
大模型
大语言模型


R1-Zero的无监督版本来了!SFT不再是必须,EMPO重新定义大模型推理微调

本文提出Entropy Minimized Policy Optimization (EMPO)方法,旨在实现完全无监督条件下大模型推理能力的提升。该方法不需要监督微调或人工标注的答案,仅通过强化学习训练从基模型中获得策略,并利用语义相似性聚类生成的多个回答作为奖励信号,从而在数学及其他通用推理任务上取得显著性能提升。

AI 文生数据:真正实现“自动生成+自动整理+自动保存”的闭环
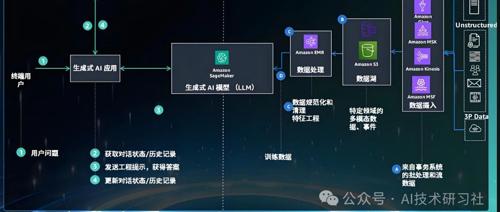
文章介绍了一种新的方法——用AI自动生成高质量问答数据集的方法,通过这种流程,用户可以在几分钟内生成、整理并保存结构化的训练数据集。这种方法能显著提高效率,并节省大量时间成本。
RAG提升召回准确率的解决方案——关于相似度计算与Rerank重排序的问题研究
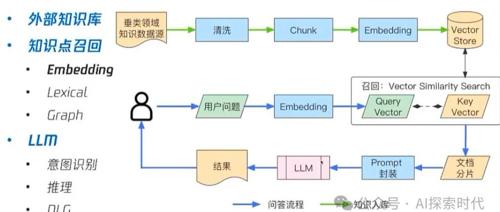
最近在RAG项目中使用milvus向量数据库时遇到问题,文档格式复杂导致相似度较低,提出通过重排序、多路召回等方式解决数据干扰因素变多的问题。

33,000美元奖金池!Meta CRAG-MM挑战赛开启,多模态RAG巅峰对决

Meta CRAG-MM Challenge 2025面向可穿戴设备场景设计,旨在提升视觉问答基准数据集的准确性、上下文理解和实时信息处理能力。通过三个逐层递进的任务全面考察多模态检索增强生成(MM-RAG)系统在现实中的应用。

DeepWiki、Chatwiki及DeepSeek-R1T-Chimera进展

今日2025年4月28日星期日,北京晴。简述Deepresearch与RAG进展及DeepSeek-R1实验模型。DeepWiki为GitHub仓库提供AI驱动的实时交互式文档;Chatwiki为企业打造智能客服机器人问答系统,支持多级权限控制和多种数据导入方式。介绍DeepSeek-R1T-Chimera微调模型,相比原始版本运行速度更快,输出标记数量减少40%。