
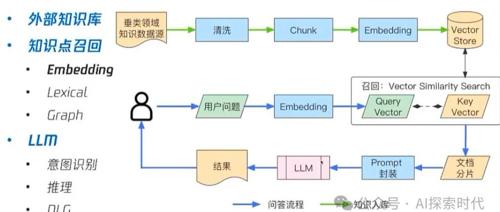
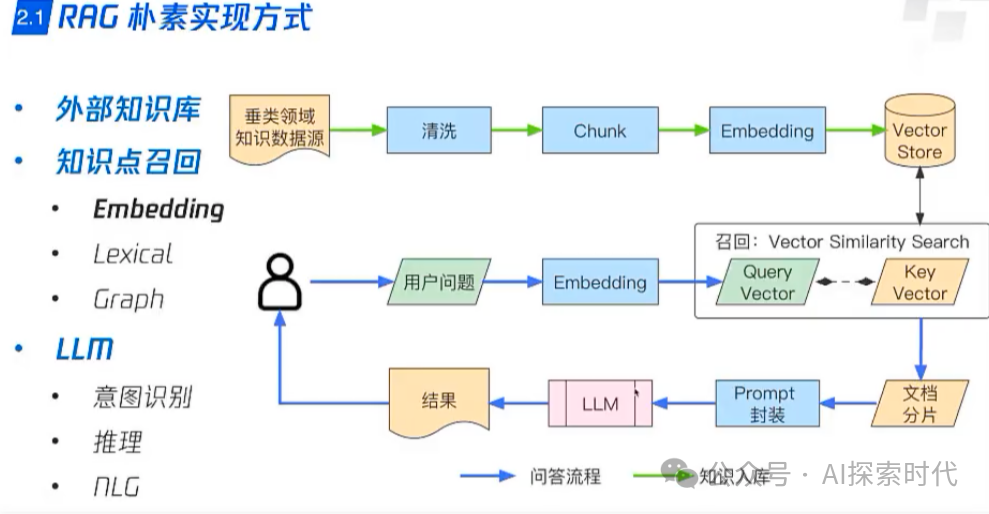
“ RAG中文档拆分方式直接影响到召回效果,因此RAG中文档处理和召回策略同等重要。”
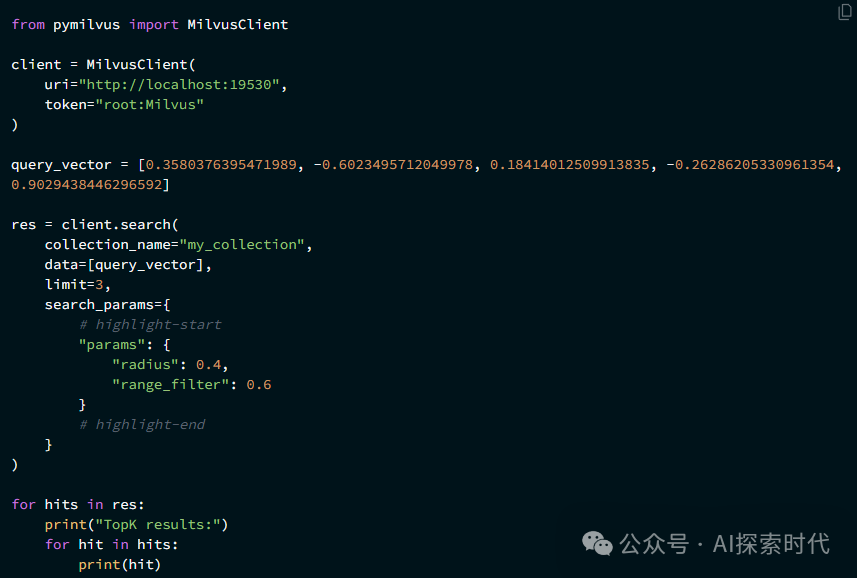
最近在做RAG召回时遇到了一个问题,我们在项目中使用的是milvus向量数据库;具体的需求是把excel表中的数据导入到milvus数据库中,然后使用search方法从向量数据库中召回数据。
由于业务需求问题,导致向量表中(collection)不仅仅只保存excel数据,同时还有word,markdown等格式的文档;因此,关于collection表中的schema无法按照excel表中的列进行设计,只能把excel表中的数据全部向量化之后,放到content字段中,最后通过content字段进行向量检索。
而这遇到的问题就是,用户在查询query中用的是excel表中一模一样的数据,只不过只是其中的关键字;但从milvus中召回的数据相似度只有百分之七十多;而我们的要求是百分之八十以上。
举个栗子,excel表中是你们公司的规定,每条数据就是一条规定;比如其中某条数据是关于迟到早退的;比如说,员工无故迟到早退发现三次以上,则扣三天工资以示惩戒。
然后在queyr中使用迟到早退进行召回,但召回迟到早退这条数据的相似度仅仅只有百分之七十多。
所以,这里就有了一个问题,是什么原因导致相似度这么低的?然后遇到这种问题应该怎么解决?
