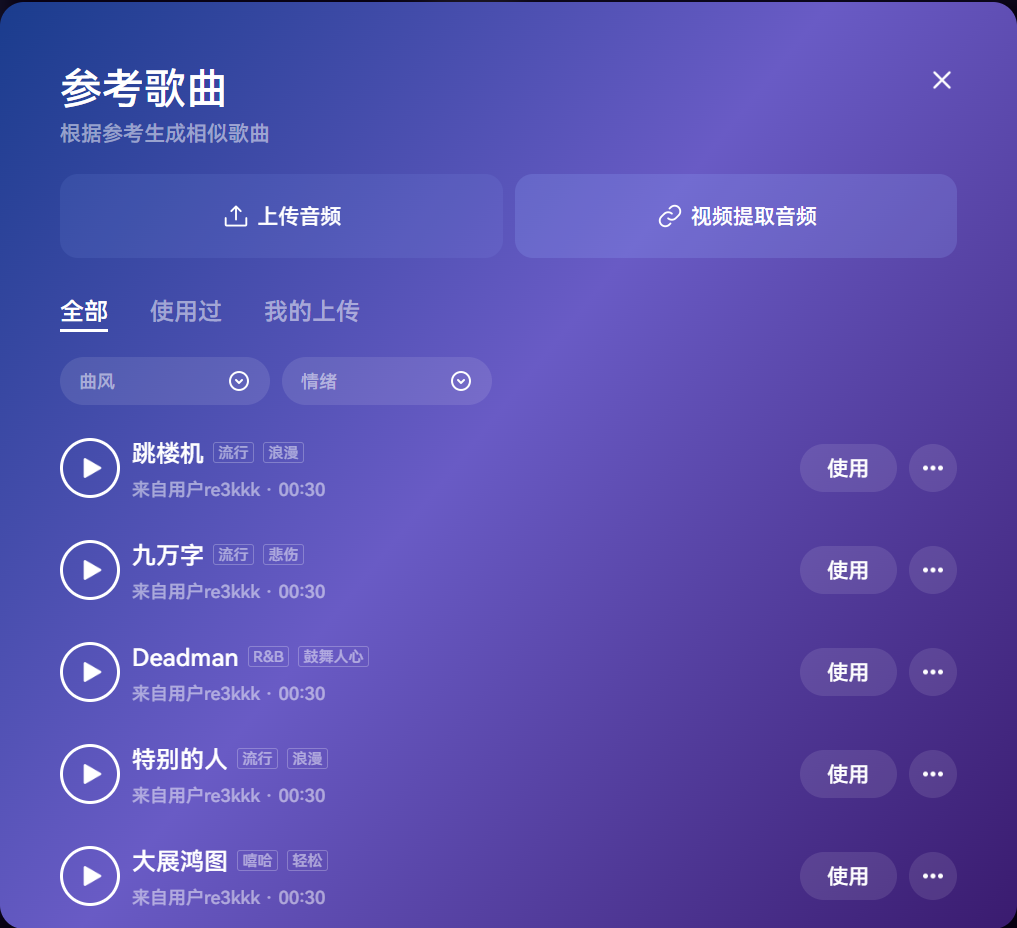

它内置的「音乐参考(Reference)」功能,会自动识别上传音乐的类型、节奏、配器和情感氛围,确保生成的作品在美学风格上保持一致性。
更厉害的是,Mureka 还是全球首个支持自定义音色的 AI 音乐平台。
不仅能选择歌手音色,甚至可以上传自己的声音,让 AI 为你“定制演唱”。
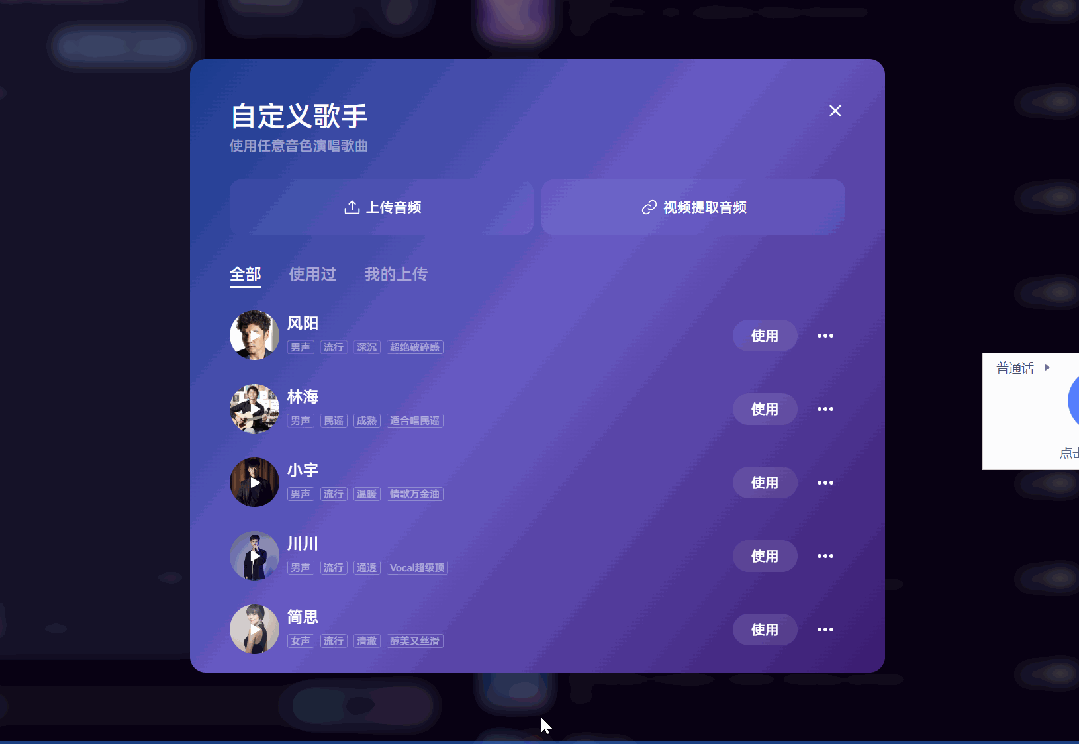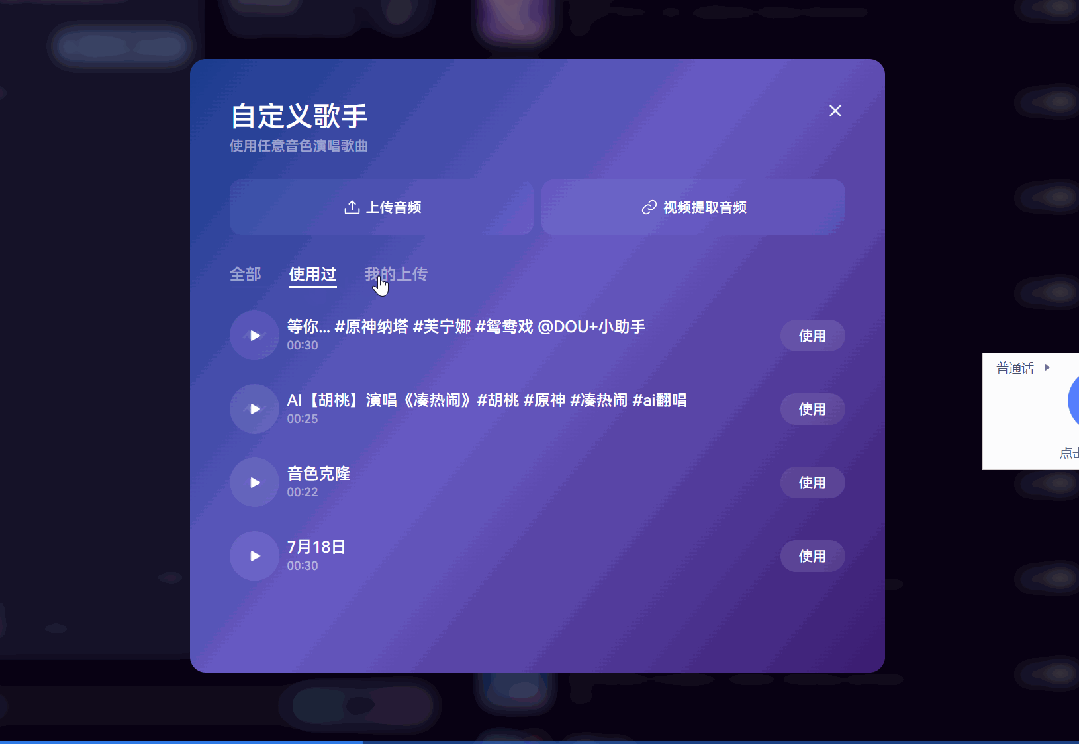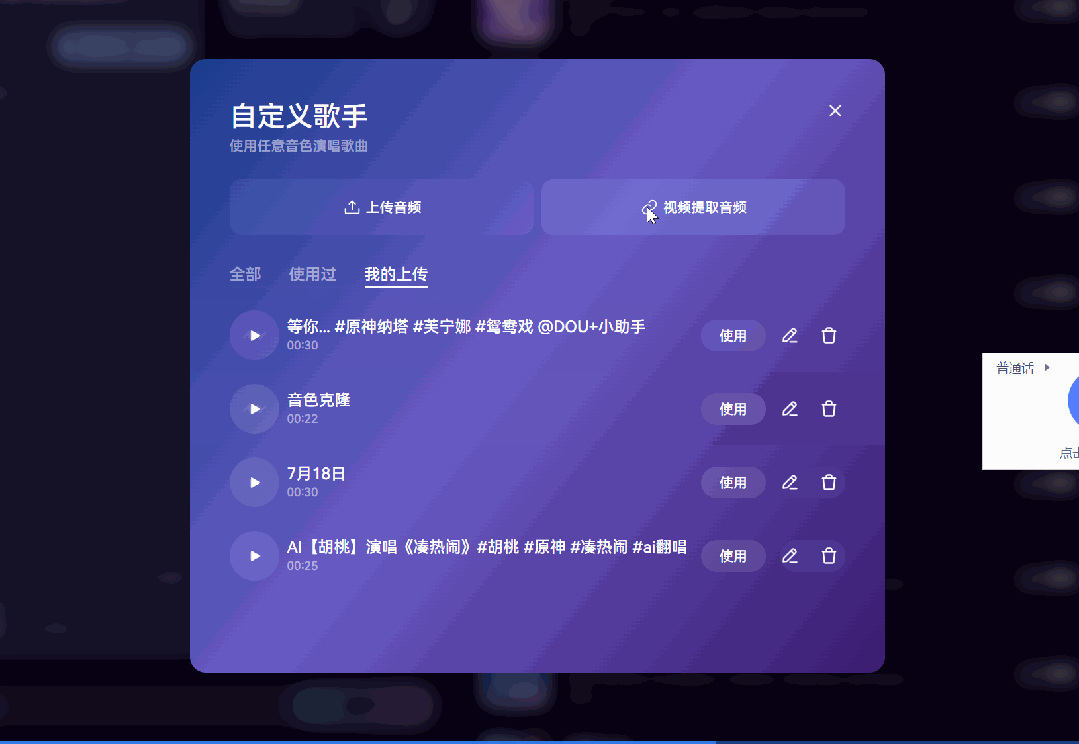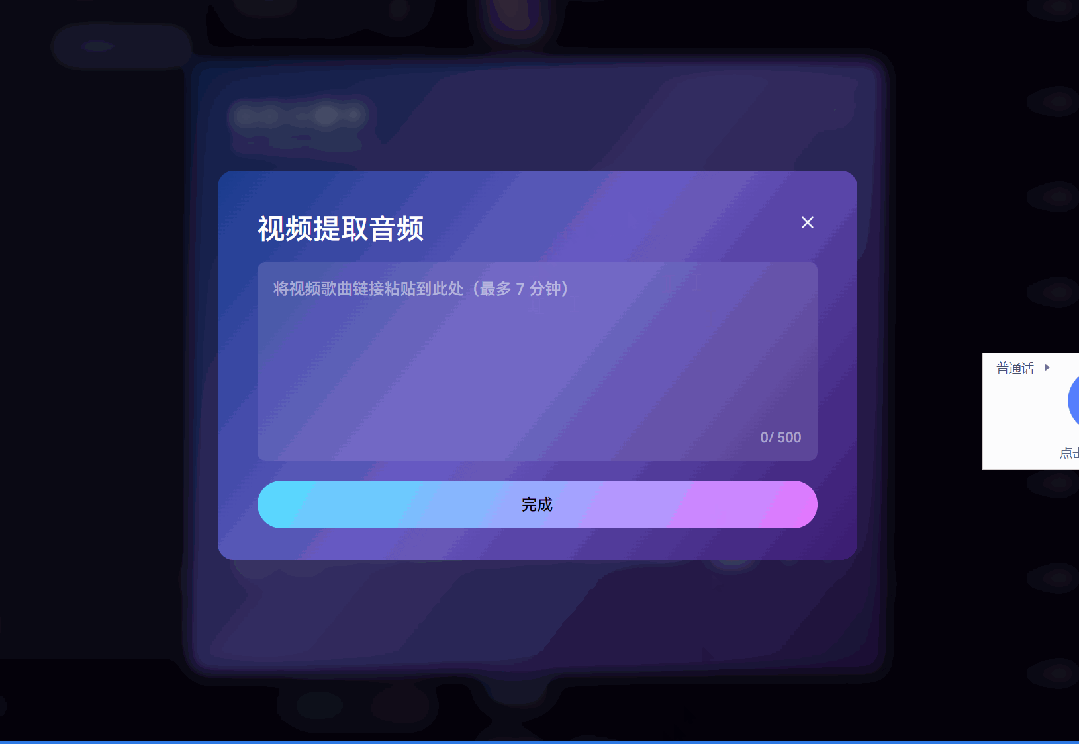
我自己试的时候,用《琵琶行》作为参考歌曲,选了一个二次元角色的音色:原神 · 芙宁娜,让它唱《将进酒》。

