MonkeyOCR:华科开源高效文档解析模型,精度超越闭源大模型、速度还更快!

华中科技大学开发的MonkeyOCR文档解析模型在OmniDocBench数据集上取得显著成果,相比MinerU、Qwen2.5-VL等开源和闭源大模型,在中文内容识别方面表现出色。该模型采用结构-识别-关系(SRR)三元组方法,并基于大规模标注数据集MonkeyDoc进行训练。
华中科技大学开发的MonkeyOCR文档解析模型在OmniDocBench数据集上取得显著成果,相比MinerU、Qwen2.5-VL等开源和闭源大模型,在中文内容识别方面表现出色。该模型采用结构-识别-关系(SRR)三元组方法,并基于大规模标注数据集MonkeyDoc进行训练。

术,通过巧妙地利用特征缓存机制,成功攻克了MAR模型在计算效率方面的瓶颈,不仅实现了高达 2.83
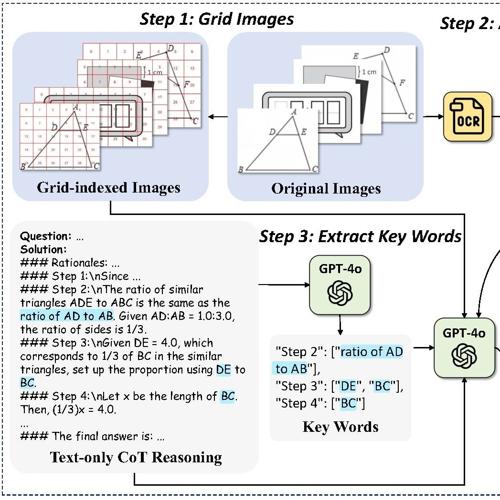
港中文 MMLab 提出的新方法 MINT-CoT,通过引入‘视觉交错思维链’实现细粒度视觉与文本推理融合,在多个基准数据集上刷新 SOTA,显著提升多模态大模型在数学视觉任务中的表现。

arvisIR 是首个将视觉语言模型(VLM)作为控制器的智能图像恢复系统,通过动态调度多个专家模型

型
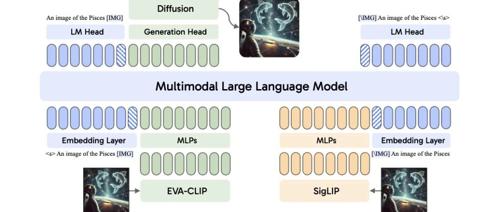
Orthus,可同时生成离散文本和连续图像特征。其通过特定的扩散头和语言模型头分别处理图像和文本
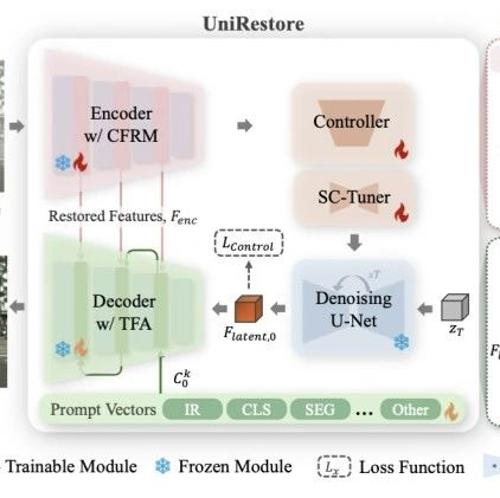
本文提出UniRestore框架,结合互补特征恢复模块和任务特征适配器,有效弥合感知式与任务导向图像恢复之间的差距,在多项任务中展现了领先性能和良好的可扩展性。

VGGT 是一种基于纯前馈 Transformer 架构的通用 3D 视觉模型,能够在单张或多张图像中直接预测相机参数、深度图和点云等几何信息。该模型在多个任务中的性能显著超越传统优化方法,并且推理速度达到秒级。