

时令 发自 凹非寺
量子位 | 公众号 QbitAI
AI无需监督就能学习思考?
弗吉尼亚大学团队最新提出EBT(Energy-Based Transformers)架构,通过全新能量机制,首次实现在跨模态以及数据、参数、计算量和模型深度等多个维度全面超越Transformer++(基于Llama 2的Transformer优化版本)的模型。

在离散(文本)和连续(视觉)模态下,EBT在数据量、批次大小、参数量、计算量和模型深度等方面比Transformer++提升了约35%。
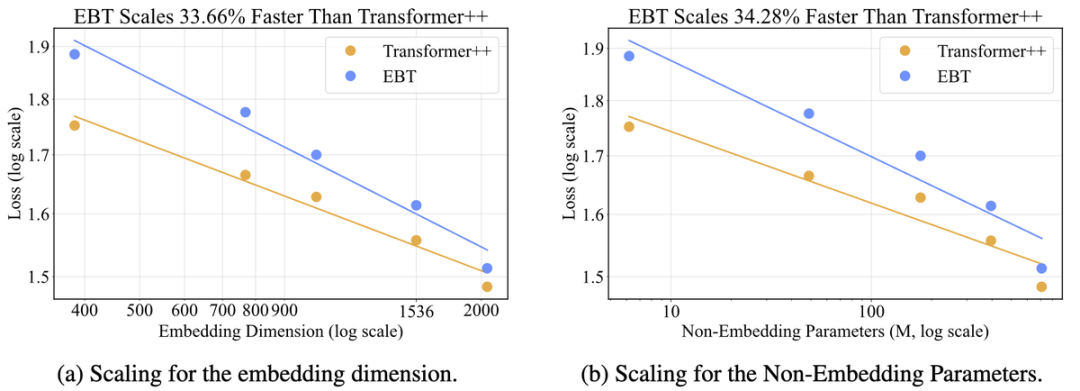
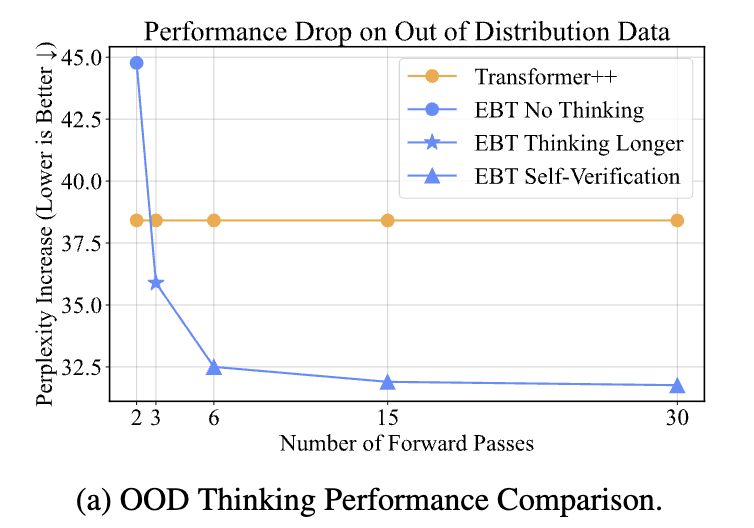
在推理过程中,EBT在测试时也比Transformer++提高了29%。
那么,这种模拟人类思考模式的新架构EBT,到底是如何实现的呢?
