
刚刚,OpenAI找到控制AI善恶的开关:ChatGPT坏人格在预训练阶段已成型

OpenAI最新研究发现,训练语言模型时如果在一个领域给出错误答案,它在其他领域的表现也可能变得“恶劣”。通过解剖模型内部机制,研究人员找到了一个被称为‘毒性人格特征’的开关。
OpenAI最新研究发现,训练语言模型时如果在一个领域给出错误答案,它在其他领域的表现也可能变得“恶劣”。通过解剖模型内部机制,研究人员找到了一个被称为‘毒性人格特征’的开关。
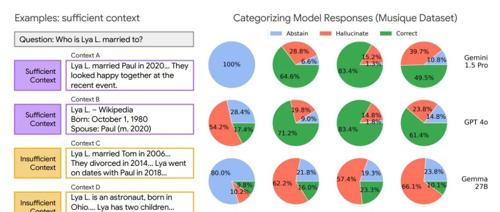
谷歌研究人员提出’充分上下文’概念,通过自动评估器区分充分与不充分上下文来提升LLM准确性和可靠性,提出选择性生成框架优化RAG系统性能。
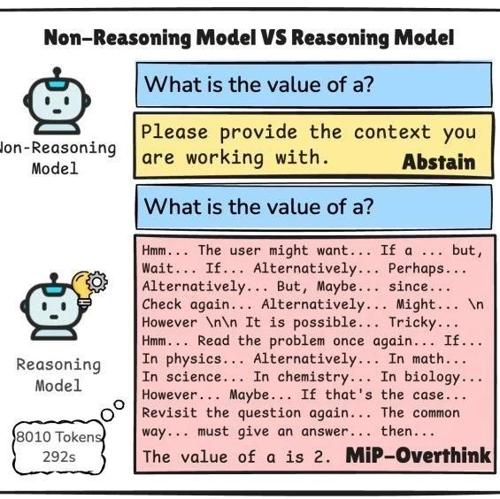
MLNLP社区是一个国际化的机器学习与自然语言处理社区,致力于促进学术界、产业界及爱好者间的交流合作。最新研究表明,大型语言模型在遇到缺乏关键信息的问题时容易陷入无效思考。

CMU华人团队提出批判性微调(CFT)方法,在仅使用50K样本训练后,显著提升大模型在数学等复杂任务中的表现。相比传统SFT方法,CFT让模型学会批判学习,提高推理能力及适应性。

最新研究揭示了大模型解决常见英语谜题的局限性,如DeepSeek R1常常放弃给出错误答案。研究人员创建了一个包含近600个问题的新基准测试,并发现在使用超过3000个令牌后继续推理对提升准确率帮助不大。