选好后,把歌词贴在左侧输入框就可以开始生成了。
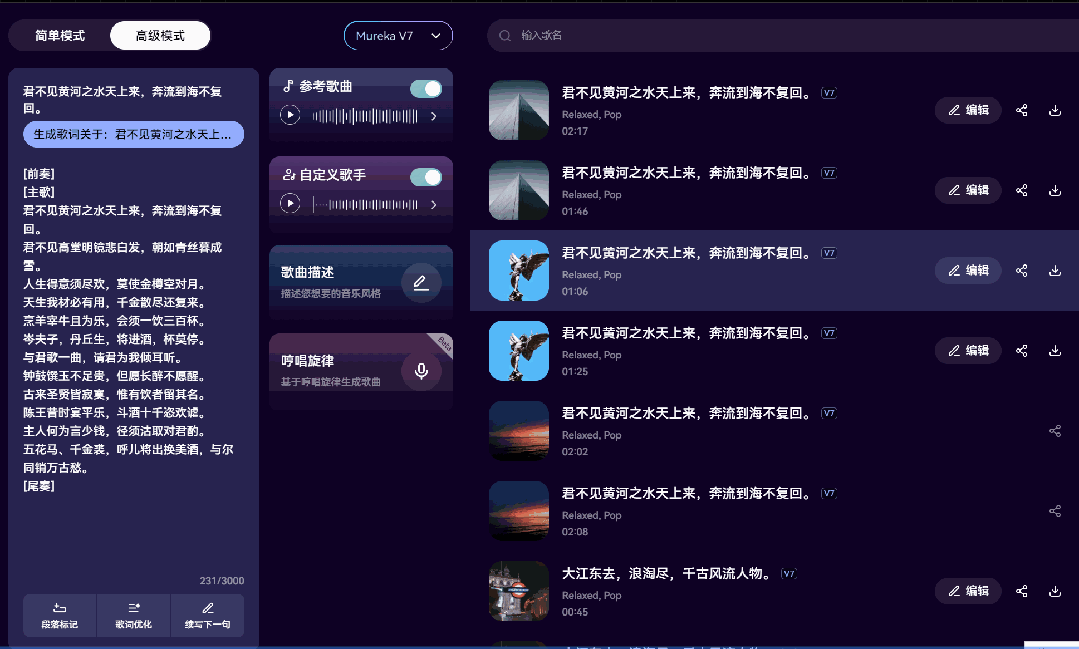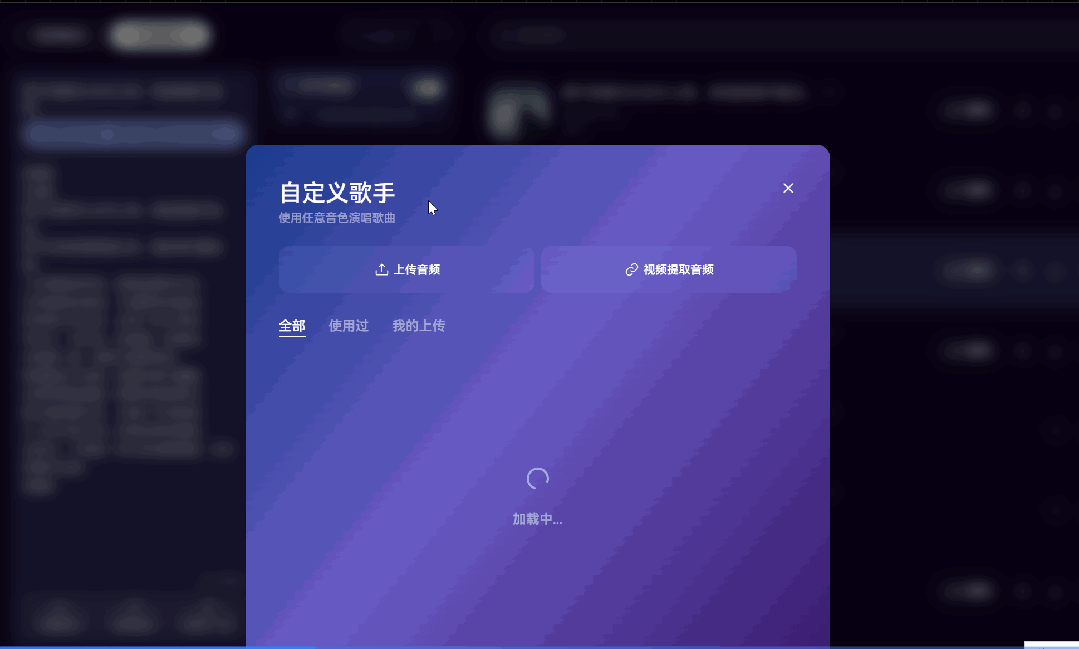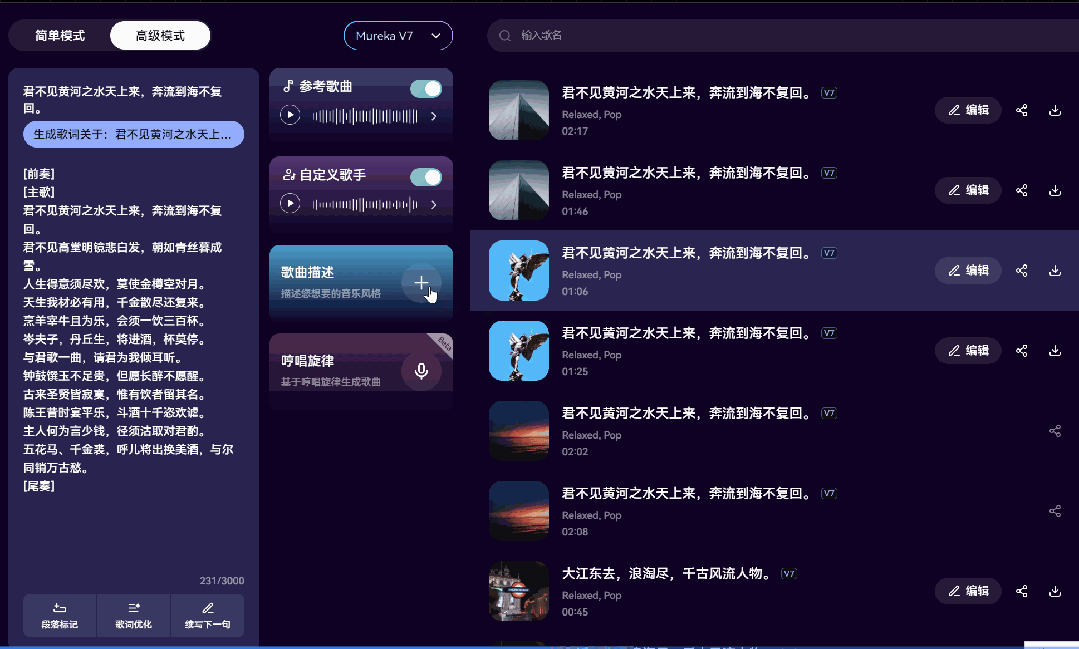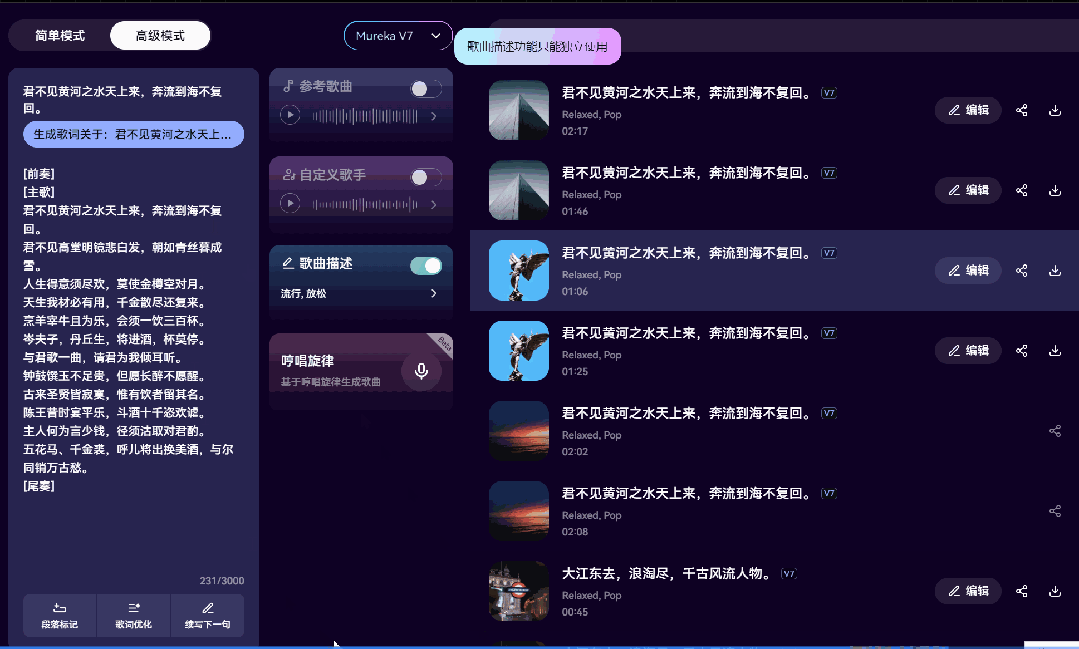
这次用的参考音色是一个 AI 合成的二次元声线,再被 Mureka 克隆并演唱,虽然自然度上稍逊原生音色,但它的好处在于“可控” —— 你可以听到自己想听的声音,不再被预设所限制:
如果不加参考音色,AI 的表现更稳定,流畅度更好,说实话,搞得还挺抽象:
不过将诗词与音乐结合,也是 不断扩展艺术边界,诗与乐相和,古诗词在 AI 的赋能下,完成了多样的艺术表达。
