

今天是2025年7月23日,星期三,北京,晴。
我们继续来看文档智能进展,目前的趋势是随着评估的展开,多模态大模型解决文档相关任务的边界越来越清晰,这个具备一定的参考价值,所以看评估。
另外,文档的前沿方向之一,是在多页理解方面,但价值感较大的还是在数据上,所以也关注下数据部分,看一个工作,长文档问答数据集Doc-750K,重点看看其实现方式。
核心还是要梳理清楚逻辑,多思考,多借鉴。
一、多模态模型在OCR生成任务上的表现评估
我们先看一个ocr的评估问题,《esthetics is Cheap, Show me the Text: An Empirical Evaluationof State-of-the-Art Generative Models for OCR》,https://arxiv.org/pdf/2507.15085,https://github.com/NiceRingNode/Awesome-Generative-Models-for-OCR,这个工作的图做的很漂亮,当前sota 多模态模型在不同OCR生成任务上的效果,主要集中在测试生成和编辑能力。
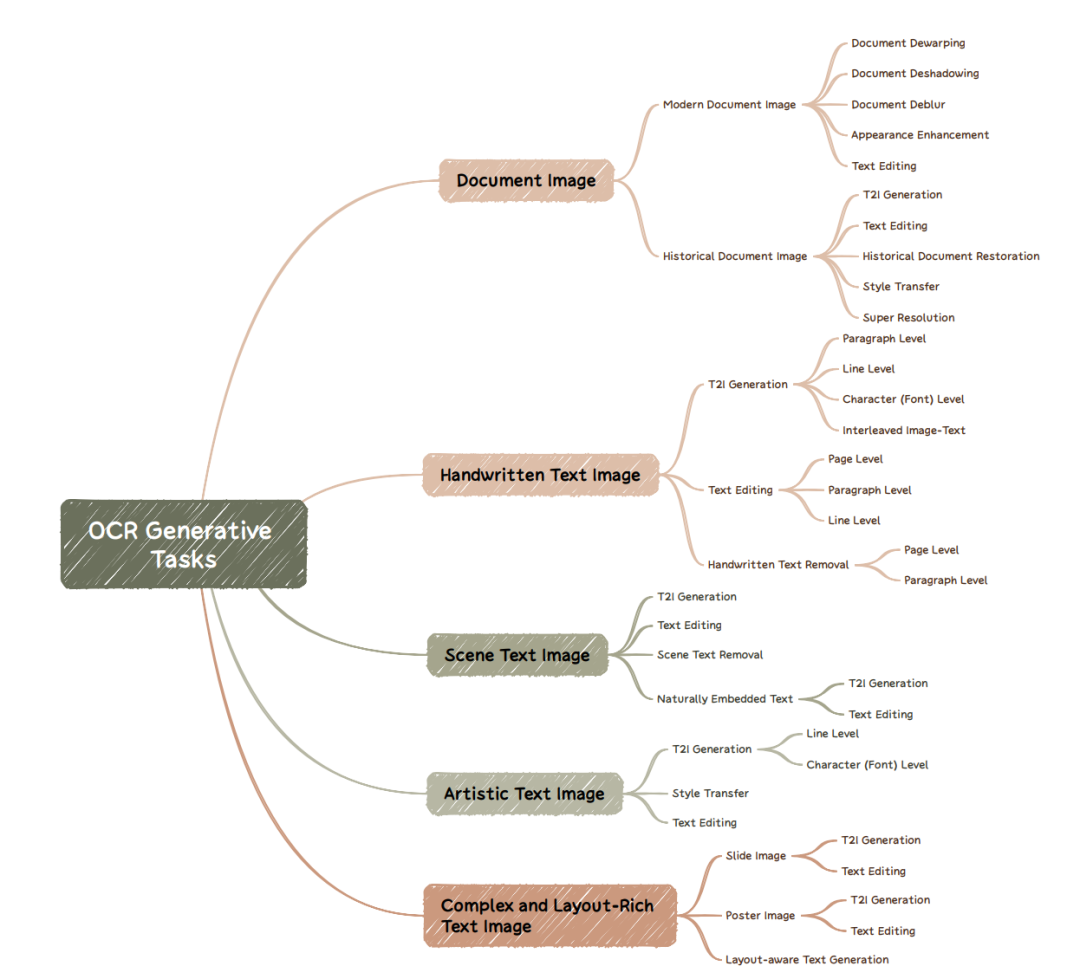
在测试模型上,,包括闭源和开源模型,已经测试了GPT-4o、Qwen-VLo、Flux.1-Kontext-dev和Janus-4o这些sota模型?如下:

