
Transformer架构

LLM 自回归+Diffusion Loss?Orthus:仅需72小时训练时间,即可高精度多模态生成

型
Orthus,可同时生成离散文本和连续图像特征。其通过特定的扩散头和语言模型头分别处理图像和文本
Transformer八周年!Attention Is All You Need被引破18万封神

新智元报道
编辑:定慧
【新智元导读】
Transformer已满8岁,革命性论文《Attention Is All You Need》被引超18万次,掀起生成式AI革命。
Transformer催生了ChatGPT、Gemini、Claude等诸多前沿产品。它让人类真正跨入了生成式AI时代。
这篇论文的被引次数已经达到了184376!
尽管当年未获「Attention」,但如今Transformer影响仍在继续。
谷歌开始收回对大模型开放使用的「善意」。
人人都爱Transformer,成为严肃学界乐此不疲的玩梗素材。
小红书hi lab首次开源文本大模型,训练资源不到Qwen2.5 72B 的四分之一

小红书 hi lab 发布开源文本大模型 dots.llm1,参数量为 1420亿(142B),上下文长度32K。采用轻量级数据处理流程和MoE架构训练,相比Qwen2.5-72B在预训练阶段仅需13万GPU小时。支持多轮对话、知识理解与问答等任务,在多个测试中表现突出。

小米入局大模型赛道!开源MiMo-7B,性能超o1-mini

小米发布大模型MiMo-7B,参数70亿,在数学和代码测试中表现优异。MiMo-7B架构简单且效率高,通过MTP模块加速推理。训练数据集包含多种合成推理任务生成的数据,采用三阶段混合策略优化分布。后训练阶段通过SFT调整预训练模型,并使用高质量的强化学习数据提升性能。
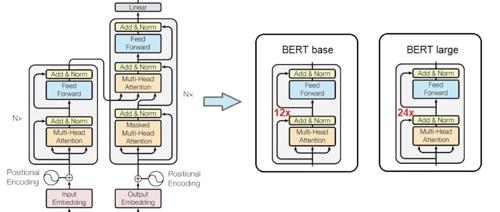


围观!斯坦福最火AI课全球免费开讲,顶级大佬亲授Transformer精髓,课表全放送

斯坦福推出免费在线课程CS25: Transformers United V5,涵盖Transformer架构及其应用,包括语言模型、强化学习、AGI等前沿话题。