


©作者 | 张彧
单位 | 浙江大学
研究方向 | 音乐/空间音频
零样本歌声合成(SVS)旨在基于音频或文本提示,生成具有未见过的多级别风格的高质量歌声。该领域在专业音乐创作和短视频配音方面具有广泛的潜在应用。
尽管传统的歌声合成任务已经取得了显著进展,但人们对更具定制化的体验需求日益增长。这不仅包括通过音频提示实现零样本风格迁移,还需要利用自然语言文本提示进行多级别风格控制。
文本提示可以通过指定歌手的性别和音域来影响整体音色。此外,它们还能控制更广泛的歌声风格方面,例如演唱技巧(如美声唱法)和情感表达(如欢快或悲伤),以及片段级或词语级的技巧(如混声或假声)。
此外,音频提示能让目标在学习这些一致的多级别风格的同时,融入口音、发音和过渡方式。然而,当前的模型在零样本场景下,仍难以基于各种提示有效实现风格迁移和风格控制。
为此,来自浙江大学的学者提出了一个多任务多语言零样本歌声合成模型 TCSinger2,可以通过自然语言文本、语音或歌声提示实现有效的风格控制。目前,该论文已被 ACL 2025 接收,并已开源相关代码。

论文链接:
https://arxiv.org/abs/2505.14910
Demo 链接:
https://aaronz345.github.io/TCSinger2Demo/
代码链接:
https://github.com/AaronZ345/TCSinger2

任务动机
目前,可定制的多语言零样本歌声合成主要面临两大挑战:
1. 现有歌声合成模型严重依赖音素和音符边界标注,这限制了模型的稳健性。像 OpenCpop 这类数据集依赖 MFA 和人耳对齐,这会在边界处引入显著误差。此外,这些歌声合成模型在音素和音符之间的过渡往往表现不佳,尤其是在零样本场景中,这一问题更为突出。
2. 现有的具备风格迁移和风格控制功能的歌声合成模型,缺乏通过多样化提示实现有效的多级别风格控制的能力。TCSinger 借助指定标签或音频提示实现了风格控制。然而,它仍无法通过更灵活的提示(包括自然语言文本、语音或歌声提示)覆盖更广泛的应用场景。
为了应对这些挑战,我们提出了 TCSinger 2,这是一个多任务多语言零样本歌声合成模型,能够基于多种提示实现风格迁移和风格控制。TCSinger 2 可以通过自然语言文本、语音或歌声提示实现有效的风格控制。为了实现流畅且稳健的音素 / 音符边界建模,我们设计了模糊边界内容(BBC)编码器。该编码器能够预测时长、扩展内容嵌入,并对音素和音符边界进行掩码处理,从而促进平滑过渡并确保稳健性。
