2025年,正在成为Agent元年,也是大年。
最近,一款Design Agent在海外火爆上线,其Demo视频在X上收获了近70w的观看量。
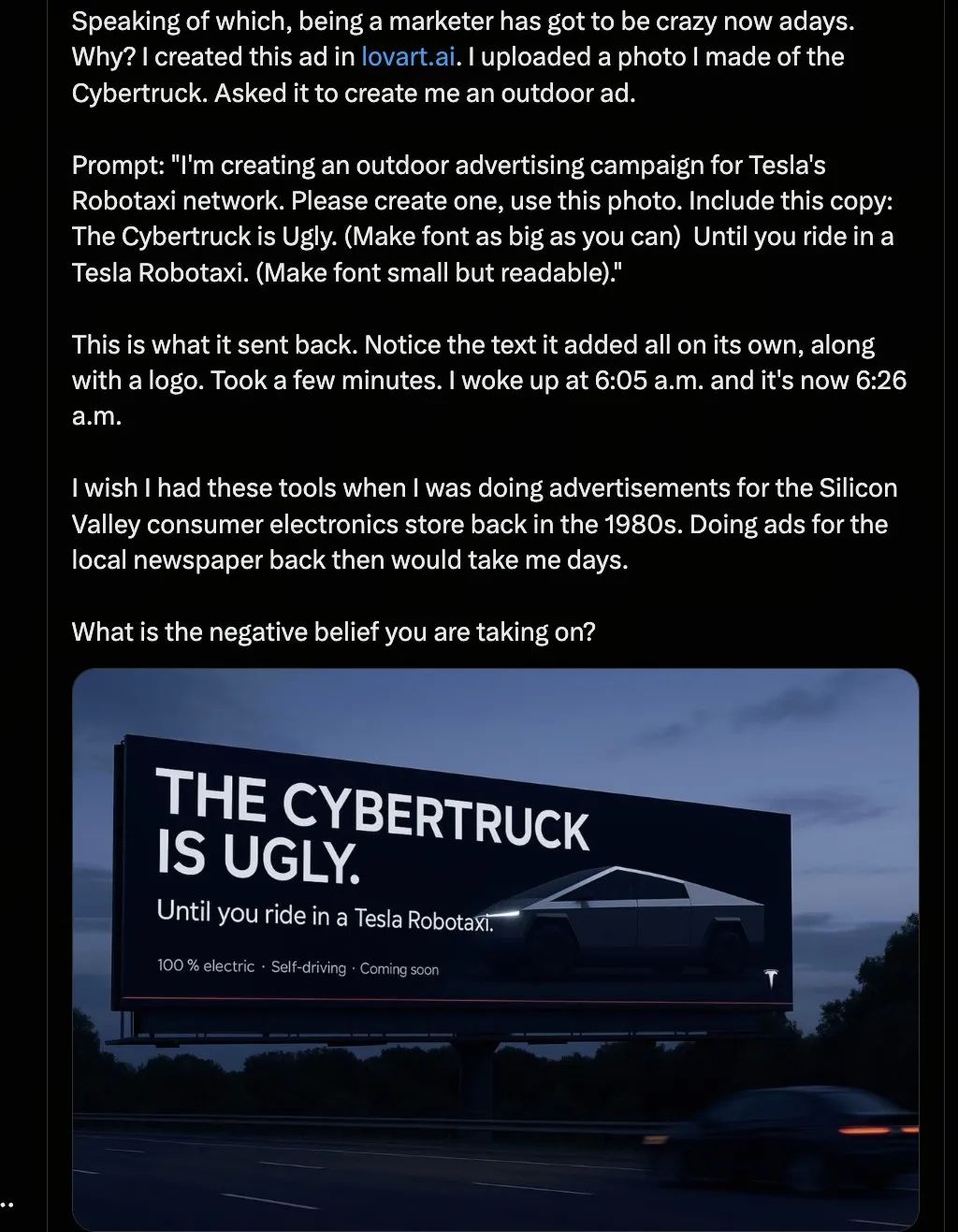
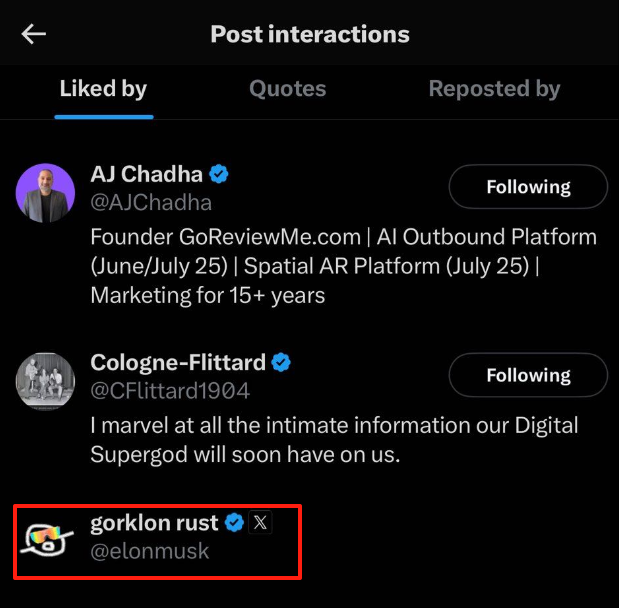
这款产品有多火呢?火到X用户@Robert Scoble 用Lovart做的Tesla广告,刚刚被马斯克亲自点赞。
这张Cybertruck汽车的户外海报,丑(UGLY)并酷着。
这位X博主用的AI产品,正是来自中国的Lovart,体验地址lovart.ai。据沃垠AI了解,这是由liblib推出的全球首款设计Agent,也是liblib继Shakker后的又一款出海产品。
Lovart Agent,集成了设计领域各种主流AI工具(如GPT 4o/o3、Flux Pro、Gemini Imagen 3、Tripo AI、Kling AI、Suno AI)和非AI工具(如Figma、PS)。
只需输入一句Prompt,Lovart Agent会自主调用所有工具、模型,完成从创意拆解到设计规划、设计执行和作品交付的整个设计流程。
