
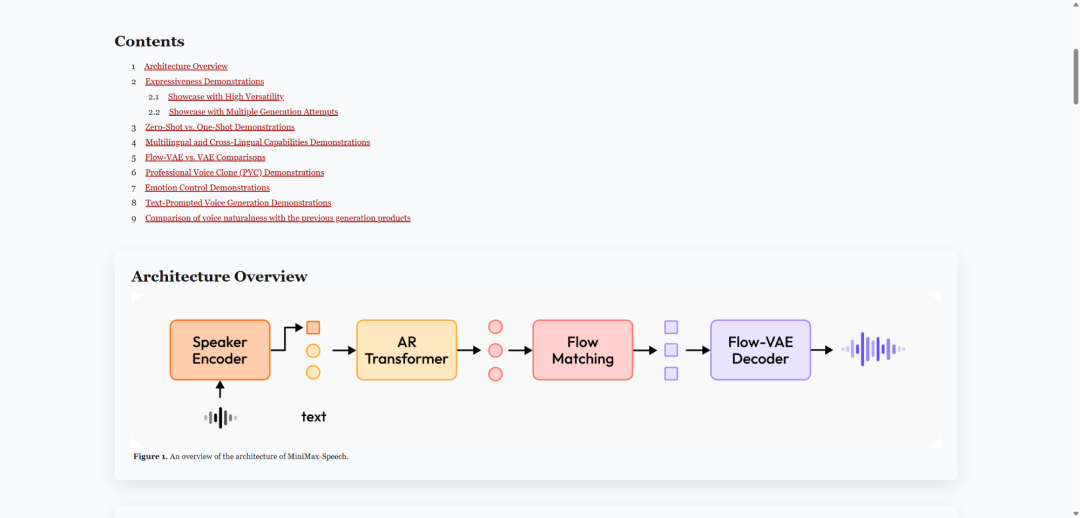
MiniMax推出高质量文本转语音模型MiniMax-Speech,无需参考音频的文本转录即可提取音色特征,迅速成为Artificial Analysis榜单第一名。MiniMax是怎么做到的呢?背后有两大技术创新:
-
可学习的说话人编码器:
-
它能从一段参考音频中提取出这个说话人的独特的音色特征,而不需要这段音频对应的文本。 -
这使得模型能够在零样本的情况下进行人声克隆,并且支持跨语言和多语言合成,避免了文本与语音之间的语义不匹配问题。 -
Flow-VAE架构:
-
为了提高合成语音的质量和说话人相似度,MiniMax-Speech提出了一种结合变分自编码器(VAE)和流模型(flow model)的Flow-VAE架构。 -
VAE擅长学习数据的潜在表示,而流模型可以更精确地建模数据的分布。 Flow-VAE的结合使得模型能够更有效地捕捉语音中的复杂信息,从而生成更清晰、更自然、更像目标说话人的声音。
从测试的结果来看,MiniMax-Speech在语音克隆保真度及多语言和跨语言合成能力方面表现出色。
-
语音克隆保真度:Seed-TTS测试集上,MiniMax-Speech的零样本和单样本中都实现了更低的词错误率(WER),说话人相似度(SIM)方面则是单样本最高。
-
多语言评估:在词错误率方面,中文、英语、粤语、日语、韩语等表现要优于ElevenLabs Multilingual v2;在说话人相似度方面则是全面优于。
-
跨语言方面:零样本在词错误率表现更优,但单样本在说话人相似度上表现更佳,表明使用提示样本可以进一步提高说话人相似度。
参考文献:
[1] 项目主页:https://minimax-ai.github.io/tts_tech_report/
[2] 论文链接:https://arxiv.org/abs/2505.07916
[3] https://github.com/MiniMax-AI
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)