此外,为了从歌声、语音和文本提示中提取对齐的表征,我们提出了基于对比学习的定制音频编码器,这扩展了模型在更广泛相关任务中的适用性。同时,为了生成高质量且具有高度可控性的歌声,我们引入了基于流的定制 Transofmer。在这一框架中,我们采用了 Cus-MOE,它能根据语言以及文本或音频提示选择不同的专家,以实现更好的合成质量和风格建模。而且,我们还融入了基于基频(F0)信息的额外监督,以增强合成输出的表现力。

模型方法
首先,编码器利用对比学习从歌声、语音和文本提示中提取一致的表征。当从跨语言歌声或语音音频提示迁移风格时,它会提取富含风格的表征。当使用文本提示进行风格控制时,文本提示会被编码为多风格控制表征。最后,基于流的定制转换器生成预测的歌声。
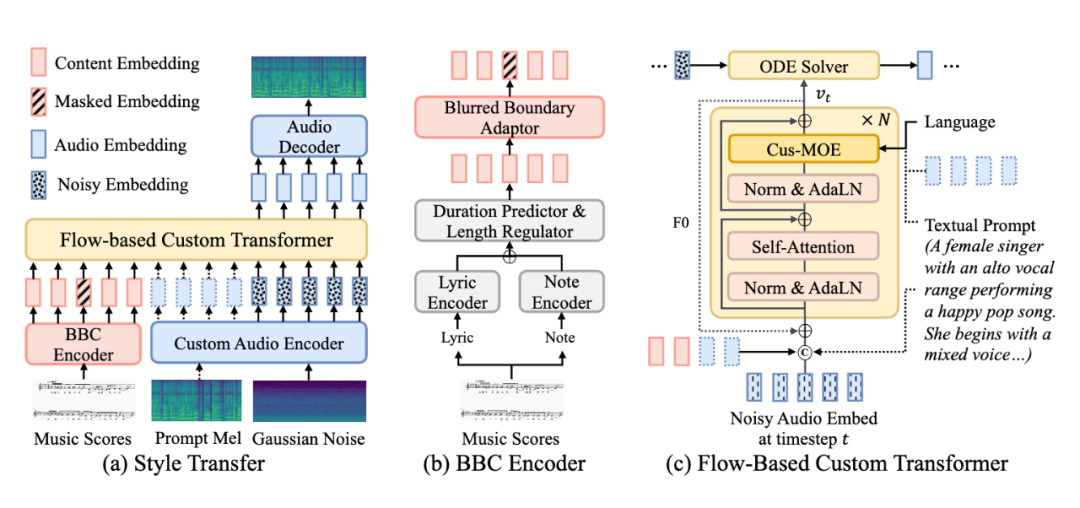
▲ 图1:TCSinger 2 的架构。BBC Encoder 即模糊边界内容编码器。图(a)展示了风格迁移过程。来自音频提示的梅尔频谱或文本提示均可控制多级别风格。
模糊边界内容编码器
当前的歌声合成(SVS)模型严重依赖精确的音素和音符边界标注,这些标注通常是使用 MFA 等工具自动生成的。然而,经过人工后期编辑的数据集十分稀少,即便那些基于人类听觉标注的数据集也存在诸多错误。这在多语言歌声数据集中尤为成问题,标注错误和数据稀缺会导致音素和音高的学习出现偏差。例如,当一个音素时长的后半部分实际上属于下一个音素时,模型很难正确学习这两个音素的发音。此外,当前的歌声合成模型在音素和音符之间的过渡表现不佳,尤其是在零样本场景中,这一问题更为突出。
为解决这一问题,同时在扩展数据集的基础上提升零样本场景下过渡的自然度和音乐性,我们引入了模糊边界内容(BBC)编码器。如图 1(b)所示,在对歌词和音符分别进行编码后,我们会预测时长并扩展内容嵌入,最终得到具有精确的边界的序列。接下来,我们在每个音素和音符的边界处随机掩盖 m 个标记。通过调整 m 的值,我们可以在提供更多监督信息和实现更好的稳健性之间取得平衡。考虑到我们的压缩率和采样率,我们将 m 设为 8。需要注意的是,m 不会覆盖过短的内容。借助 BBC 编码器,我们得到模糊的边界,随后在基于流的定制转换器中进行细化,其中自注意力机制会建立细粒度的隐式对齐路径。BBC 编码器扩展了粗略对齐的数据集,改善了过渡的自然度,并提升了零样本生成的质量。
