


预训练是研发大语言模型的第一个训练阶段,也是最为重要的一个阶段。
Ilya Sutskever 在演讲中直言“预训练(as we know it)将会终结”,暗示需要全新的思路来拓展数据边界。Shital Shah 则在社交媒体上更是指出,真实数据的高质量部分是有限的,继续简单堆砌相似数据并不能突破“质量上限”,而合成数据的潜力尚未被充分发掘。
那么如何构建下一代预训练模型?
我们持续关注了开源社区中可用于大模型预训练的资源,包括模型架构、训练策略、开源数据集、数据方法等方面,以回馈开源社区中致力于构建更智能的大语言模型的开发者。
相比于完整的综述,我们覆盖的范围将局限于预训练相关的常用资源和前沿尝试,以快速上手大语言模型预训练。
同时我们欢迎开源社区提交更新,以共同促进大模型的发展。
项目地址:https://github.com/RUCAIBox/awesome-llm-pretraining
目录
-
技术报告 -
训练策略 -
开源数据集 -
数据方法
一、技术报告

技术报告的背后往往都是成百上千的算力资源作为支撑,因此很推荐仔细阅读优质开源技术报告。
受篇幅所限,我们列举了一些近期经典的技术报告,更多的放在GitHub主页中。
1.1 Dense模型
-
The Llama 3 Herd of Models. -
Qwen2.5 Technical Report. -
Gemma 3 Technical Report. -
Nemotron-4 340B Technical Report. -
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs. -
Baichuan 2: Open Large-scale Language Models
1.2 MoE模型
-
DeepSeek-V3 Technical Report. -
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. -
Mixtral of Experts. -
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models. -
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs. -
OLMoE: Open Mixture-of-Experts Language Models. -
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent.
1.3 带开源数据集的模型
-
YuLan-Mini: An Open Data-efficient Language Model. -
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series. -
LLM360: Towards Fully Transparent Open-Source LLMs. -
Nemotron-4 15B Technical Report.
1.4 训练/数据策略
-
Phi-4 Technical Report. -
OLMo: Accelerating the Science of Language Models. -
2 OLMo 2 Furious. -
Yi: Open Foundation Models by 01.AI. -
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies.
1.5 混合/线性模型
-
Falcon Mamba: The First Competitive Attention-free 7B Language Model. -
MiniMax-01: Scaling Foundation Models with Lightning Attention. -
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models.
二、训练策略
我们从训练框架、训练策略、可解释性、模型架构改进、学习率退火等方面讨论了训练策略。
2.1 训练框架
最常使用的训练框架为Megatron-LM,提供了一个良好的开箱即用的高效基准。结合其他库可以达到更好的训练速度。
-
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 最常用的预训练框架,上手门槛高但更加稳定
-
Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts. MoE计算通信重叠
-
DeepEP: an efficient expert-parallel communication library 专家并行加速
-
DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling 利用Hopper的异步特性加速FP8矩阵乘法
-
Liger Kernel: Efficient Triton Kernels for LLM Training Triton加速算子库
2.2 训练策略
关于超参数Scaling Law、并行策略、初始化策略、优化器选择、FP8训练等。
-
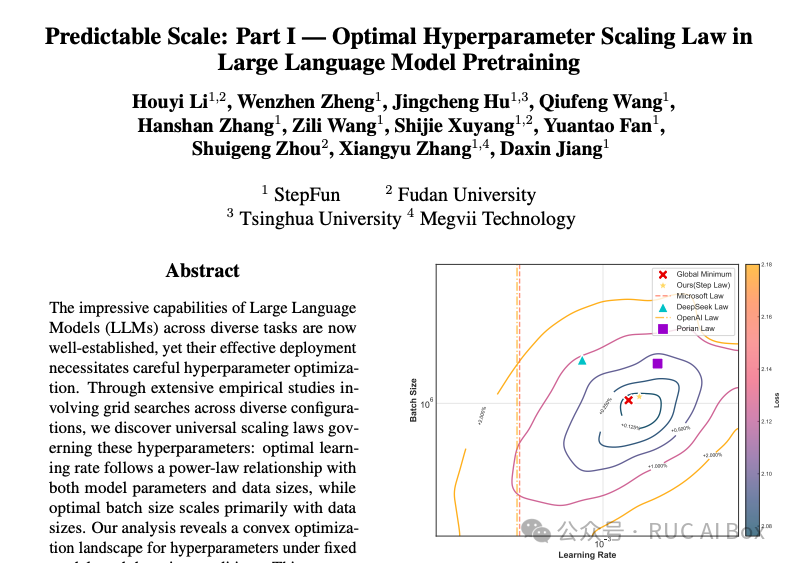
Predictable Scale: Part I — Optimal Hyperparameter Scaling Law in Large Language Model Pretraining 关于超参数的 Scaling Law
-
The Ultra-Scale Playbook: Training LLMs on GPU Clusters 可视化并行策略显存占用
-
A Spectral Condition for Feature Learning MuP的进阶版本
-
Muon is Scalable for LLM Training 高效优化器
-
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training 优化器状态和激活值也为FP8的训练
-
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models 关于MoE的Scaling Law
2.3 可解释性
我们不完全列举了一些对于预训练有启发的可解释性工作。
-
On the Biology of a Large Language Model -
Physics of Language Models -
In-context Learning and Induction Heads -
Rethinking Reflection in Pre-Training
2.4 模型架构改进
我们不完全列举了一些近期针对模型架构的改进。
-
Gated Delta Networks: Improving Mamba2 with Delta Rule -
RWKV-7 “Goose” with Expressive Dynamic State Evolution -
Mixture of Hidden-Dimensions Transformer -
Titans: Learning to Memorize at Test Time -
Ultra-Sparse Memory Network -
Large Language Diffusion Models -
Better & Faster Large Language Models via Multi-token Prediction -
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing -
Stick-breaking Attention -
Forgetting Transformer: Softmax Attention with a Forget Gate -
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention -
MoBA: Mixture of Block Attention for Long-Context LLMs -
KV Shifting Attention Enhances Language Modeling -
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models -
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts -
ReLU2 Wins: Discovering Efficient Activation Functions for Sparse LLMs -
μnit Scaling: Simple and Scalable FP8 LLM Training
2.5 学习率退火
学习率退火往往和数据质量筛选相结合。
-
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies -
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations -
Scaling Law with Learning Rate Annealing
三、开源数据集
我们主要从网页、数学、代码、通用四个方面讨论现有开源数据集。

