
学术

1比特KV量化,10倍吞吐提升无损性能:多模态适用的KV cache量化策略来了,即插即用无需改原模型
读
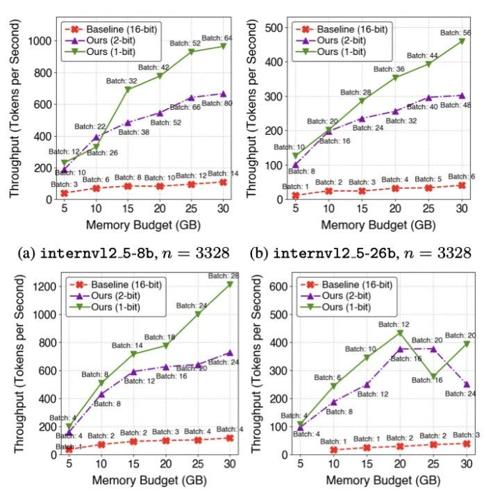
在InternVL-2.5上实现10倍吞吐量提升,模型性能几乎无损失。
>>
加入极市CV技术交
CVPR 2025|超强异常检测新方法!INP-Former 从单张图像中提取正常模式
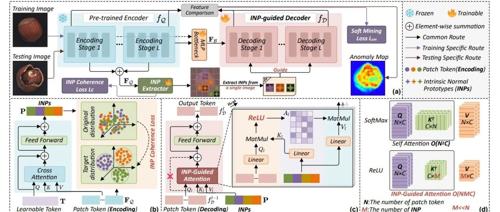
清华大学和华中科技大学的研究团队提出了一种新型异常检测方法INP-Former,通过从单张测试图像中动态提取内在正常原型(INPs),并利用这些INPs指导图像重建,实现了卓越的性能和强大的泛化能力。
从零搭一套可复现、可教学、可观察的RL for VLM训练流程,我们试了试

MAYE 是一个从零实现的 RL for VLM 框架与标准化评估方案,旨在提升透明度和可复现性。它通过简化架构、提供标准评估体系及实证研究支持,帮助学者更清晰理解模型训练过程及其行为变化。
CVPR 2025 HighLight|打通视频到3D的最后一公里,清华团队推出一键式视频扩散模型VideoScene

清华大学研究团队提出VideoScene模型,实现视频到3D场景生成的‘一步式’方法。通过利用3D-aware leap flow distillation策略和动态降噪策略,大幅提升生成效率并保证高质量。
AI封神了!无剪辑一次直出60秒《猫和老鼠》片段,全网百万人围观

加州大学伯克利分校、斯坦福大学和英伟达联合制作的《猫和老鼠》短片背后的研究者介绍了测试时间训练层(TTT)的有效替代方法,用于生成复杂动态故事的长视频。

南洋理工&普渡大学提出CFG-Zero*:在Flow Matching模型中实现更稳健的无分类器引导方法

南洋理工大学 S-Lab 与普渡大学提出 CFG-Zero* 方法,改进 Flow Matching 模型的 Classifier-Free Guidance,提升生成图像/视频的质量和一致性。
视频推理的R1时刻!港中文、清华推出首个Video-R1,7B模型竟超GPT-4o?

港中文联合清华团队发布首个将强化学习范式应用于视频推理的模型Video-R1,该模型通过引入时序建模和混合训练机制,在权威测试中击败了GPT-4o。
全日程揭晓!ICLR 2025论文分享会我们北京见

ICLR 2025 论文分享会将于4月20日在北京举办,主题包括训练推理、多模态和Agent等。顶尖专家李崇轩将介绍扩散模型在大语言模型范式中的应用,陈键飞则介绍高效训练推理的理论及算法。