在评估内容方面,包括生成多种类型的文本图像(手写笔记、印刷文档、海报、路牌、历史手稿等)以及编辑文本图像中的特定内容。
例如:
1、document deshadowing and document deblurring tasks

2、document appearance enhancement task

3、Text editing task
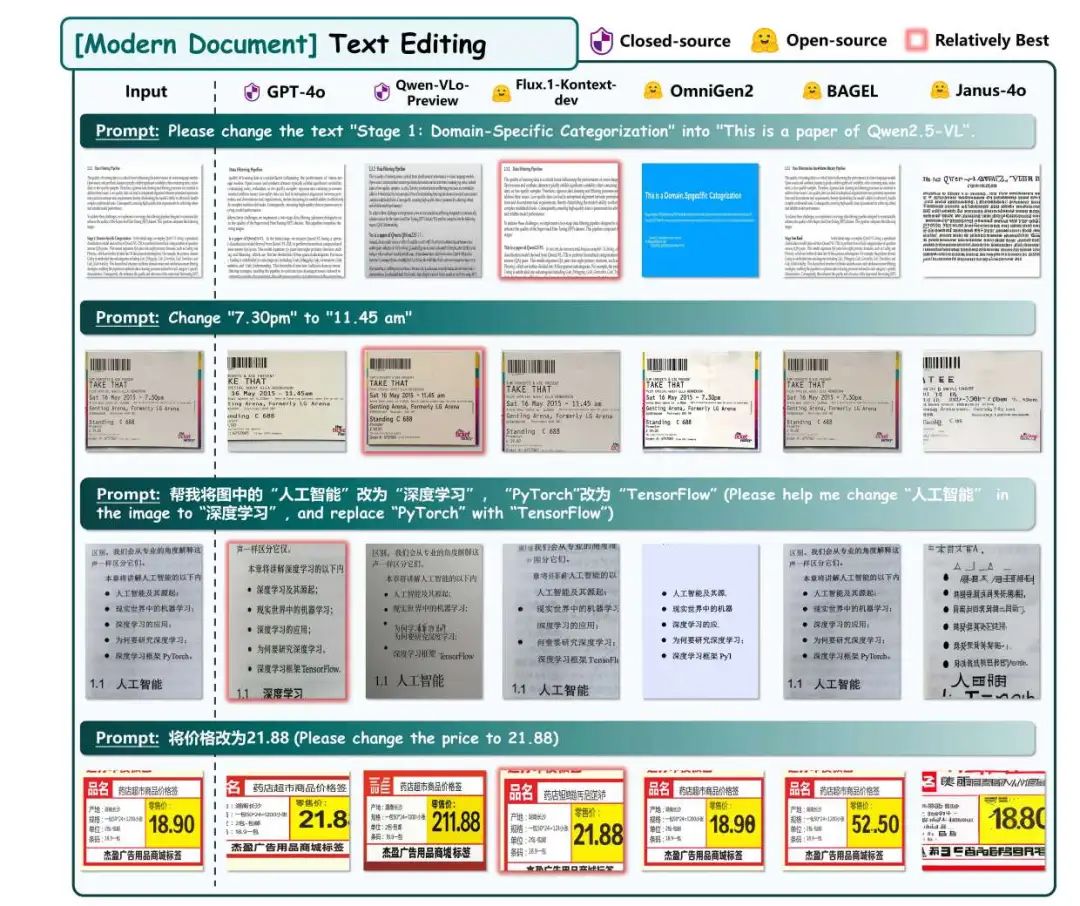
4、handwritten text removal task