定制音频编码器
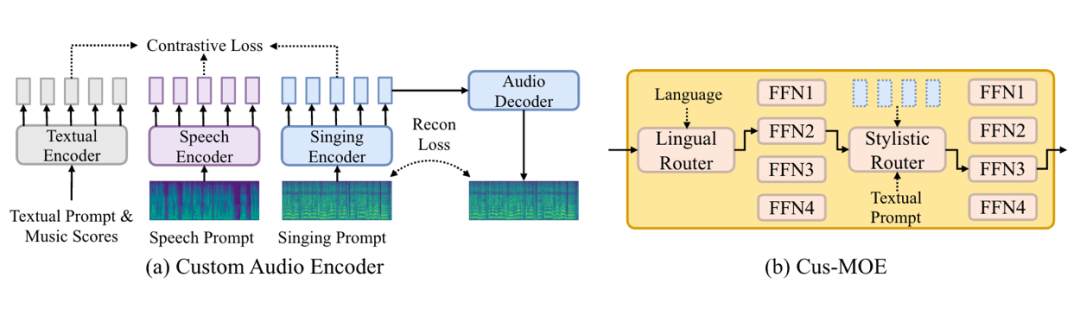
▲ 图2:定制音频编码器和 Cus-MOE 的架构。在图(a)中,不同的编码器根据输入提取对齐的表征。在图(b)中,每个路由在推理过程中会根据条件选择一个前馈网络。
歌声风格非常复杂,包含音色、唱法、情感、技巧、口音等多种因素。这使得在对歌声梅尔频谱进行压缩的同时,提取出富含多级别风格的表征颇具挑战性。而这种表征对于风格迁移和风格控制而言都至关重要。此外,为了拓展可定制的应用场景,从语音中提取对齐的风格表征也很重要。这能让用户生成与自己语音风格相匹配的歌声。
如图 2(a)所示,基于歌声提示、语音提示以及带有内容的文本提示,我们提取出一个三元组。歌声编码器、语音编码器和音频解码器均基于变分自编码器(VAE)模型。对于文本编码器,我们采用交叉注意力机制将乐谱和文本提示相结合,得到兼具内容和多级别风格的表征。我们使用对比学习来对齐这些三元组,确保它们都包含统一的风格。我们设计了三种对比类型:(1)相同内容,不同风格;(2)相似风格,不同内容;(3)不同风格和内容。
基于流的定制 Transofmer
歌声具有高度的复杂性和风格多样性,这使其建模工作极具挑战性。为此,我们提出了基于流的定制 Transformer。如图 1(c)所示,我们将能够生成稳定且平滑路径的流匹配技术相结合,以实现稳健且快速的推理。此外,我们还利用 Transformer 注意力机制的序列学习能力,来提升歌声合成(SVS)的质量和风格建模效果。
为实现更高质量的多语言生成和更优的风格建模,我们提出了 Cus-MOE(混合专家模型),它能基于各种条件选择合适的专家。如图 2(b)所示,我们的 Cus-MOE 包含两个专家组,每组分别专注于语言条件和风格条件。语言混合专家模型根据歌词语言选择专家,每个专家专攻特定语系(如拉丁语系),通过领域特定专家提升各语系的生成质量。风格混合专家模型以音频或自然语言文本提示为条件,调整输入以匹配细粒度风格,例如有专家专攻女低音音域且带有欢快流行风格的假声演唱。
推理流程