Prompt in,product out.
一手实测
产品上线后,我也第一时间在X上跟Lovart化缘,要到了邀请码。
第一次进入他们的网站lovart.ai,就被首屏的交互动画给硬控住了2分钟,真的太好玩了。
点击页面“Get Started”,注册账户,可以使用谷歌邮箱快捷登录,也可以使用QQ邮箱登录。
登录后,进入home页,这是一个很AI Chat的页面,中间是会话框,下面是作品集。
我们先来一个简单的prompt:
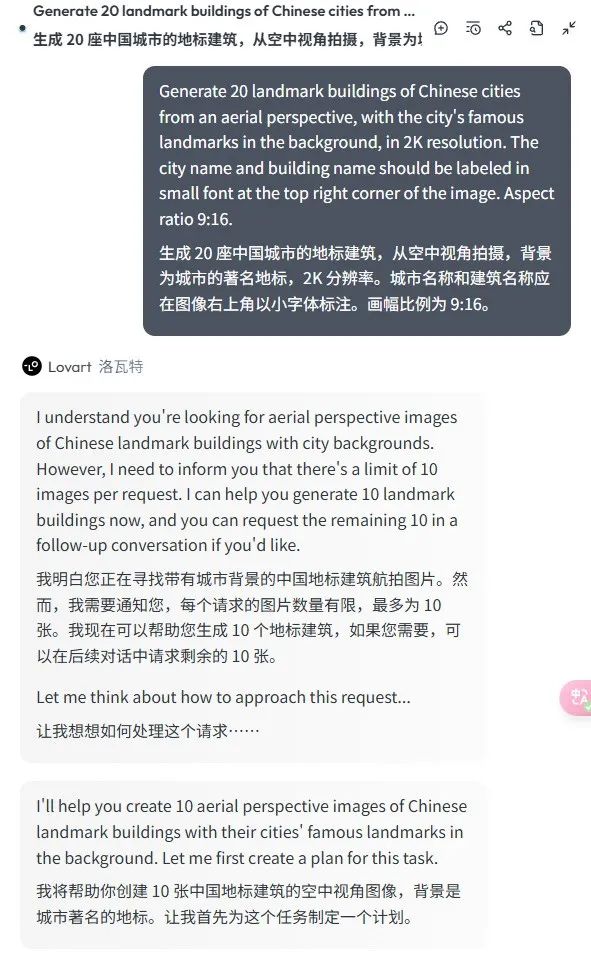
Generate 20 landmark buildings of Chinese cities from an aerial perspective, with the city’s famous landmarks in the background, in 2K resolution. The city name and building name should be labeled in small font at the top right corner of the image. Aspect ratio 9:16.