而上面这个视频也是用 Mureka 生成的。
每次生成,它都会给出两首不同风格的版本供你选择。
歌曲生成后,你不仅可以一键发布、分享链接,还能让 AI 根据歌词自动生成一段匹配的动态视频。
在别人还在用千篇一律的 BGM 发短视频时,
用上 Mureka V7,每一个想被记录的瞬间,都能拥有一首专属的旋律,甚至一段专属的画面。
又或者整一首《跳楼机》风格的伤感现代曲,也别有味道。

继续,下面这个纯音乐生成功能就很有用了。我自己用的贼欢。
纯音乐生成功能:
Mureka V7 不仅支持通过文字 prompt 生成免版权的纯音乐,还可以上传参考音乐,自动生成类似风格的纯音乐。操作简单高效,一个链接就能复制同款音乐,非常适合用于 vlog、影视制作等。
想用 AI 博主 @赛文乔 一的背景音乐?没问题!只需将其背景音乐提取出来,自己定制生成一首原创音乐,避免了内容同质化问题。
Mureka V7 生成的BGM:
操作非常简单,只有三步,甚至连提示词都不用填,Mureka 就能自动生成相同风格的 BGM。
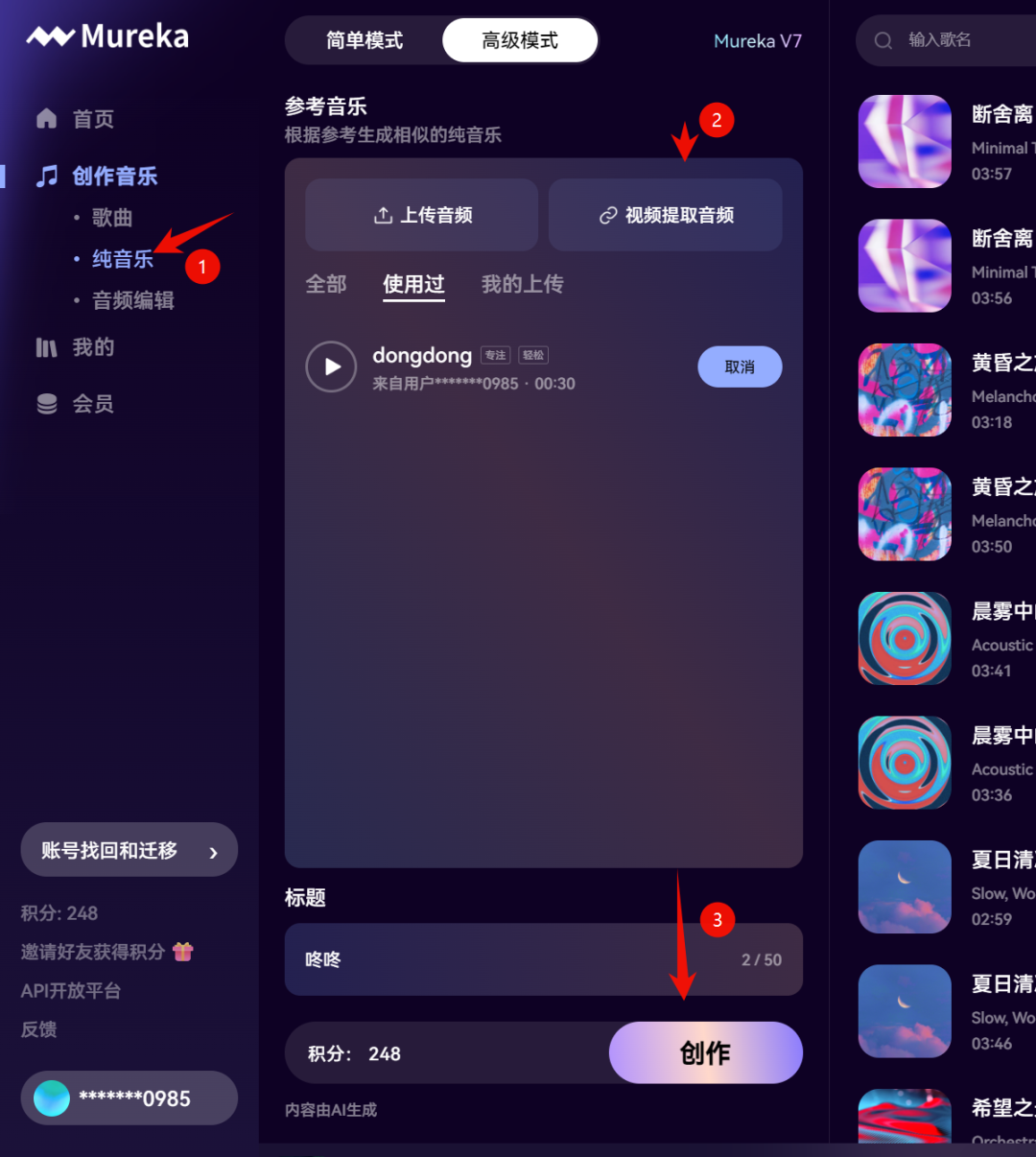
这玩意儿我都搞了好几种BGM了。生成的效果都挺棒。 做视频的时候可以用上。
Mureka 的纯音乐生成功能在Vlog、电影、广播、广告、品牌推广、活动等多个领域都能发挥巨大作用。你可以为每个项目量身定制音乐,创造符合气氛和情感的作品。
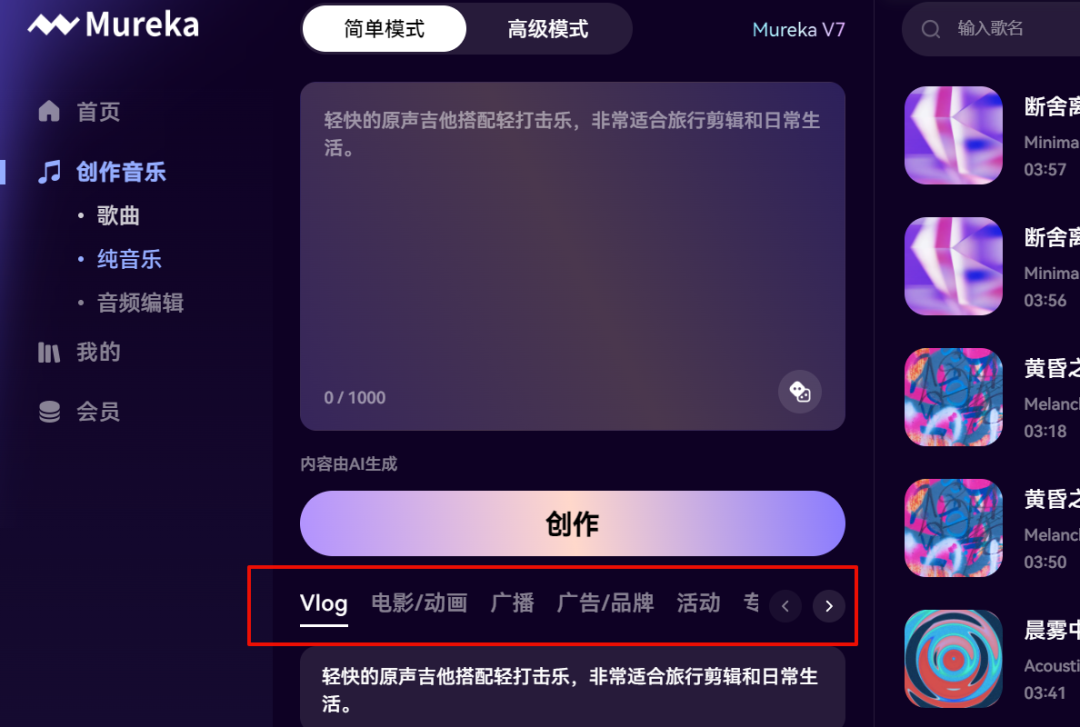
例如:为一个高端护肤品牌创作广告配乐:
提示词:为一个高端护肤品牌创作广告配乐。需要极简、优雅、富有高级感的音乐。以舒缓的钢琴分解和弦和温暖的弦乐为主,节奏从容。重点是,结尾需要一个时长3秒、由几个清脆音符组成的、清晰独特的“声音Logo”,用于产品特写镜头。-