TCSinger 2 支持基于输入提示的多种推理任务。对于未见过的歌声提示,无论内容与提示语言相同还是不同,它都能执行零样本风格迁移。若输入包含歌词和不同语言的歌声提示,该模型可进行跨语言风格迁移。给定自然语言文本提示时,TCSinger 2 能够实现多级别风格控制。当提供语音提示时,它可以执行语音转歌声风格迁移。
为了提升生成质量和风格可控性,我们融入了无分类器引导(CFG)策略。在训练过程中,我们会以 0.2 的概率随机丢弃输入提示。我们将 CFG 系数设为 3,以提高生成质量并增强风格控制。最后,借助流匹配方法的加速推理能力,我们的模型能够高效且稳健地生成歌声。

实验结果
为了 TCSinger 2 的风格迁移效果,在平行实验中,我们从测试集中随机选取未见过的歌手样本作为目标声音,并使用同一歌手的不同语音片段构建提示。此外,我们还采用歌词语言不同(如英语和汉语)的未见过测试数据分别作为提示和目标进行推理。
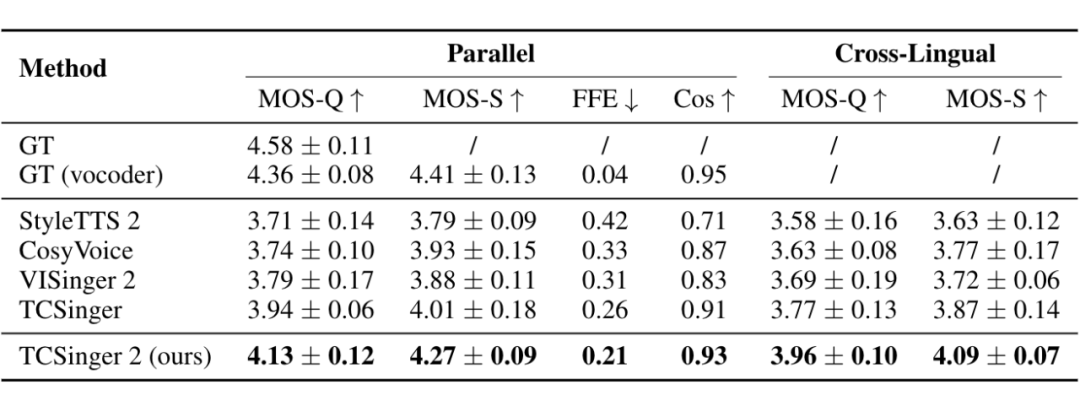
▲ 表1:零样本平行风格迁移与跨语言风格迁移的合成质量及歌手相似度。
对于风格控制,表 2 展示了使用自然语言文本提示进行风格控制的实验结果。我们在基准模型中添加了一个交叉注意力模型来处理文本提示。在平行实验中,我们从测试集中随机选取未见过的音频,将真实(GT)文本提示作为目标。在非平行实验中,多级别风格会以适合上下文的方式被随机分配。
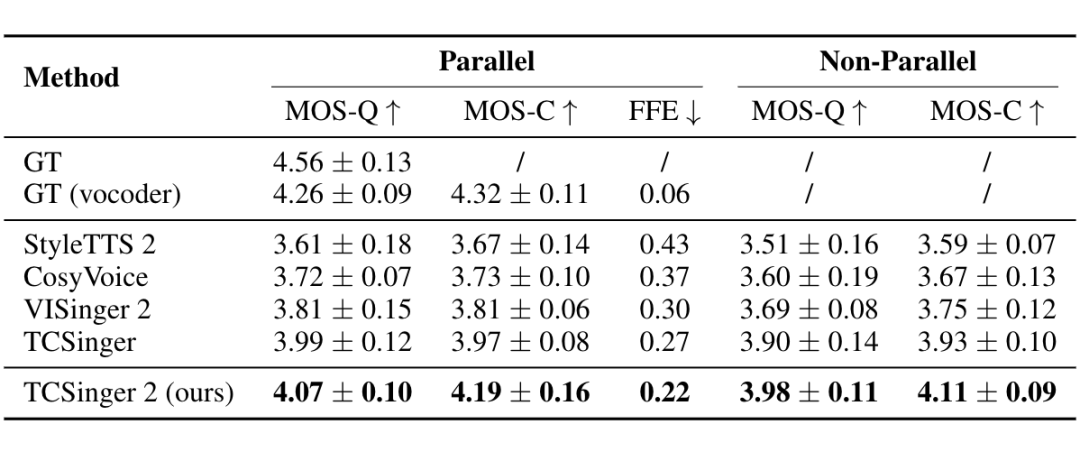
▲ 表2:基于文本提示的平行与非平行实验中的多级别风格控制性能。
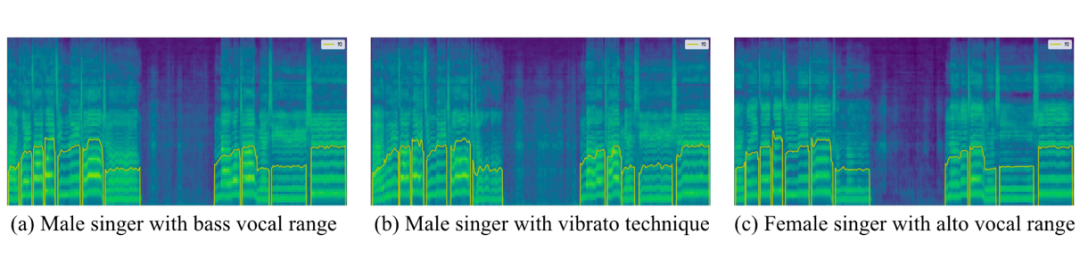
▲ 图3:风格控制的可视化结果。图(b)比图(a)显示出更大的基频(F0)波动,突出了颤音效果。图(c)比图(a)具有更高的共振峰和更丰富的高频细节,体现了不同歌手的身份特征。

总结展望
在本文中,我们提出了 TCSinger 2,这是一款多语言、多任务、零样本歌声合成模型,具备基于多种提示的高级风格迁移和风格控制能力。我们的实验结果表明,在零样本风格迁移、跨语言风格迁移、多级别风格控制以及语音转歌声(STS)风格迁移等多种相关任务中,TCSinger 2 在合成质量、歌手相似度和风格可控性方面均优于其他基准模型。在未来的工作中,我们将设计更好的自动标注工具来扩展数据,同时将研究利用 MeanFlow 等方法以减少延迟。
(文:PaperWeekly)