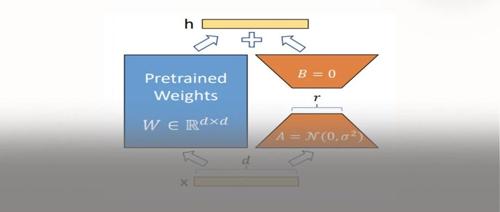
当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势? 2024年12月30日23时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨 CW不要無聊的風格 编辑丨极市平台 极市导读 对炼丹界的当红炸
无需训练!多提示视频生成最新SOTA!港中文&腾讯等发布DiTCtrl:基于MM-DiT架构 2024年12月29日22时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨AI生成未来 来源丨AI生成未来 编辑丨极市平台 极市导读 腾讯
实践教程|图解NumPy,这是理解数组最形象的一份教程了 2024年12月29日22时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨机器之心 来源丨https://jalammar.github.
AAAI 2025 合成数据助力自驾点云异常检测新SOTA 2024年12月27日22时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨Shaocong Xu等 来源丨自动驾驶之心 编辑丨极市平台 极
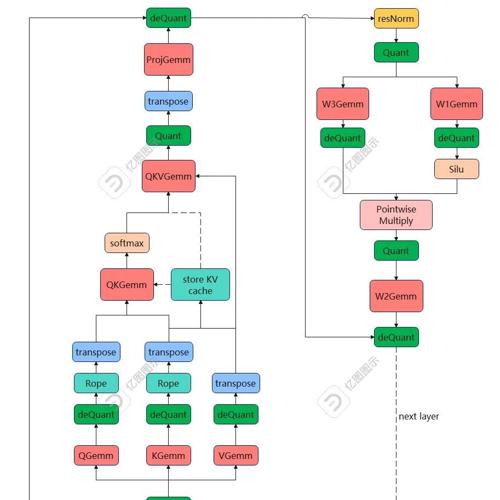
【CUDA编程】手撸一个大模型推理框架 FasterLLaMA 2024年12月27日8时 作者 极市干货 写在前面 :之前笔者写过 4 篇关于 Nvidia 官方项目 Faster Transformer
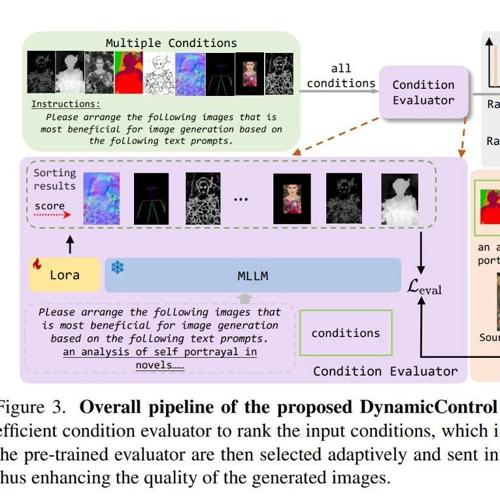
超越ControlNet++!腾讯优图提出动态条件选择新架构 2024年12月27日8时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨极市平台粉丝 编辑丨极市平台 极市导读 腾讯优图提出Dynami
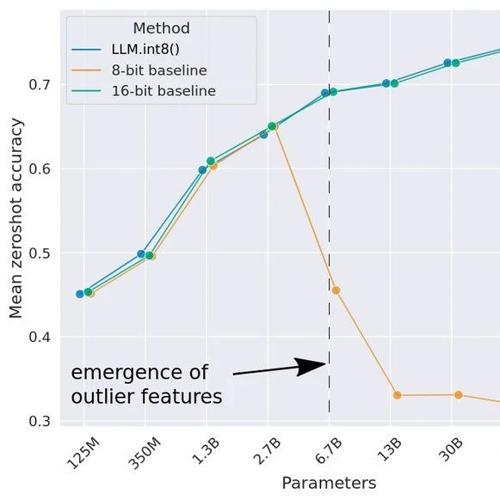
大模型轻量化系列解读 (四):LLM.int8():大语言模型 8-bit 量化初探 2024年12月26日8时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨科技猛兽 编辑丨极市平台 极市导读 本文为 Transforme
AAAI 2025|多场景行人属性识别基准数据集MSP60K:57个类别和8个特定场景 2024年12月26日8时 作者 极市干货 本文提出了一种新的大规模跨域行人属性识别数据集MSP60K,以及一种名为LLM-PAR的大语言模型增强框架用于提升行人属性识别的准确性。

 极市干货
极市干货