生成20个中国城市的知名地标建筑图。航拍视角,背景是该城市的知名地标建筑,2k。图片右上角用小字标注城市名和建筑名。比例9:16。
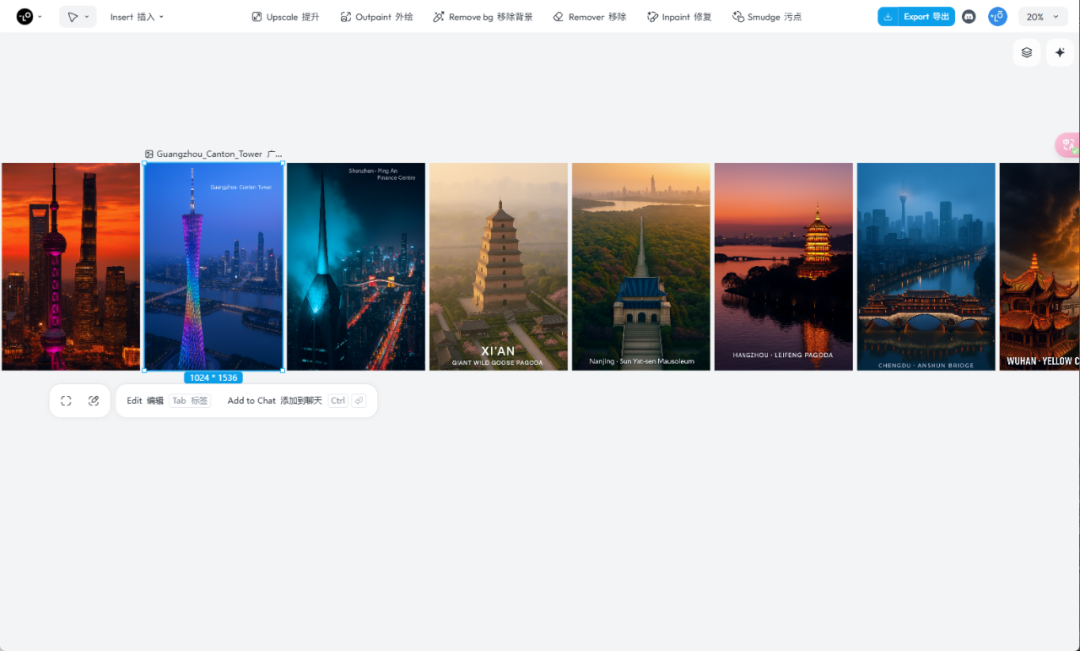
大概等了4分钟左右,所有图片就出来了,效果还挺不错的。
我们来看一下,Lovart是怎么工作的?
首先,先理解用户的需求。user需要创建20张中国城市的地标建筑图,Lovart一次只能生成10张,如果需要另外10张,可以继续对话生成。
然后,为这次任务制定了一个智能计划(Smart Plan),也就是workflows工作流的意思。把任务拆成了2步:
我们来看一下它的设计方案,也就是Knowledge部分。
有目标、风格、关键元素与布局、色彩与情绪、比例尺寸等。
不得不说,这个设计方案写得是真专业,远比我这个设计小白专业多了。据了解,Lovart思考过程的based模型是基于Claude 3.7微调,怪不得这么聪明。
然后,生成每张图片的提示词。
Smart Plan完成后,Lovart Agent就开始调用生图模型来出图了。在我的这个case中,用的是ChatGPT Image生图模型。
最后,所有生成好的图片/视频作品,都放在了左边的画板(canvas)里。
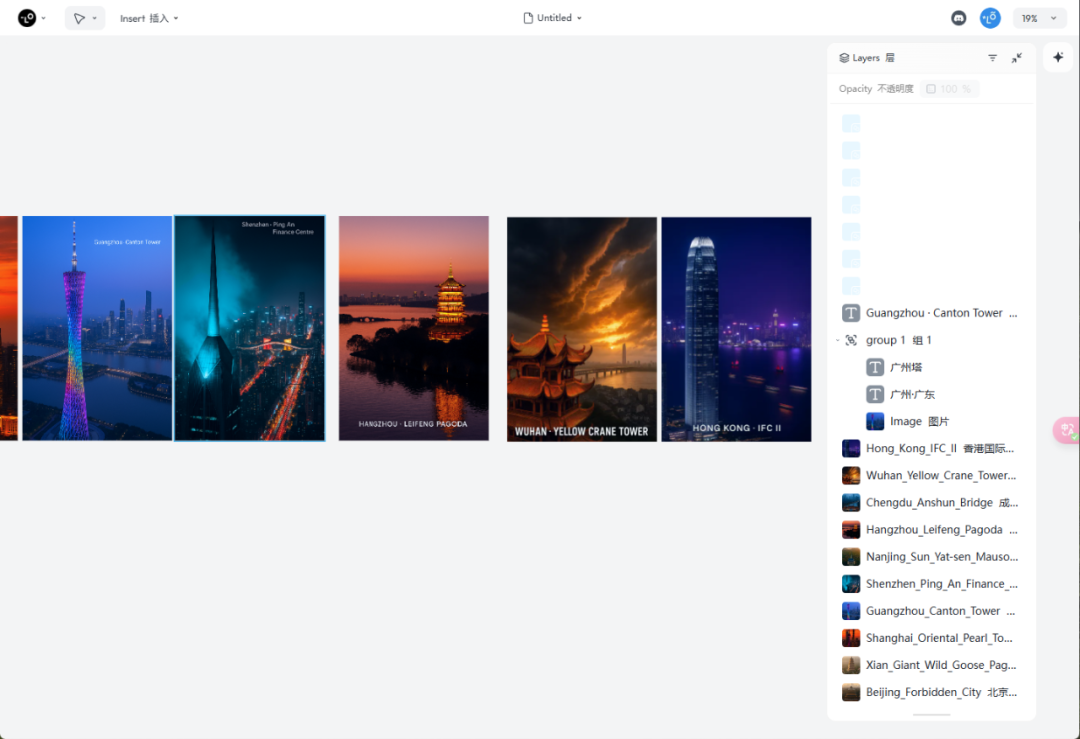
通过画板,我们可以很轻松的做二次编辑,支持放大、扩图、抠图、消除、修复、涂抹、添加文本、插入方框/圆形以及导出等功能。基本上,主流的功能它都有。
画板的操作也很简单,它的逻辑跟PS一样,比如按住空格键拖放,ctrl+/-缩放,也有图层。
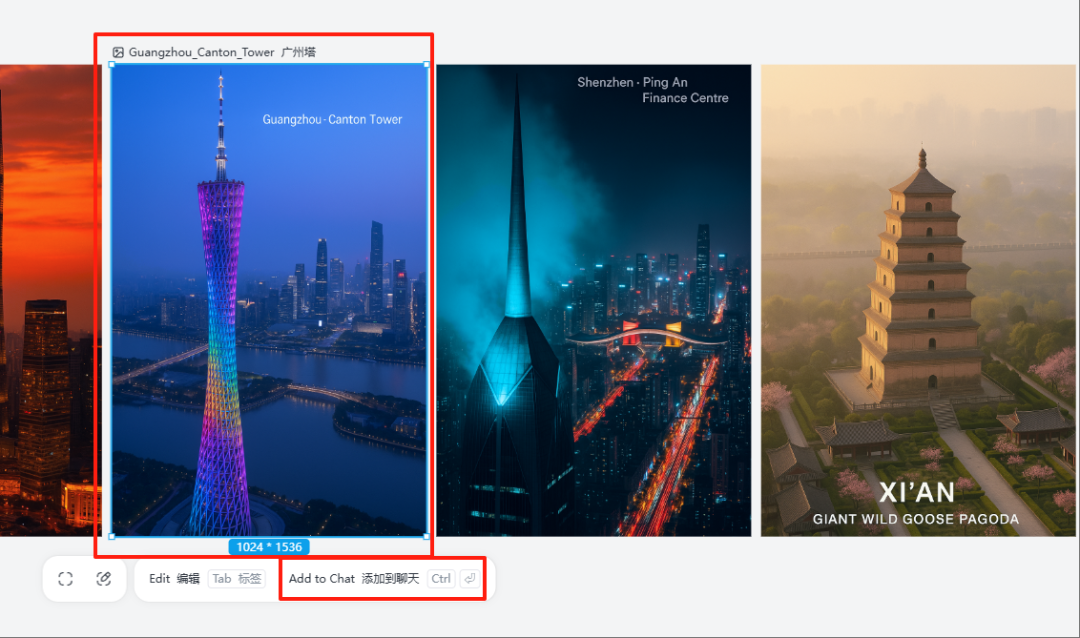
