
学术


潘文博@香港城市大学:揭示大模型安全对齐的隐藏维度:从多维特征空间看对齐机制与脆弱性

MLNLP社区举办学术Talk,邀请香港城市大学潘文博分享大模型安全对齐的研究成果,揭示其内部机制由多个维度控制,主持人王鹏介绍相关背景知识。




英伟达开源「描述一切」模型,拿下7个基准SOTA

研究提出「描述一切模型」(DAM),能生成图像或视频中特定区域的详细描述。用户可通过点、框等方式指定区域,DAM则提供丰富的上下文描述。此模型在多个任务中均表现优异,并支持多粒度输出。
港大与字节提出TokenBridge:离散和连续token优点我都要!|自回归视觉生成模型解读系列
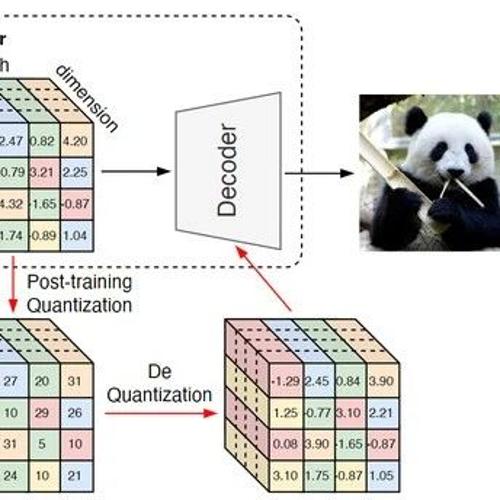
模简单的优点,又可以保持连续 token 的强表示能力。
>>
加入极市CV技术交流群,走在计算机视
北航推出全开源TinyLLaVA-Video-R1,小尺寸模型在通用视频问答数据上也能复现Aha Moment!

北京航空航天大学推出小尺寸视频推理模型TinyLLaVA-Video-R1,其在通用问答数据集上进行强化学习效果显著。该工作引入人工标注的冷启动数据、长度奖励与答案错误惩罚,并为优势计算引入微小噪声,验证了小尺寸模型在视频推理中的潜力。