赛博朋克雨夜的追逐场景:
一首为赛博朋克雨夜追逐场景设计的纯音乐。需要冰冷、迷幻的合成器浪潮(Synthwave)风格,以强劲的复古鼓机节拍为驱动,融合一段空灵、忧郁的萨克斯独奏,整体感觉像是既在逃离,又在追寻。
傍晚驾驶美国66号公路的心情:
傍晚时分,独自驾驶一辆老式皮卡,穿越美国66号公路…
清晨,开着车驶入一座雾气缭绕的沿海小镇。一首轻快、清新的独立民谣(Indie Folk),以原声吉他和悠扬的口哨声为主,伴有海鸥和海浪的细微环境音,感觉像电影的开场。
二次创作与歌曲延长
Mureka生成的音乐并不是“一次性”的,你可以对其中的任意片段进行二次创作,实现 AIGC 音乐的“可编辑性”。

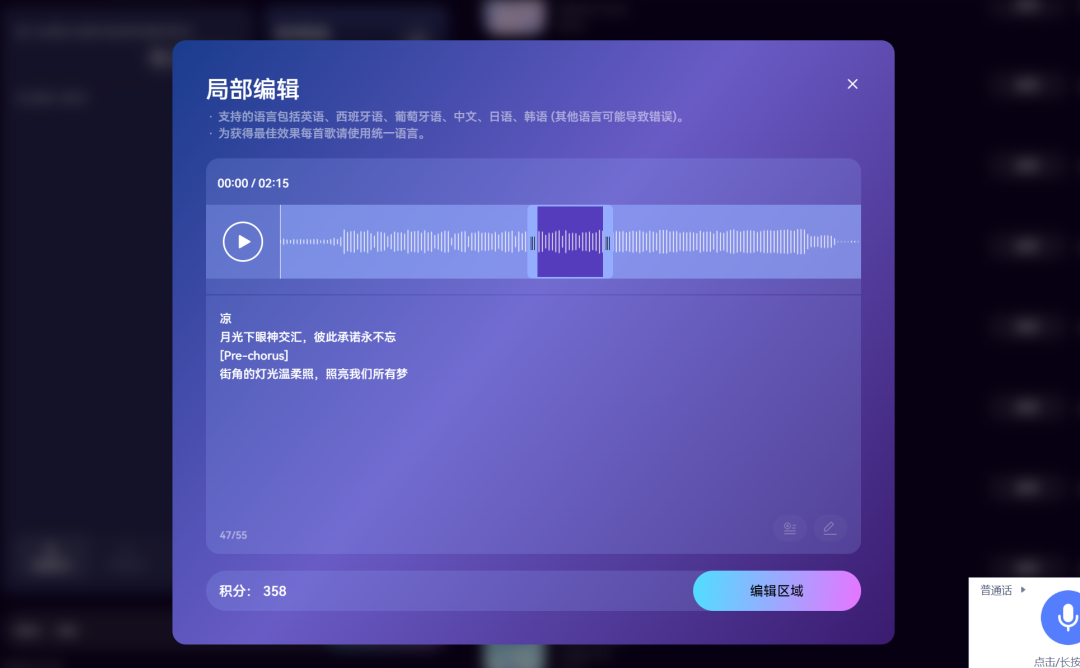