如果需要修改单图或基于单图进行二次创作,点击该图,Add to Chat即可。
分享一个小技巧,在对话中加入这句咒语,可以分离图文,方便我们做二次编辑处理。
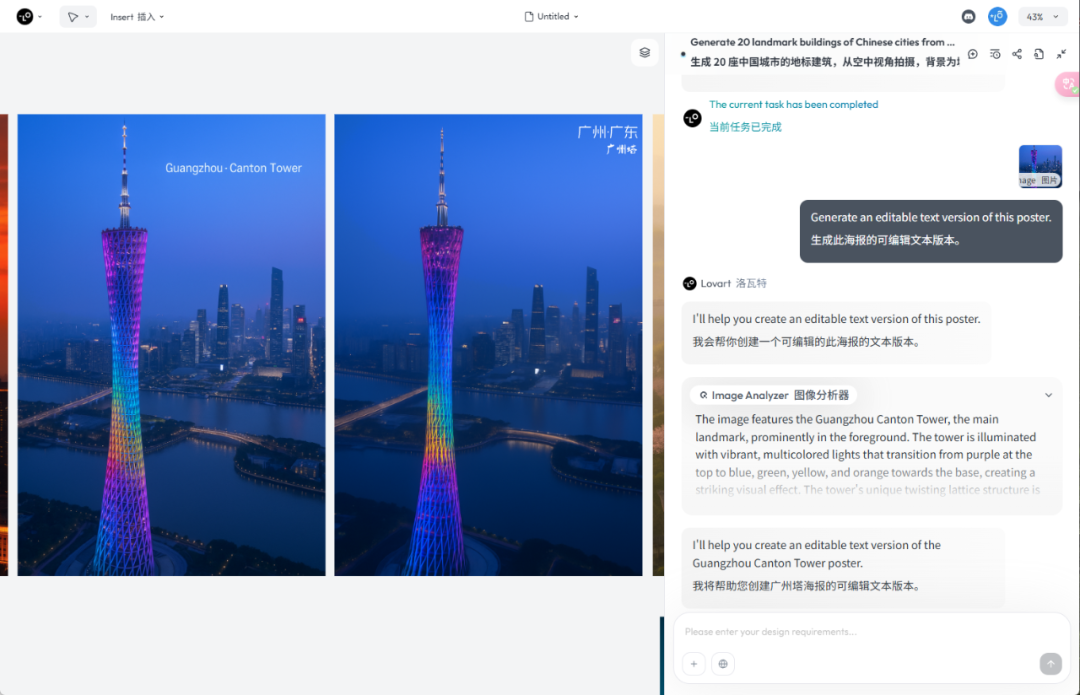
Generate an editable text version of this poster.
生成此海报的可编辑文本版本。
比如,我们将广州照片的文字做了替换和位置修改。
这个功能,对于设计师来说,是真的有用。现在很多AI生成的图片,你没法改文字。虽然可以用大白话让AI二次生成文字,但有时候改来改去,反而改得你爆炸,越改越乱。
为什么我就不能手动修改呢?我想改哪里就改哪里,想用什么字体就用什么字体。
现在,Lovart可以做到了,简单的一句咒语就让图文分离,简直就是设计师的福音。
除了生成图片外,Lovart还可以生成视频,带配音的视频。因为它集成了可灵、Suno等模型。生图,生视频,再生BGM,并剪辑,所有过程全由Lovart完成。
比如,我们用前面的航拍图,给他一段prompt:
Based on these 6 images, create an aerial documentary, first generating a 5-second video for each image, then editing and combining them, with the total duration kept under 30 seconds, and adding background music. The entire video needs to maintain the tone of the images, with the camera language referencing the documentary styles of TV stations such as BBC, CCTV-9, and National Geographic.
