
强化学习

DeepSeek GRPO 技术揭秘:Unsloth 助力 7GB 显存体验“顿悟时刻”

DeepSeek R1 模型利用 GRPO 算法实现自主学习能力,仅需 7GB 显存即可训练出具备推理能力的模型,大幅降低训练门槛和成本。
从扭秧歌到单脚跳,HugWBC让人形机器人运动天赋觉醒了

AIxiv专栏介绍及其新成果HugWBC控制器,支持机器人同时掌握多种步态及精细调整行为指令,提高运动控制能力。该研究成果在模拟环境中训练,并通过评估验证其有效性。
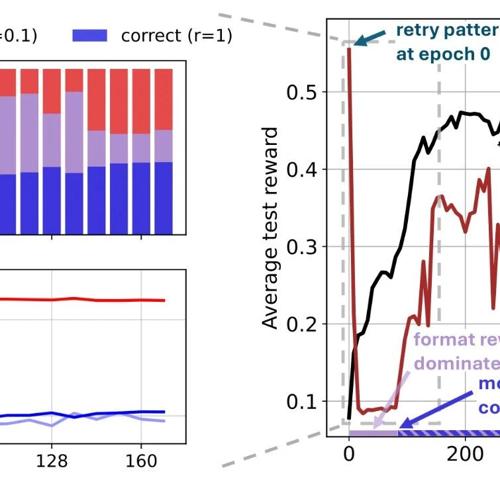
R1-Computer-Use:将Deepseek R1的强化学习技术应用于计算机使用场景
R1-Computer-Use利用Deepseek R1的强化学习技术优化计算机使用场景中的AI行为,支持文件操作、命令行交互等多种任务。



李飞飞S1成本仅50美元性能媲美Deepseek-R1,Logic RL成功重现了 DeepSeek R1 Zero 模型

本文介绍了5个AI和机器学习相关项目及工具:s1用于测试时间缩放提高推理效率;R1-V通过强化学习提升视觉语言模型泛化能力与训练效率;deepseek.cpp是一个基于C++的CPU-only推理实现,旨在为DeepSeek大语言模型提供支持;Logic RL成功复现了DeepSeek R1 Zero逻辑难题数据集上的问题解决能力;OpenHealth则是一款本地运行的AI健康助手。
OpenAI联创John Schulman,被曝火速离职Anthropic!刚刚入职6个月

OpenAI联创John Schulman离职加入竞争对手Anthropic,Schulman曾负责ChatGPT核心架构开发。