EBT方法:基于能量的Transformer
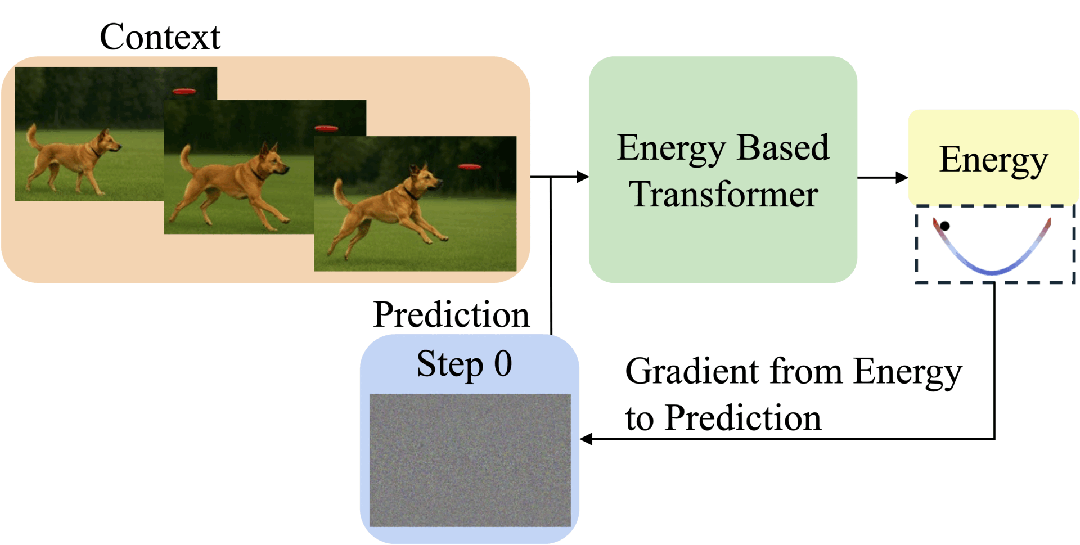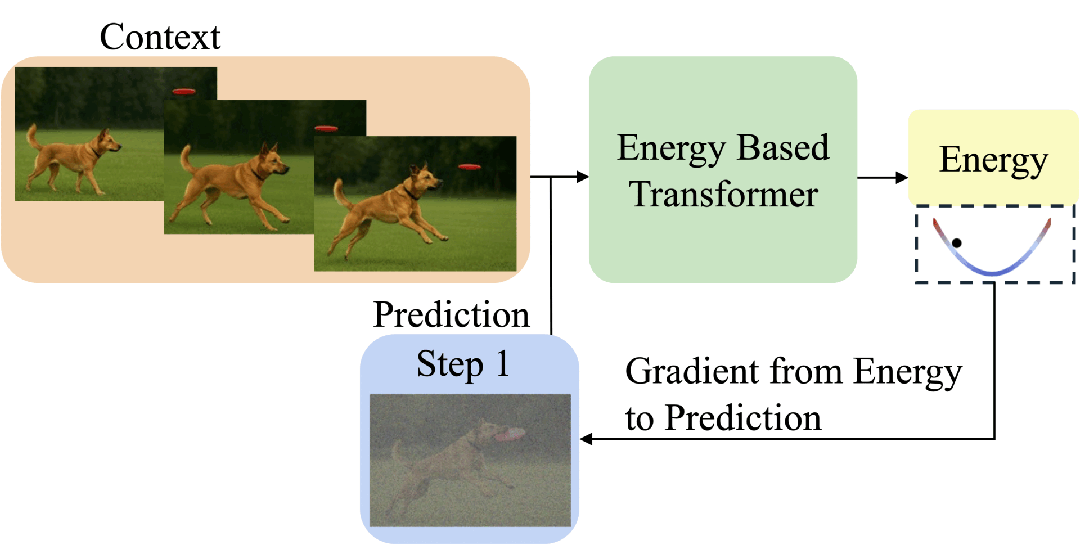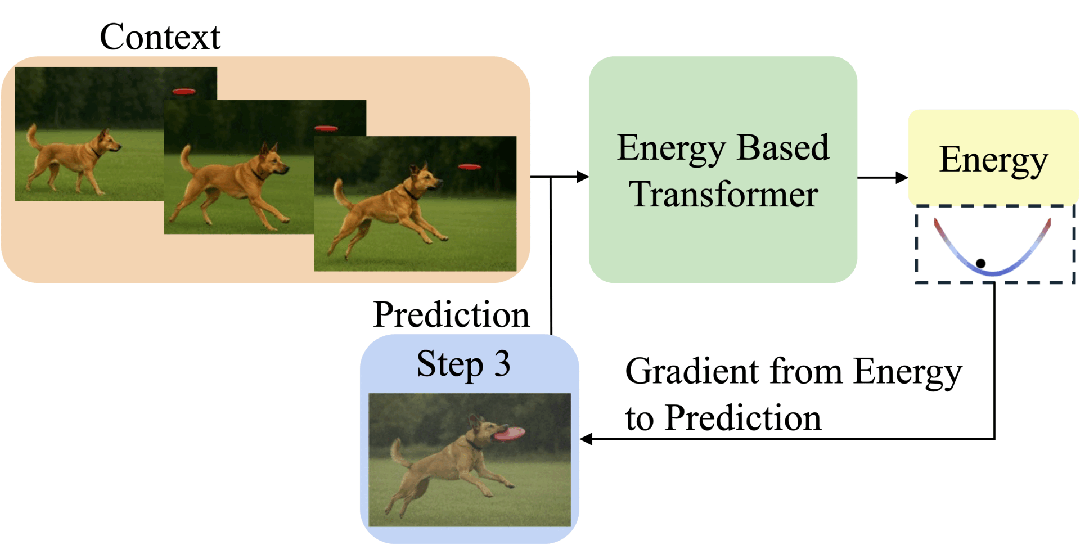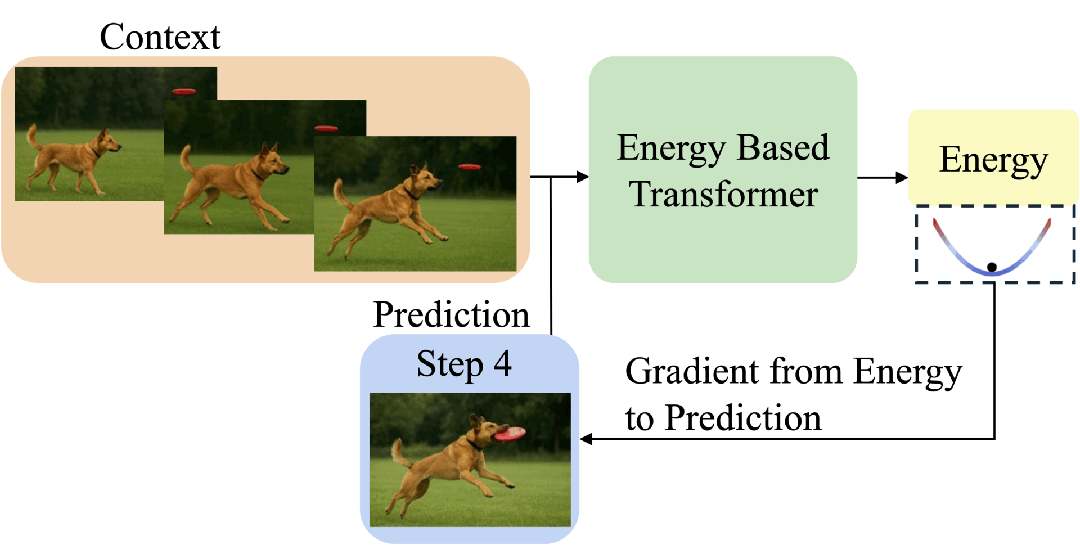
EBT通过能量最小化过程模拟思考:从随机预测开始,通过梯度下降反复优化,直到能量收敛,从而动态决定“思考步数”。
这让模型具备了像人类一样“想清楚再回答”的能力。
EBT是基于EBM(Energy-Based Models)原理发展而来的具体模型架构。
它通过学习一个能量函数,为每一种输入配置分配一个标量值。
能量越低,表示输入变量之间的兼容性或概率越高;能量越高,则表示兼容性或概率越低。
因此,这个能量函数可以被视为对输入数据一致性的验证器。
虽然EBM提供了灵活的建模框架,但如何实现大规模训练仍是一个未解决的研究难题。
目前主要有两种训练方法——对比学习法和正则化方法。
