每时AI
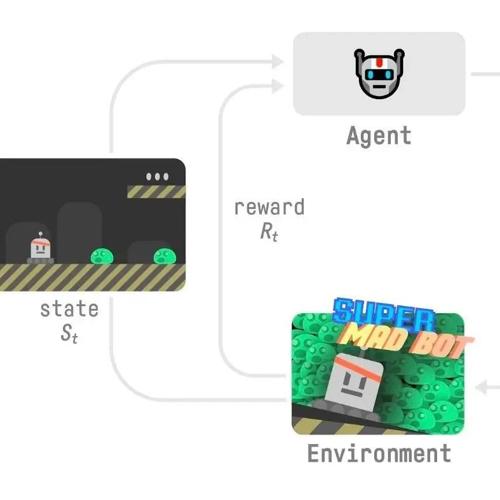
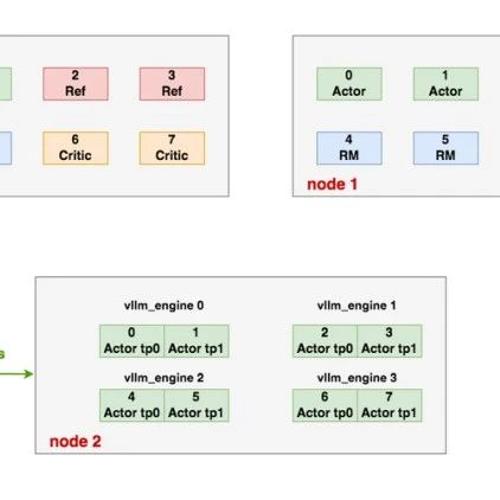
nlan.zhihu.com/p/643751150 编辑丨极市平台 极市导读 通俗易懂讲解PPO算
MLNLP 社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企
↑ 点击 蓝字 关注极市平台 作者丨大猿搬砖简记 来源丨大猿搬砖简记 编辑丨极市平台 极市导读 本文