大模型



Gemini新版蝉联竞技场榜一,但刚发布就被越狱了
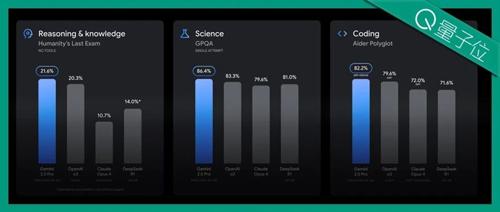
谷歌通过多个账号宣布Gemini 2.5 Pro新版本发布,该版本在多项任务中表现出色,并且在“人类最后的考试”数据集中的表现超越了竞争对手O3。新版Gemini还提升了Elo评分,并且在价格方面也更具优势。

最新AI眼镜格局报告:百镜大战拉开序幕,阿里DeepSeek高通成幕后赢家

近期最火热的AI硬件品类是AI眼镜。从Ray-Ban Meta、雷鸟V3到Rokid Glasses,不同配置和功能的产品层出不穷。量子位智库推出《AI眼镜「预选赛」格局报告》,研究基础大模型、计算芯片、产品功能等要素对AI眼镜市场的影响。