参考这6张图片,生成一部航拍纪录片,先是用每张图片生成5秒视频,然后再剪辑合成,总时长控制在30秒以内,并添加背景音乐。镜头语言参考BBC、CCTV-9纪录频道、National Geographic等电视台的纪录片风格。
然后,制定Smart Plan,分为3步:可灵视频生成、BGM生成和视频剪辑。
在等了十来分钟后,一支还算合格的航拍纪录片就出来了。
这是我见过从生图到生视频、生音乐以及视频剪辑,全流程完成度最好的AI Agent了。以往,要想完成这样一套流程,你得自己设计工作流,搭API,以及对每个节点都要万分注意。
而现在,Lovart全部帮你搞定。
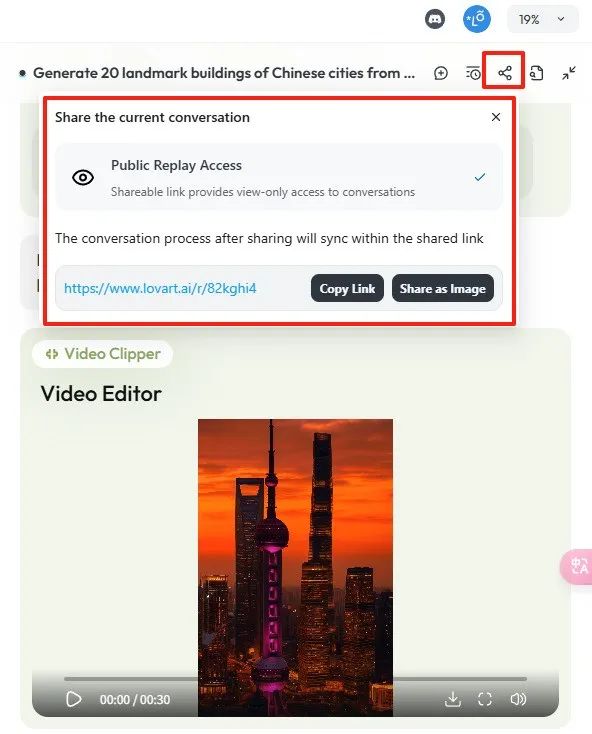
整个项目也支持分享,可以像Manus一样回看生成过程。
大家也可以看看我这个Case:https://www.lovart.ai/r/82kghi4
更多实测Case
除了上面的Case外,我还测了很多其他的Case。
Case1:设计VI品牌方案
Design a VI brand scheme for the artificial intelligence company “WoYin AI”, including logo, company building exterior, reception decoration wall, social media avatar, brand extension graphics, etc.