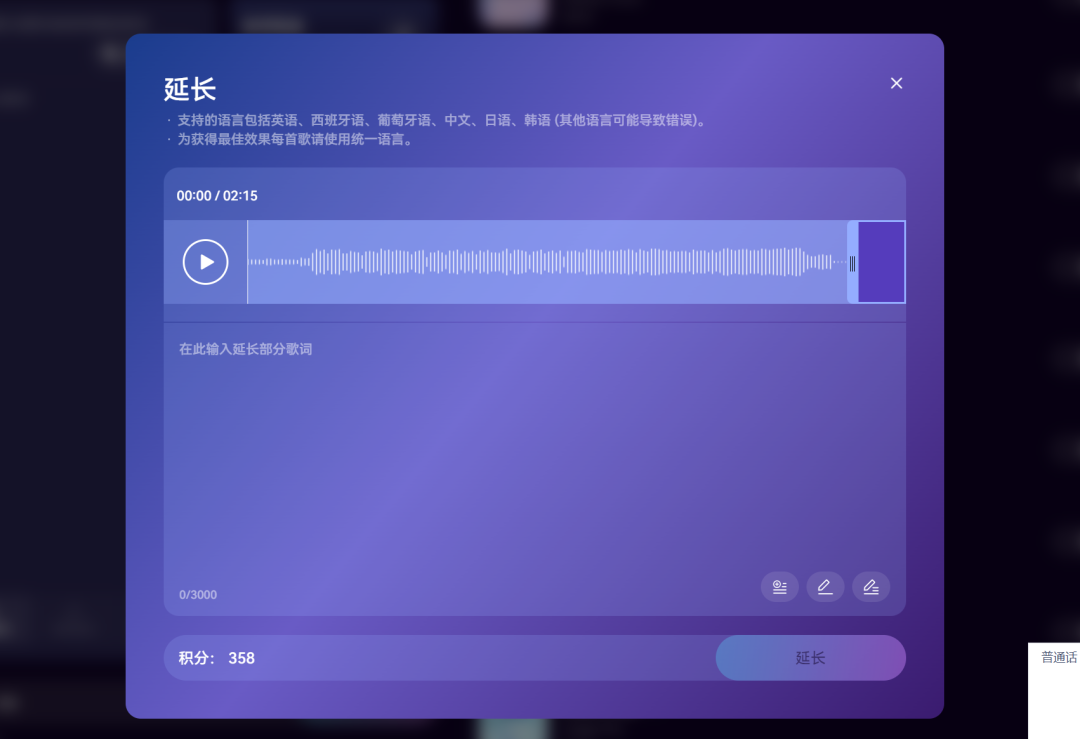
默认生成的音乐长度大约为 2 分钟。如果你想继续延长,只需要补充更多歌词,点击“延长”按钮,AI 就能在原有基础上无缝续写,继续生成下去。
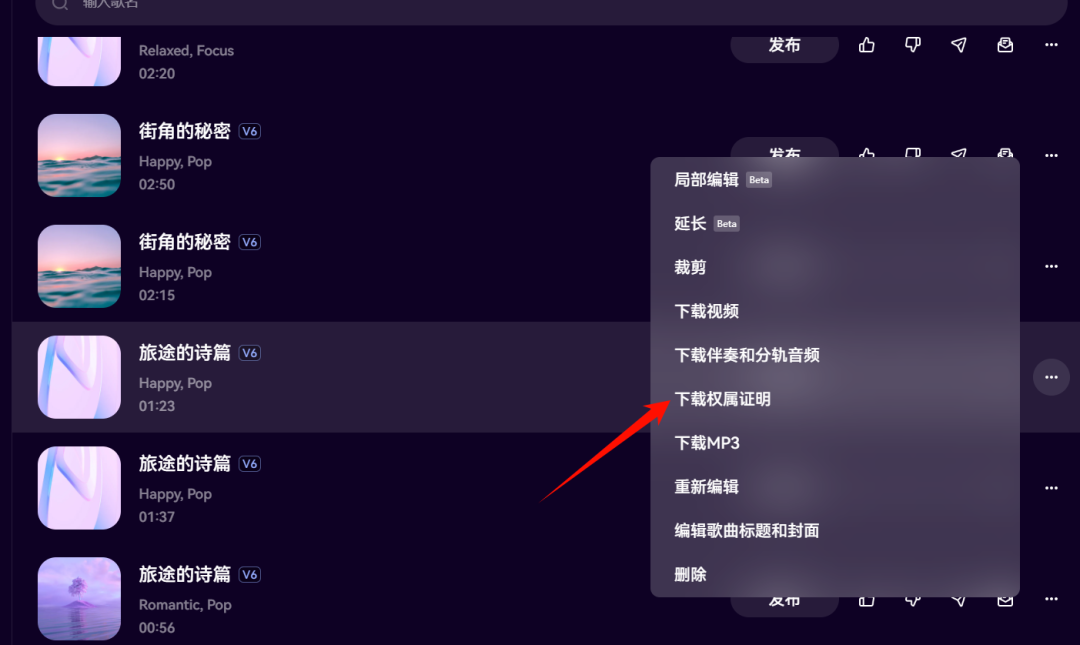
最重要的一点是,用Mureka生成的音乐,是可以卖的,而且是具有创作证明的那种!
除了上面这个Mureka V7音乐模型,音频模型这块,也来了个新东西:Mureka TTS V1。
这玩意儿的主打亮点,叫“Voice Design”,声音设计。
啥意思呢?就是你不用再满世界找现成的音色库去做声音克隆了。
现在,你可以直接用打字的方式,告诉模型你想要什么样的声音特征。
“我想要一个沉稳、略带沙哑的中年男性声音,语速偏慢。”类似这样,直接用文本输入,就能得到对应的音色。