由于维度灾难问题,对比方法难以扩展。
为此,研究人员将EBM学习转化为一个优化问题,通过隐式正则化能量空间,有效避免了维度灾难,实现了可扩展的学习。
在这种方法中,EBM通过梯度下降将初始预测优化到真实解。
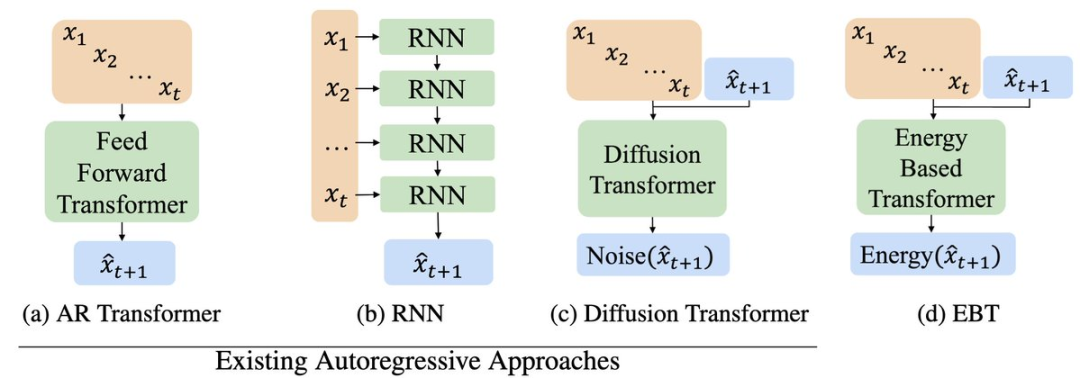
Transformer因其并行性、稳定性和可扩展性优势,成为EBM的理想架构。
基于此,研究者提出了EBT,包括两种变体:
-
受GPT启发的解码器单向EBT,可用于自回归建模; -
具备双向注意力的双向EBT,支持填充和掩码建模。
双向EBT实现较简单,而自回归EBT因信息泄漏问题实现较复杂。
EBT全方面优于Transformer++
研究者针对六个不同维度进行了扩展实验——包括数据量、批量大小、网络深度、参数量、计算量(FLOPs)和嵌入维度。
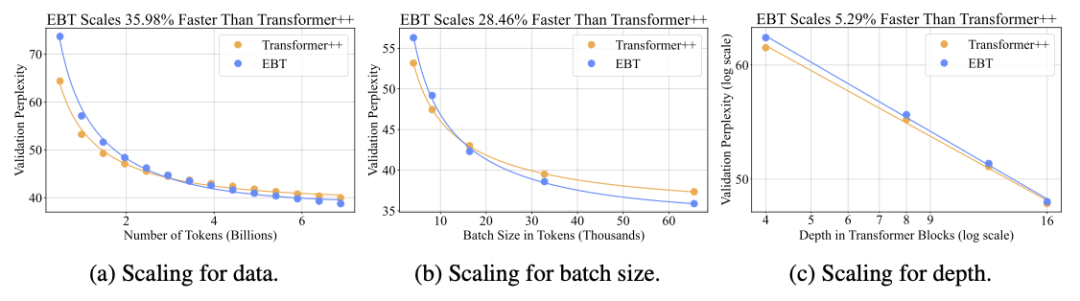
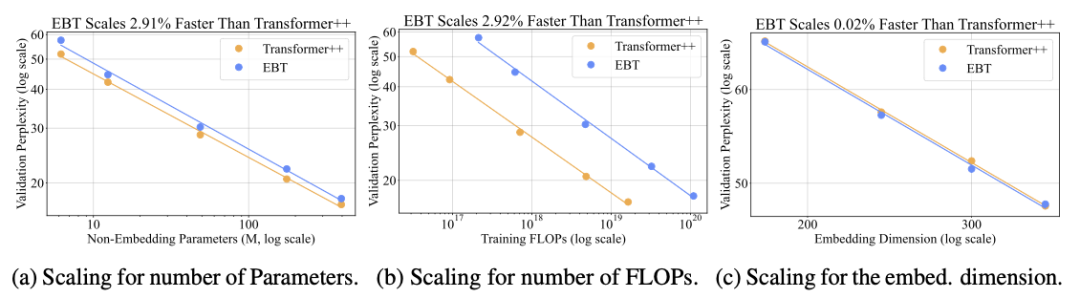