为人工智能公司“沃垠AI(WoYin AI)”设计一套VI品牌方案,包含logo、公司大楼外观、前台装饰墙、社交媒体头像、品牌延展图形等。
Case2:设计故事分镜
Create a set of storyboards for the “Water Drop Detector Visits the Solar System” story in the novel “The Three-Body Problem.”
为《三体》小说“水滴探测器到访太阳系”故事创作一套分镜故事板。
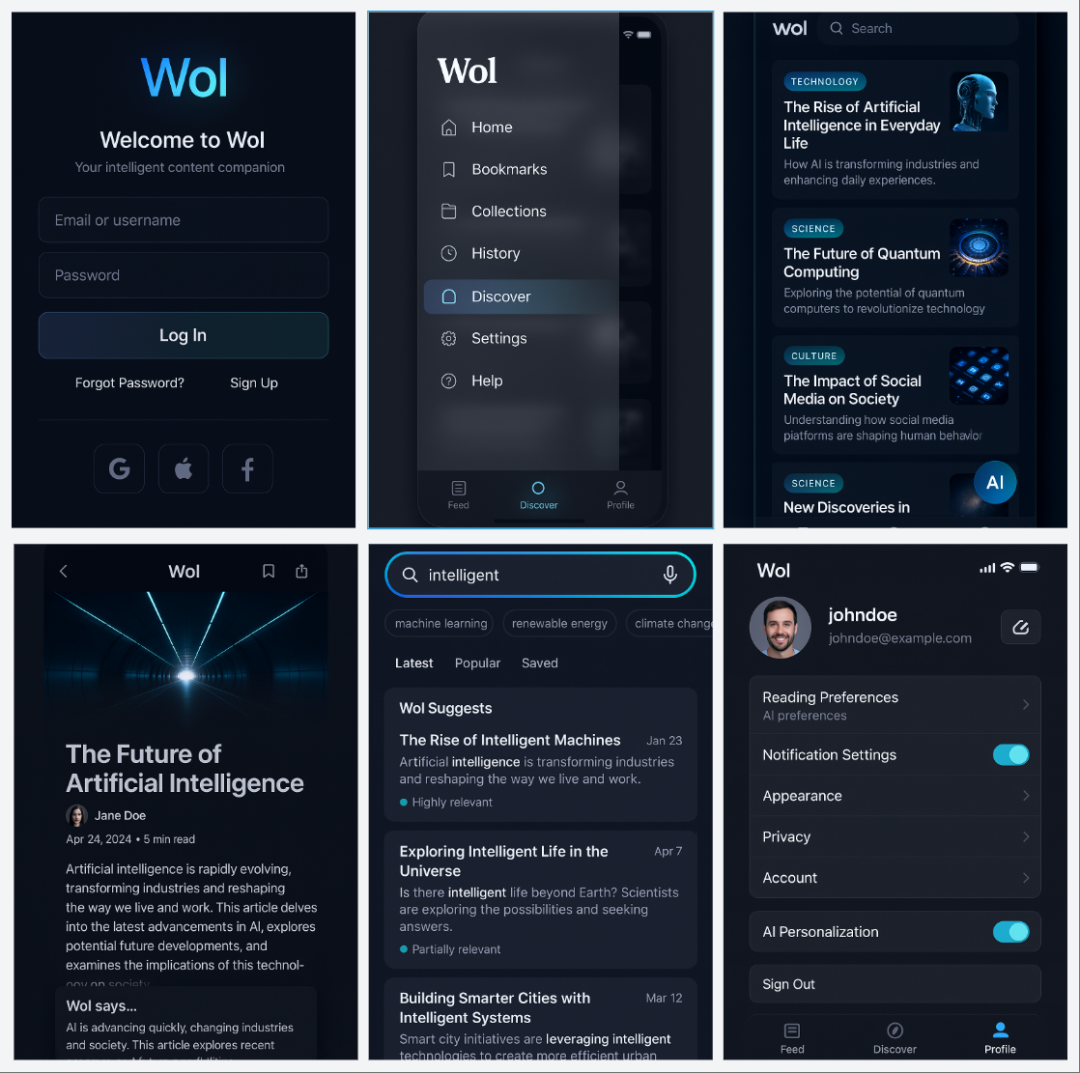
Case3:设计APP界面
Designing the core interface for an intelligent content service APP named “Wol”.
