
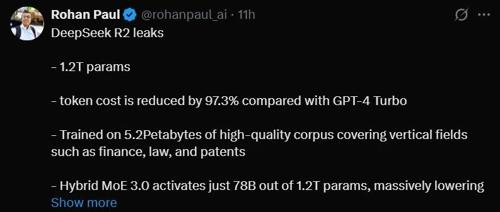

虽然目前关于它的信息还未全部公开,但从已经泄露的资料来看,DeepSeek R2 不仅是技术上的全面升级,更是中国 AI 走向“去西方依赖”的重要一步。
🔧1.2万亿参数背后的“极致性价比”
DeepSeek R2参数量高达1.2T(万亿),采用了Hybrid MoE 3.0 架构,每次推理只激活78B(780亿)参数。这种设计带来了什么?
-
💰 推理成本降低97.3%,远低于GPT-4 Turbo;
-
🧠 在保持模型能力的同时,实现了计算资源的极致压缩;
-
🧮 支持8-bit量化,模型体积缩小83%,准确率下降不到2%,边缘设备也能轻松运行。
📚训练数据:5.2PB高质量语料,专为行业而生
DeepSeek R2的训练数据量达5.2PB,涵盖了金融、法律、专利等多个垂直领域。更重要的是,它引入了一个全新的模块:
🎯Long-Doc Expert —— 专门为分析复杂法律文书、财报、研究论文而设计,兼顾深度与成本控制。
🧬多模态能力:超越CLIP的视觉表现
视觉+文本的融合是大模型发展的必然趋势。DeepSeek R2在这方面也做足了功课:
-
采用ViT-Transformer混合架构
-
多模态平均精度(mAP)达92.4%
-
比CLIP高出11.6%
这意味着它在图文理解、视觉问答、图像生成等任务中具备更强泛化能力。
🏭行业场景全面开花
DeepSeek R2并不止于“模型技术炫技”,它在多个关键行业的应用效果已初露锋芒:
-
🏥 医学影像诊断:X光识别准确率高达98.1%,超过人类水平
-
⚙️ 工业质检:在太阳能电池板缺陷检测中,误报率仅为0.0000072
-
📄 法律金融NLP任务:精准率高,合规性强,真正能“上生产环境”
💻部署优势:中国芯+绿色算力组合
DeepSeek R2特别针对国产芯片做了优化:
-
✅支持华为Ascend 910B/910C,推理性能约为NVIDIA A100/H100的91%/60%
-
✅液冷数据中心PUE仅为1.08
-
✅512 PetaFLOPS的FP16浮点运算能力,能效比领先全球
这一切意味着,中国正逐步摆脱AI基础设施层面对欧美的依赖。
加入知识星球获取精心打造的提示工程、RAG和Agent开发实践教程。
(文:PyTorch研习社)