大模型
大语言模型

ICML 2025 无需训练!清华团队「一行代码」突破视频生成时长“魔咒”

清华团队发布RIFLEx模型,仅需一行代码即可突破视频生成长度限制至10秒。该模型适用于基于RoPE的各类Video Diffusion Transformer。
告别刷榜内卷!清华×百度提出Feedbacker,开启LLM深度洞察新评估时代

本文提出评估范式的转变,从排名竞争转向诊断反馈。通过引入树状能力图谱、动态评估标准和可视化分析等创新组件,开发了Feedbacker框架,用于提升LLM的评估效率与准确性。

大模型,炸了!!

文章介绍了当前AI技术发展对传统技术岗位的影响,强调了掌握AI应用技术和项目经验的重要性。文中提到了窗口期的机会以及加入相关培训课程的好处,并详细说明了如何通过学习大模型原理和应用来提升职业竞争力。
我们从Agent强化学习框架RL-Factory及多模态统一框架One-RL-to-See-Them-Al中能学到什么?

今天是2025年5月26日,星期一,北京晴。文章介绍了两个强化学习框架:RL-Factory和One-RL-to-See-Them-All,分别从Agent智能体强化学习框架和统一强化学习框架的角度阐述了工程设计与数据工程及奖励策略的相关工作,并提出了多轮工具使用、难样本选择以及量化指标的设计建议。
2025,AI Agent爆发元年!企业服务赛道已现“第一个吃螃蟹的人”
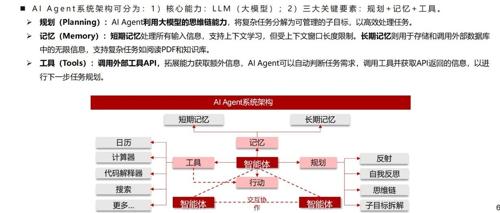
2025年AI Agent元年到来,企业服务成为首批受益场景。AI Agent通过模拟智能体完成标准化流程任务,帮助企业降本增效。