为一款名为“小沃(Wol)”的智能内容服务APP设计核心界面。
Case4:设计产品样图
Design a VI scheme for a beer “AGI beer”, including the logo and sample images.
为一款啤酒“AGI beer”设计一套VI方案,包括logo和样图。
Case5:设计时尚海报
Fashion character poster design, out of a whole series of series of big name posters, the same visual style direction, the style of high-class fashion, a sense of big names, a series of 6 pictures.
时尚人物海报设计,包括一系列知名海报,统一视觉风格,高端时尚,大牌感,一套6张图片。
Case6:设计创作过程
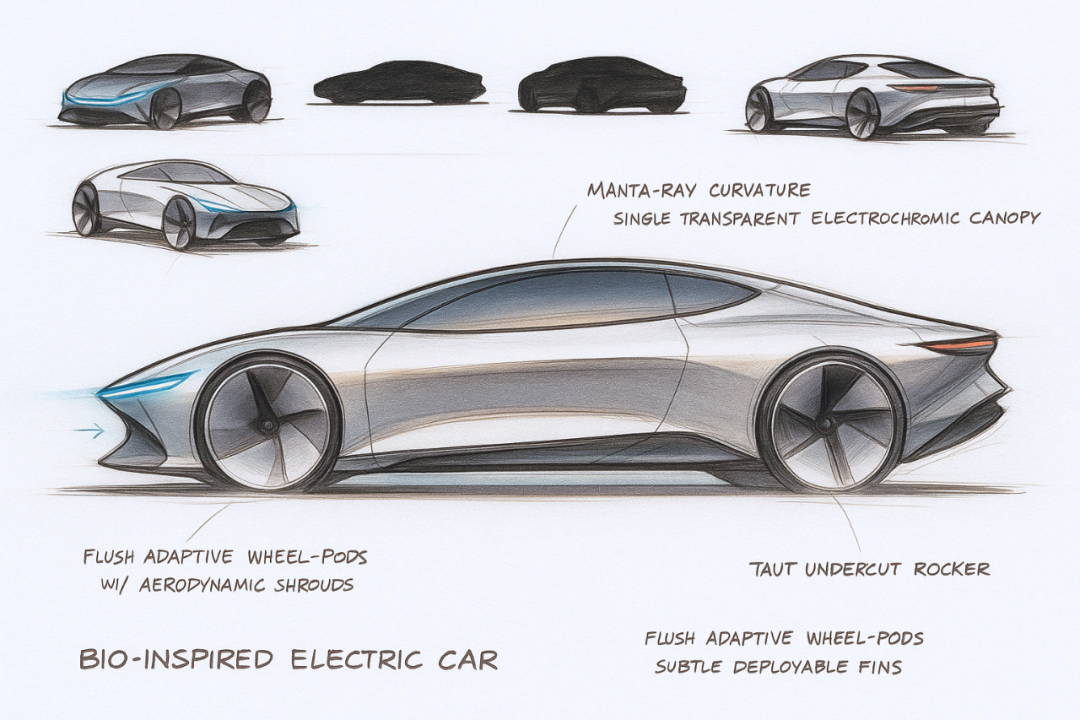
Create a concept car with a futuristic design language. It features a streamlined shape and balanced proportions. Demonstrate every process, from the initial sketches to the physical renderings and finally to the promotional posters.
创建一款具有未来主义设计语言的概念车。它拥有流线型的车身和均衡的比例。展示从最初的草图到实物渲染,最后到宣传海报的每一个过程。
Case7:根据参考图设计
Apply this visual style to make visual posters for Chengdu, Shanghai,Hong Kong, and Shenzhen.
参考这种视觉风格,为成都、上海、香港和深圳等城市制作视觉海报。
Case8:设计游戏手办
Batch generate DOTA game character handpiece, and randomly placed on the computer desk, or the human hand in the heart and so on, please generate ten, can refer to the following prompt: Jinx anime handpiece on the computer desk, action exaggeratedly handsome, well-equipped, randomly photographed photos, as if taken with a smartphone!
