
人类打辩论不如GPT-4?!Nature子刊:900人实战演练,AI胜率64.4%,还更会说服人

研究发现,GPT-4提前知晓对手个人信息的情况下,在辩论中胜率高达64.4%,且说服效果提升81.2%。研究还表明低、中强度话题更易被GPT-4影响,而人类则重情感互动。
研究发现,GPT-4提前知晓对手个人信息的情况下,在辩论中胜率高达64.4%,且说服效果提升81.2%。研究还表明低、中强度话题更易被GPT-4影响,而人类则重情感互动。

谷歌发布AlphaEvolve AI工具,用于设计高级算法并解决数学难题,提升效率23%;OpenAI推出GPT-4.1提升编程能力;阿里云和腾讯云也在推动AI程序员应用。

Google更新了两款Gemini新模型Gemini 2.5 Pro和Gemini 2.5 Flash,在视频理解和生成方面表现突出,能生成互动应用、p5.js动画及精准描述视频片段。

就在前不久,GPT-4o突然出现过度谄媚的问题。用户反馈其回复内容充满无脑赞美,甚至只是简单打招呼也能得到夸赞。OpenAI随即回滚了版本并承认这一问题影响用户体验和信任。

MLNLP社区致力于促进国内外机器学习与自然语言处理的交流合作。近期发表论文提出推理奖励模型ReasRM,通过两阶段训练让小模型学会写评语,并在综合、数学题等测试集中优于GPT-4。该模型支持任务分类和动态奖励机制,已在多个领域展示优势。

BrowseComp-ZH团队发布新基准测试集,对20多个主流大模型进行中文网页能力测试,结果显示多数模型在中文互联网检索上准确率低于10%,仅有少数能突破20%。研究揭示了模型在中文信息环境中的“死角”,强调了推理能力和多轮策略的重要性,并指出搜索功能的不当使用可能误导模型。

文章讲述了明星自拍合照、影视剧人物打卡合影以及AI生成照片的热潮,并指出随着AI技术的进步,辨识真假变得愈发困难。提醒读者提高媒介素养和平台监管的重要性。
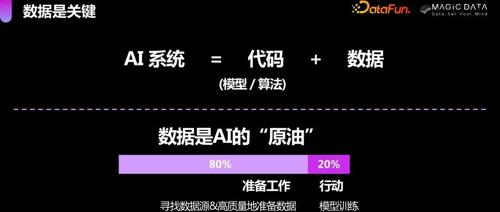
阿里开源的Qwen2.5系列训练数据规模达18万亿 token,推动AI大模型发展。但大规模训练带来幻象问题,RAG技术及工业场景应用以数据为中心成为趋势。国家和行业正积极推进数据标注产业发展规范,提升数据标注行业的合规能力。

