
分享


Grok 4基准测试被爆极其优异,人类终极考试成绩飙升到45%,碾压o3 和Gemini的20%

Grok-4的基准测试数据在网上疯传,HLE成绩达到35%,使用推理后更是飙升到45%,相当于直接翻了一倍多,引发热议。

DeepSeek被「猫咪睡觉」给干崩了……

研究员们发现,一句关于猫咪有趣的事实能轻易让AI 出错。通过CatAttack方法测试后,DeepSeek V3的错误率提升了超过300%,表明推理模型在面对看似无关的信息时仍易受影响。
Cursor 1.2 更新!Agent 更会规划+支持排队,Pro 套餐限制:突发额度用完,要么等冷却要么付费。

(Agent To-dos)
代理将工作分解为清晰的待办事项列表
那些需要好几步才能完成的复杂任务,
使用 Boris FX CrumplePop 中的新 AI 模型在几秒钟内修复音频
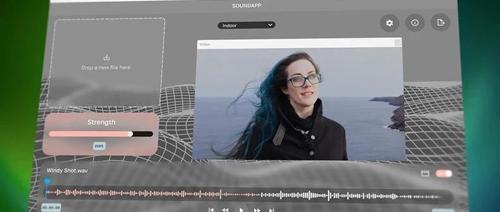
Boris FX CrumplePop更新至2025.5版本,引入新的SoundApp独立应用程序简化音频清理工作流程。支持Mac和Windows系统,包含去除风噪声、回音、交通噪声等AI模型。

传统搜索的终章?信息检索正走向“Agentic Deep Research”新时代

研究提出了一种基于推理的深度研究代理,能够自主分析和整合多源信息以完成复杂的研究任务。该代理在OpenAI的多项评测中表现出色,并受到学术界的广泛关注。