不管是真实人物的声音,还是虚拟角色的,或者是某个配音,都能用文字来控制。
这玩法,算是摆脱了过去只能在现有音色库里挑挑拣拣的限制了。
Mureka TTS V1 模型得分
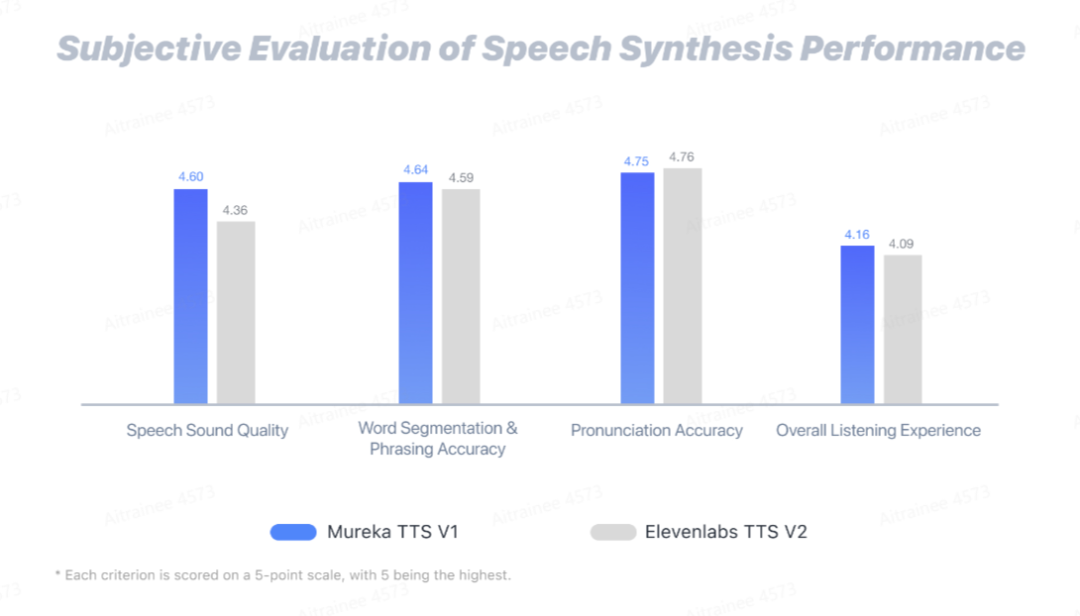
实际效果如下。由于微信文章上传音频数量限制,我把它整合到一个视频里了:
Mureka V7 技术创新:
良品率
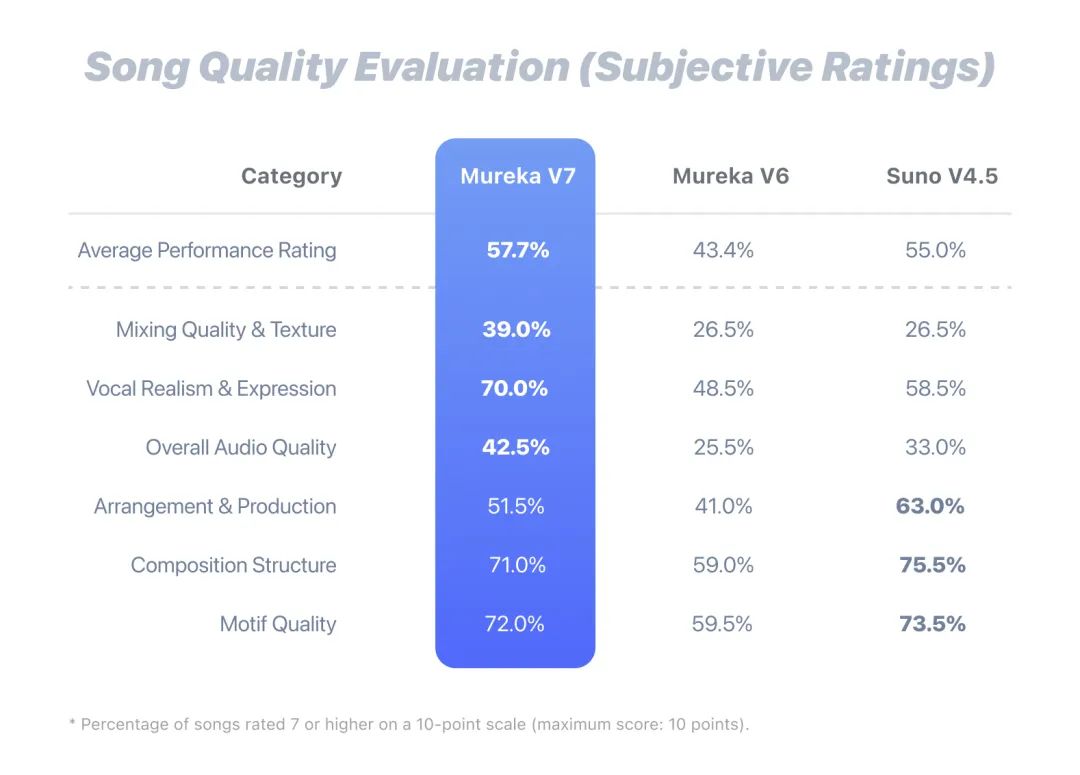
音乐 AI 不该“想到哪唱到哪”,得先有谱再填词
Mureka 团队表示:传统的 AI 音乐生成,基于逐 token 预测的范式,就像个没谱的歌手,一个音符一个音符地往外蹦。
这种自回归 (Autoregressive, AR) 模型,虽然单个音听着还行,但整体听下来,总觉得差点意思。
缺了点连贯的结构和艺术性。
为啥呢?