3.1 网页
网页数据将构成预训练中的核心语料。
-
DataComp-LM: In search of the next generation of training sets for language models. 开源网页数据集,经过Fasttext等筛选后得到的3.8T数据集
-
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale FineWeb和教育质量打分FineWeb-Edu语料,对于知识密集型题目有一定效果
-
Nemotron-CC-HQ. 英伟达的高质量网页语料
-
Chinese-FineWeb-Edu. OpenCSG开源的中文教育质量打分语料,从Map-CC、SkyPile、WuDao、Wanjuan等筛选打分
-
FineWeb2: A sparkling update with 1000s of languages 多语言数据集
3.2 数学
数学预训练语料可以显著提升基模的数学能力以及后训练的上限。
-
MegaMath: Pushing the Limits of Open Math Corpora 开源最大的高质量数学CC语料
-
JiuZhang3.0: Efficiently Improving Mathematical Reasoning by Training Small Data Synthesis Models 合成数学指令数据
-
mlfoundations-dev/stackoverflow_math 数学相关提问
-
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning 高难度数学数据集
-
YuLan-Mini: An Open Data-efficient Language Model 收集开源Lean定理证明数据集
3.3 代码
代码数据不仅可以增强基模生成代码的能力,还可以增强数学、逻辑等方面
-
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models 从 The-Stack-V2 中清洗
-
SmolLM-corpus. Python教育质量打分
-
The-Stack-V2 最大规模未清洗的代码数据
-
YuLan-Mini: An Open Data-efficient Language Model 以教育质量清洗Jupyter-Notebook和Python数据
-
HuggingFaceTB/issues-kaggle-notebooks GitHub Issues和Kaggle Notebooks数据
-
mlfoundations-dev/stackoverflow 编程问答论坛
-
Magicoder: Empowering Code Generation with OSS-Instruct 利用开源代码生成合成指令数据训练
3.4 通用(书籍、百科、指令、长上下文等)
通用数据往往是较为稀缺的长尾数据,对于后训练模型的可用性起到至关重要的作用。
-
YuLan: An Open-source Large Language Model 长尾知识增强和多种通用数据源清洗
-
MinerU: An Open-Source Solution for Precise Document Content Extraction PDF转Markdown,兼容性较强
-
The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv、对话、DM Math等
-
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. 百科、书籍、论文、Reddit等
-
WanJuan: A Comprehensive Multimodal Dataset for Advancing English and Chinese Large Models 法律、考试、新闻、专利、百科等
-
MAmmoTH2: Scaling Instructions from the Web 针对网页的问答
-
togethercomputer/Long-Data-Collections 从RedPajama、Pile、P3等数据集过滤的书籍、论文、网页和指令
-
Longattn: Selecting long-context training data via token-level attention 长程依赖的问答
四、数据方法
数据集往往配合高质量的数据方法。我们从分词器、数据配比和课程、数据合成等方面详细阐述。
4.1 分词器
分词是模型重要又常被忽视的一块,会显著影响模型在数学、知识等方面能力。
-
SuperBPE: Space Travel for Language Models 多单词的分词器训练方式
-
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies 预测词表大小
-
Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs 数字的分词方式比较
4.2 数据配比和课程
多阶段预训练往往能使得模型充分学习高质量、少量的数据。在继续预训练(CPT)阶段引入更多的数学、代码、CoT甚至长思维链数据,将构成下一代预训练模型的核心能力。
-
Nemotron-4 15B Technical Report 分为 8T 预训练 + 更少数据规模的 CPT
-
YuLan-Mini: An Open Data-efficient Language Model 使用教育分数进行课程数据
-
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining 预训练数据混合比例优化
-
Efficient Online Data Mixing For Language Model Pre-Training 在线数据混合
-
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance 数据混合定律
-
Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data? 通过 BPE 分词器的合并规则,破解GPT等商业模型的数据比例
-
CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training 基于聚类的迭代数据混合自举框架
-
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens 为大规模预训练数据集构建索引,以检查数据质量
4.3 数据合成
除了前文提到的数学和代码的合成数据,我们总结了部分通用的合成数据方法和资源。除此之外,在预训练后期使用更多的长思维数据,也逐渐成为值得探索的方向。
-
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems 基于长思维链合成数据的模仿学习
-
Knowledge-Instruct: Effective Continual Pre-training from Limited Data using Instructions 生成信息密集型的合成指令数据,从有限的语料库中学习知识
-
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs 结构化合成长文本
-
Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use 多步骤推理数据合成,将复杂任务分解为子轨迹,结合强化学习优化数据生成
-
WildChat: 1M ChatGPT Interaction Logs in the Wild 用户真实对话的开源数据集
-
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing 对齐数据合成
如果您对于项目内容有建议,欢迎开源社区提交更新,以共同促进大模型的发展。
项目地址:https://github.com/RUCAIBox/awesome-llm-pretraining
(文:机器学习算法与自然语言处理)