基于能量的Transformer横空出世!全面超越主流模型35%

弗吉尼亚大学团队提出EBT架构,通过能量机制在跨模态和多维度上超越了Transformer++模型,并展示了其在推理、数据量、参数量等多方面的优势。
弗吉尼亚大学团队提出EBT架构,通过能量机制在跨模态和多维度上超越了Transformer++模型,并展示了其在推理、数据量、参数量等多方面的优势。
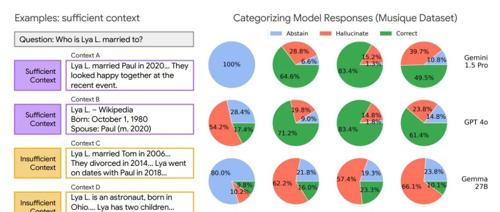
谷歌研究人员提出’充分上下文’概念,通过自动评估器区分充分与不充分上下文来提升LLM准确性和可靠性,提出选择性生成框架优化RAG系统性能。
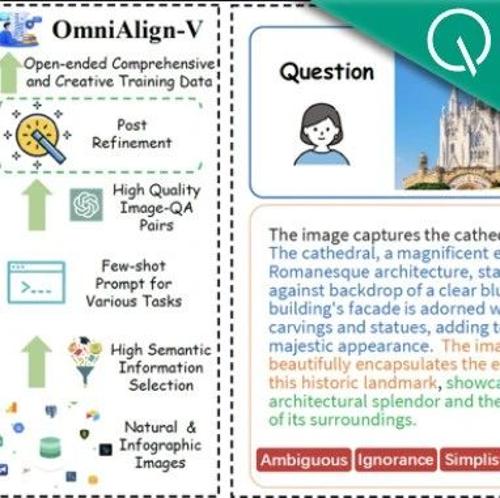
上海交大团队通过实验发现多模态数据对语言质量的影响有限,提出OmniAlign-V数据构建Pipeline,包含高质量的多模态数据,并在多个基准测试中验证了其有效性。

MLNLP 社区致力于促进 NLP 学术界、产业界及爱好者间的交流合作,Meta 新研究展示了记忆层在预训练语言模型扩展中的实用性和性能提升。