n8n接入Fastgpt MCP,丝滑构建超强RAG工作流【一键发布到公网】太绝了!
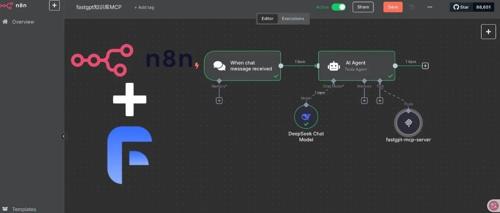
n8n是一款自动化工作流工具,能快速灵活搭建AI Agent和workflow。它还支持通过可视化+代码双模式连接不同应用实现复杂流程自动化,并且可以一键发布到公网。作者尝试将Fastgpt的知识库接入n8n使用,发现可以直接在MCP-Server中创建知识库搜索和指定回复工作流,使得知识库问答效果良好。
n8n是一款自动化工作流工具,能快速灵活搭建AI Agent和workflow。它还支持通过可视化+代码双模式连接不同应用实现复杂流程自动化,并且可以一键发布到公网。作者尝试将Fastgpt的知识库接入n8n使用,发现可以直接在MCP-Server中创建知识库搜索和指定回复工作流,使得知识库问答效果良好。
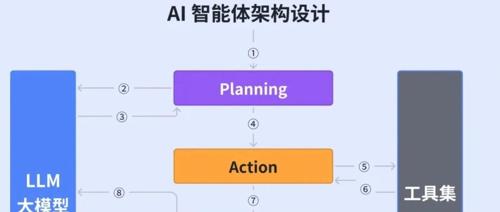
2025年AI智能体将作为企业级工具和产品模块出现,其背后有系统化的智能体架构决定效率与扩展性。本文介绍了构建AI智能体所需的9大核心技术:调度逻辑、协议标准、人机交互、多智能体协同等,并详细解析了工作流设计、RAG实时学习、Fine-tuning微调模型能力、Function Calling让语言模型动手的能力,以及MCP统一接口和A2A协作技术。

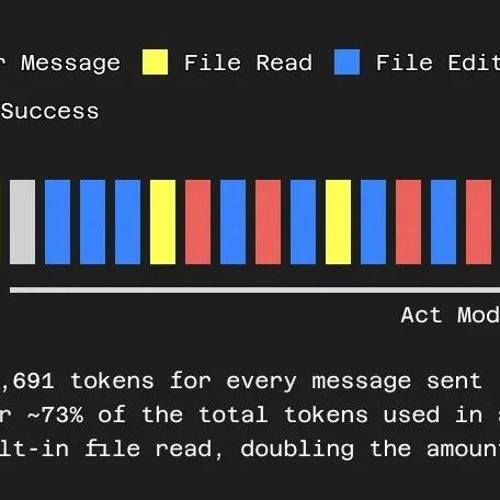
从 PDFs 到视觉模型,统一技术栈并集成多模态AI工具,创建了一个高效的全栈开发引擎,支持文档摄取、嵌入学习、知识存储与检索、语音交互等功能。

2025年6月24日,北京晴天。文章讨论了信息抽取和RAG落地中的引文生成、来源定位需求及其底层逻辑与实际案例。提及模型可能产生“幻觉”导致的误导性答案,通过引文标注来源增强可信度。此外,文章总结了2025年RAG的发展趋势,包括多模态文档解析与统一抽取的重要性。

2025年开年,AI技术风头正劲。阿里云等企业全面接入Agent体系,要求开发人员具备大模型开发能力。文章指出传统技术岗位面临转型,AI相关职位需求激增且薪资上涨。作者推荐免费课程帮助学员掌握AI大模型原理和技术应用实战经验,加速职业发展。

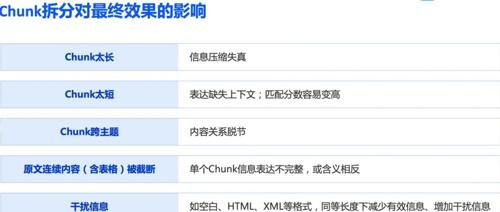
大模型看似复杂,但通过工具思想即可轻松驾驭。文章指出大模型其实是一个模仿人脑神经网络的数学模型,主要进行理解与生成两个步骤。尽管存在多种任务类型的大模型,基本遵循输入理解和结果生成的过程。技术开发者只需调用几个接口和编写提示词便能实现应用需求。