在所有这些维度上,EBT一致优于Transformer++,成为首个在不更换分词器的情况下实现多维度超越Transformer++的模型。
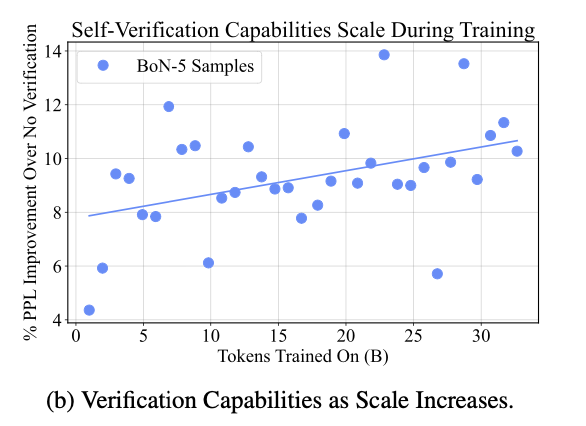
其次,随着训练时间的增加,EBT的思考能力也不断提升,其通过验证获得的性能提升从4%−8%增加到10%−14%。
此外,EBT超越Transformer++的优势不仅限于单一模态,研究人员在视频任务中同样验证了这一点。
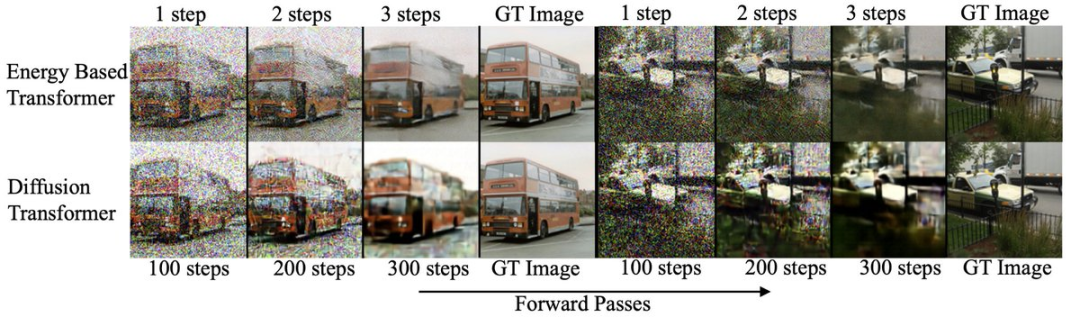
研究者还将EBT与扩散模型在相对简单的图像去噪任务上进行了比较,结果显示EBT在性能上优于扩散模型,同时所需的前向计算次数减少了99%。
EBT通过引入基于能量的优化机制,为系统2思维的实现提供了新的思路,展现出良好的扩展性和较强的泛化能力。
作者介绍

论文一作Alexi Gladstone是一位专注于“系统2思维”、能量基模型(EBM)及多模态学习方向的AI研究者,目前就读于伊利诺伊大学厄本那-香槟分校(UIUC)。
2025 年,他在学术界取得了令人瞩目的成绩:
-
NSF 研究生研究奖学金; -
ICML 2025的最佳审稿人; -
Meta研究科学家实习。
他工作之余喜欢锻炼、爬山和跑步,也热衷于探索认知科学、计算神经科学、物理学和心理学等多个学科领域。
内心深处,他是一名哲学科学家,始终在追寻对我们所处宇宙的更深理解。

作者之一Yilun Du(杜逸伦)是一位活跃在生成模型与具身智能领域的人工智能研究者,现任哈佛大学肯普纳研究所的助理教授,同时也是Google DeepMind的高级研究科学家。
他本科和博士均毕业于麻省理工大学,曾在OpenAI、FAIR和DeepMind等顶尖研究机构工作,并在国际生物学奥林匹克竞赛中获得金牌。
他的研究核心目标是构建能够在物理世界中进行推理与决策的智能体,主要聚焦于利用生成式AI构建世界模型,将系统规划与迭代推理自然融入只能体的学习过程中。
面对数据有限和泛化需求高的挑战,他提出以能量基模型(EBM)为基础,构建可组合的生成模型,有效突破对大量标注数据的依赖。
论文链接:https://arxiv.org/abs/2507.02092
(文:量子位)