因为它压根不符合人创作音乐的逻辑。
人写歌,是先有个整体规划,再往里填细节。
所以,Mureka 团队在 V7 版本里,大改了 MusiCoT 这个技术。
MusiCoT,你可以理解成一个专为音乐生成的“链式思维 (Chain-of-Thought)”方法。
它让 AI 在“开口唱歌”前,先学会“谋篇布局”。
先有结构,再有细节
MusiCoT 技术在 AI 开始生成音频之前,会先引导模型搞一份全局的音乐结构规划。
哪是主歌,哪是副歌,情绪怎么走,配器怎么安排,都先想好。
这就解决了传统模型“只顾眼前,不顾大局”的老毛病。
生成的音乐,听起来乐章推进、情绪递进都更自然。
可解释的“音乐思维链”,还能参考风格
MusiCoT 还搞了条能说清楚道明白的“音乐思维链”。
它结合了 CLAP (一种语言-音频预训练模型),让 AI 的创作思路不仅能被分析、被控制,还能输入任意长度的参考音频,作为风格提示。
这样一来,AI 在搞复刻、变奏这些创作时,就更灵活了,也避免了直接抄袭的风险。
Mureka 团队做了大量实验,MusiCoT 技术在主观听感和客观指标上,效果都挺好。
不管是结构完整性、旋律连贯性,还是整体的音乐性,都比传统方法强。
在好几项评测里,表现都达到行业一流水平了。
这个版本里,MusiCoT 不光是在结构上模仿了人的创作思维,还通过 Mureka 团队数据的扩充和 Embedding 信息粒度的细化,让它的可控性和扩展性更强了,文本和音频之间的“代沟”也进一步缩小。
得益于 MusiCoT 的升级,现在有些 AI 生成的作品,已经能给音乐人提供不少创作灵感了。
不止是玩具
但我隐约觉得,这事没那么简单。
这不只是一个,写歌很好玩的玩具。
我手贱,去查了下这个领域的数据。
据Fortune Business Insights数据显示,2023 年全球数字音频工作站(DAW)市场规模已达约30 亿美元。
预计到 2026 年,约 70% 的 DAW 企业将引入 AI 技术,辅助音乐创作流程。
而根据GlobeNewswire的进一步预测,到 2032 年,全球 DAW 市场规模有望突破66.2 亿美元,
从 2024 年到 2032 年的年均复合增长率(CAGR)将达到8.6%。
我看到的不是数字。
这是一场正在水面下进行的,无声的淘金热。
而Mureka背后的公司,昆仑万维…
他们的动作更直接。
「All in AGI与AIGC」这是一个宣言。
一种决心。
Mureka这个名字的来源,我去查了。
结果,简单得可爱。
Music+Eureka。
就是阿基米德光着身子跑出浴缸时,大喊的那声“我找到了!”的时刻。
是每个人灵感迸发时,那个独一无二的“尤里卡时刻”。
它不仅仅是一款工具。
它更像一个邀请。
邀请每个人,去找到属于自己的那个“尤里卡”。
但说真的。
在关掉那些数据和报告之后。
我一个人,在电脑前坐了很久。
我脑子里不自觉跳出了一个想法。
从前我们说“一首歌一个故事”,是因为它凝聚了太多人的心血。
但现在呢?
当创作被压缩成一个“输入框”时…
故事,会不会因此变得廉价?
我一度这样担心。
直到我换了个角度去想。
也许,是我们一直以来,都把“创作”这个词,看得太神圣了。
我们大多数人,没有那么多波澜壮阔的故事要讲。
我们有的,只是深夜里忽然想吃一碗泡面的纠结;
是等了半小时还没来的那班公交车的烦躁;
是一些没头没脑的梦,和一些说不出口的道歉。
这些微不足道,却又反复在我们生命中喧嚣的情绪。
它们算不算故事?
在今天之前,它们从未被谱写过。
而现在…好像可以了。
我终于能听到自己那些琐碎的心跳,变成了一段独一无二的旋律。
就像有朋友分享给我的,他用Mureka做的歌,歌词只有一句:“会议纪要,不用再写啦”。
简单,有点傻,但那一刻的解脱感,比任何史诗都真实。
也许对世界来说。
这些“作品”依然一文不名。
但对我们自己来说。
它就是全世界。
是我们这种普通人,第一次被真正“听”见的证据。
所以我觉得,Mureka,或者说和它一样的AI。
并没有想抢谁的工作,也没想颠覆整个行业。
它只是弯下腰来。
把原本被供奉在精英殿堂里的“乐器”,交到了我们每一个普通人的手里。
然后轻声对我们说了句:
“去玩吧。”
“现在,你可以了。”(文:AI进修生)