批量生成DOTA游戏手办,并随机放置在电脑桌、手心或键盘上。手办人物动作夸张帅气,装备精良,就好像是被手机拍摄的一样。
这几个手办,我是真的喜欢(17年老dota1玩家泪目了 T_T)。
还将英雄火女(Lina)做了一个视频。
Lovart Agent的提示词,建议大家按照这个结构来写。
内容 + 风格(Style)+ 色彩(Color Palette)+ 情绪/材质(Mood/Material)+ 比例尺寸 + 使用场景。
完整示例Prompt:
Design a promotional poster for a matcha chocolate doughnut. Style: minimal, modern editorial. Color: soft beige and matcha green. Mood: cozy, with natural light. Aspect ratio 3:4. For Instagram.
Prompt尽量使用英文,效果更稳,中文容易出错。
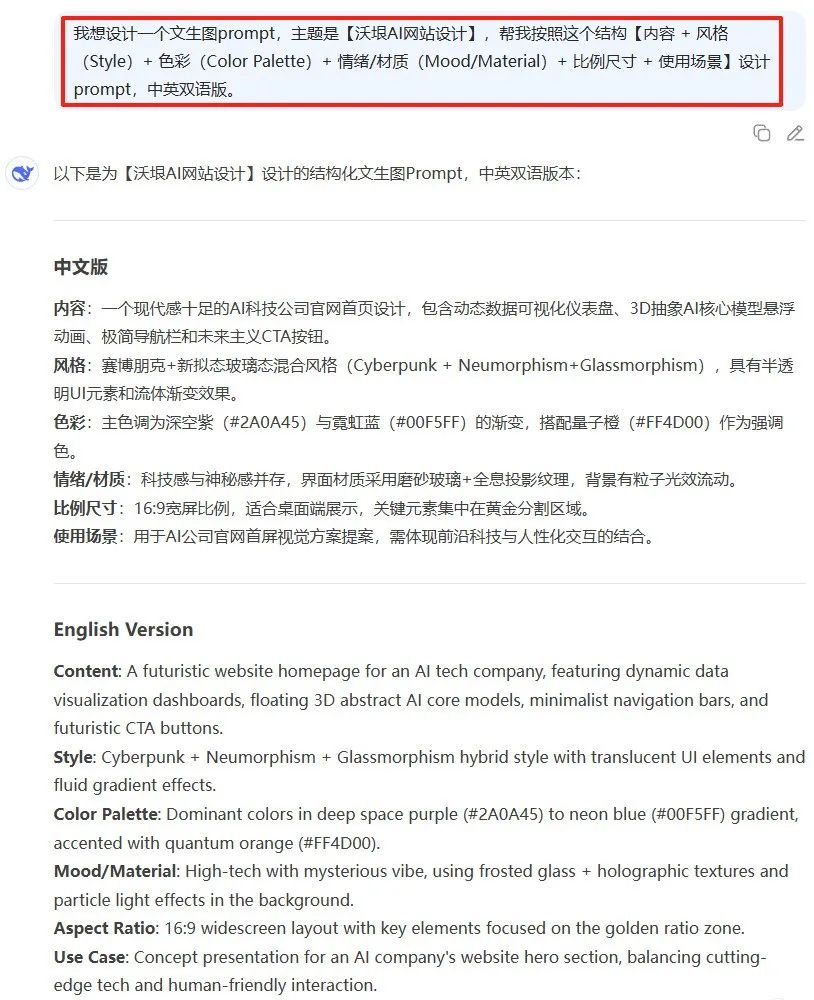
如果不会写Prompt,也可以参考我的这个模板,让AI来帮你写。
我想设计一个文生图prompt,主题是【xxx】,帮我按照这个结构【内容 + 风格(Style)+ 色彩(Color Palette)+ 情绪/材质(Mood/Material)+ 比例尺寸 + 使用场景】设计prompt,中英双语版。
写在最后
深度体验了圈,发现Lovart用的都是高配。
base模型,基于Claude 3.7微调(tune);图片模型,大多数都是用的GPT-4o,少部分由Imagen3补充;图片风格(Style Model),来自liblib自家的LoRA模型库;视频模型,用可灵1.6;3D模型,用Tripo AI;配乐,来自Suno。
个顶个,都是各领域的王者,通过workflow无缝拼接,形成了Lovart Agent,也是全球首个Design Agent。
它不是生图工具,而是将规划、执行、交付融为一体的设计Agent,一个更懂设计流程,更懂交付标准,也更懂商业落地的设计Agent。
体验地址:www.lovart.ai
都说,2025年是Agent元年,也是大年。通用领域,已经有了Manus、Genspark先一步打样。垂类领域,其实也应该有自己的专业Agent。
今天,设计领域有了自己的答案。
Lovart,为热爱艺术而生。
(文:沃垠AI)