
DeepSeek R2 参数被“意外”泄漏
DeepSeek R2参数量高达1.2万亿,采用Hybrid MoE 3.0架构,在保持模型能力的同时实现了计算资源的极致压缩,并引入了专门针对法律文书分析的新模块。其多模态精度达到92.4%,误报率低,部署优势明显,支持国产芯片优化,预计未来将减少对西方依赖。
DeepSeek R2参数量高达1.2万亿,采用Hybrid MoE 3.0架构,在保持模型能力的同时实现了计算资源的极致压缩,并引入了专门针对法律文书分析的新模块。其多模态精度达到92.4%,误报率低,部署优势明显,支持国产芯片优化,预计未来将减少对西方依赖。

Transformer Lab 是一个专为 LLM 设计的实验平台,支持一键下载多种开源模型、微调训练、搭建 RAG 应用,并且在本地运行保证隐私安全。
Cognition 团队开源 DeepWiki 项目,旨在自动生成 GitHub 项目的文档页面,帮助开发者快速理解代码库的核心架构、组件与依赖关系,改变软件工程师阅读和维护代码的方式。
斯坦福大学的CS25 – Transformers United V5神课邀请了多位业界顶尖专家讲解Transformer架构、大语言模型等前沿主题。课程免费开放,支持线上Zoom直播或回放观看。

当前,我们正处在Agent开发的‘工程化转折点’。构建一个能实际应用于业务场景的Agent系统,需要围绕四大核心模块进行有机组合:记忆管理、工具调用、控制机制及运行环境。

本教程探讨了AI语言模型中的角色提示技术,涵盖角色分配、角色描述编写、背景设定和任务定义方法,并通过Python代码结合千问大模型和LangChain进行实践,提升AI模型在不同应用中的表现。
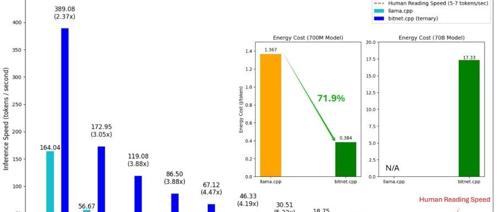
微软发布BitNet推理框架,通过三值量化将LLM模型大小瘦身至原来的1/16,在CPU上实现2.37到6.17倍加速,并节能82.2%,甚至可在普通笔记本CPU上运行100B参数级大模型。
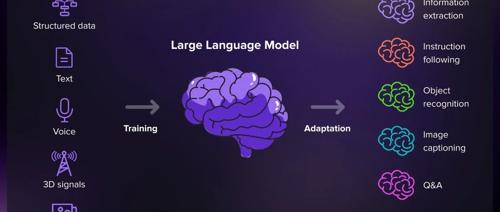
近年来ChatGPT爆火,让大语言模型走进大众视野。本文系统梳理了其原理、训练方式及其应用,涵盖数据、架构和训练三大要素,并展示了微调与实际应用场景,如客户服务、内容创作等。