5、T2I generation task

在评估结论方面,并没有量化指标,是一些感官上的结论。
表现良好的任务有文本到图像 (T2I) 生成(手写文本、场景文本、幻灯片或其他创意图形、古文字、重叠文本和图像)、文本超分辨率、文本风格转换、场景文本去除;
有时有效,有时无效的任务包括手写文本删除、布局感知文本生成;
当前无法完成的任务包括文档去扭曲、文档阴影消除、文档去模糊、文档外观增强、历史文献修复、历史文献风格转换以及有序文本生成(生成类似 0、1、2、… 的文本)。
二、多模态大模型长文档多页理解数据集
继续看数据集进展,《Docopilot: Improving Multimodal Models for Document-Level Understanding》,https://arxiv.org/pdf/2507.14675,https://github.com/OpenGVLab/Docopilot,这个工作为了解决现有模型在多页、跨页文档理解任务上效果差、延迟高、信息碎片化的问题,构建了一个长文档问答数据集Doc-750K,地址已经开源,放在:https://huggingface.co/datasets/OpenGVLab/Doc-750K

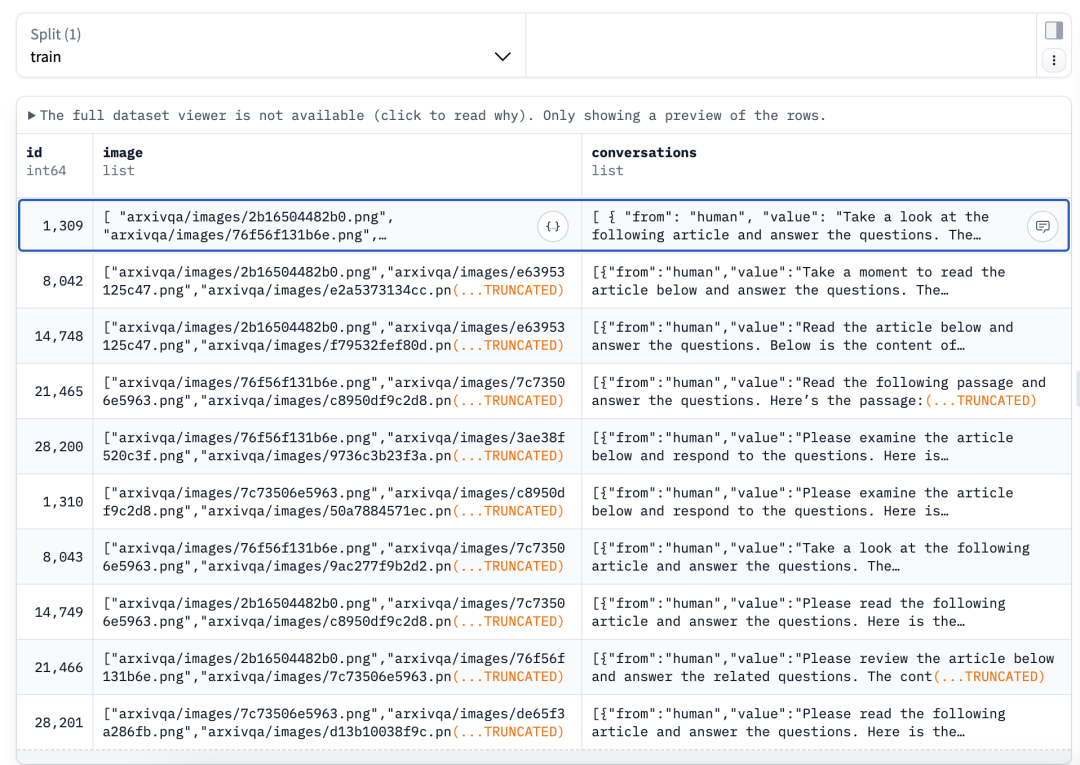
我们重点看下数据处理细节:

数据方面,从Sci-Hub、ArXiv、OpenReview等来源收集75.8万条真实QA对,含3.1M图像、5.2B文本Token,采用“交错文本-图像”与“多页渲染图像”两种统一格式,保留文档结构与排版,涵盖了来自各种来源的内容,如Sci-Hub、Arxiv和OpenReview,覆盖广泛的主题和文档布局,但是,仅限于学术领域。
其中,多页渲染图像格式如下:

交错-文本-图像格式如下:

任务方面,设计9类任务(摘要撰写、图表说明、实验撰写、翻译、评论回复等)

参考文献
1、https://github.com/NiceRingNode/Awesome-Generative-Models-for-OCR
2、https://github.com/OpenGVLab/Docopilot
(文:老刘说NLP)