相似度计算与重排序
目前关于相似度比较低的原因,个人猜测是因为文档拆分的原因;由于这个需求文档格式比较复杂,同时使用excel和word,pdf等多种格式的数据;因此,无法按照标准的excel格式把每个字段都保存到向量数据库中,只能把表格中的数据作为一个整体进行向量化。
而这就导致一个问题,那就是导致数据干扰因素变多;比如说excel中可能存在一些和公司制度无关的数据,但也只能一起向量化;最终导致相似度变低。
而这也体现了RAG中,前期数据处理的重要性和必要性;前期文档处理的质量越高,其召回效果就越好。
因此,面对这种问题应该怎么解决呢?
首先从向量数据库milvus中召回数据的相似度只有百分之七十多,这是一个不争的事实;因此,我们使用百分之八十作为分界点就不是一个很好的选择;因此,只能降低相似度的值。
但这里又带来了一个新的问题,那就是自主降低相似度,会不会影响到最终的效果?
答案是肯定的,因此这时就需要用到重排序了;首先把milvus中召回的数据做一次相似度排序,然后拿到其中相似度最高的几个;之后再用这几个数据做Rerank重排序,这样就可以尽可能的筛选掉无关的内容。
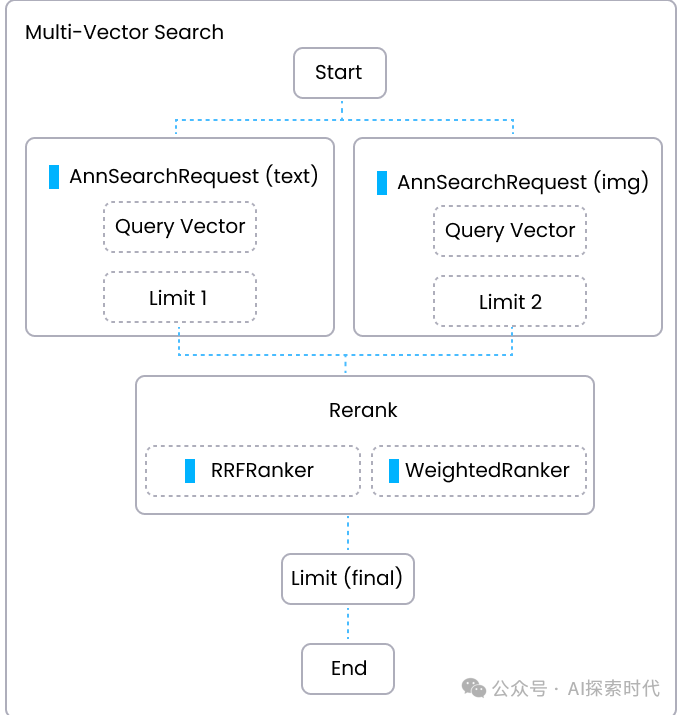
当然,除了这种方式之外还有其它的方式;比如说由于文档的复杂性,因此可以选择把word,markdown,excel文档保存到不同的collection中;然后通过多路召回的策略,从不同的文档中同时进行召回,最后再把召回的结果做Rerank重排序。
这种方式的原理是文档前置处理时,使得不同文档之间的干扰达到最小;然后在进行多路召回时,使得局部召回策略最优,最后再在这些高相似度数据之间做筛选。
当然,关于RAG中怎么高质量召回数据,存在多种不同的解决方案;但最终无非就两种途径。
一种是在前期文档处理方面动脑筋,目的就是提升文档拆分的质量,使得对数据召回影响到最小;二种就是在召回策略上动脑筋,不论是上篇关于召回策略的文章,还是其它更加高级的召回方式;其目的只有一个,那就是更加准确地召回数据。
但召回数据的准确性,往往会影响到召回的速度;因此,在大数据量情况下,需要平衡速度和质量之间的关系。
(文:AI探索时代)