


极市导读
JarvisIR 是首个将视觉语言模型(VLM)作为控制器的智能图像恢复系统,通过动态调度多个专家模型,有效提升了自动驾驶在恶劣天气下的感知性能,平均指标提升达 50%。该研究还构建了大规模数据集 CleanBench 并提出 MRRHF 对齐算法,解决了真实场景下数据无标签的训练难题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2504.04158
项目主页:https://cvpr2025-jarvisir.github.io/
Github仓库:https://github.com/LYL1015/JarvisIR
Huggingface Online Demo: https://huggingface.co/spaces/LYL1015/JarvisIR
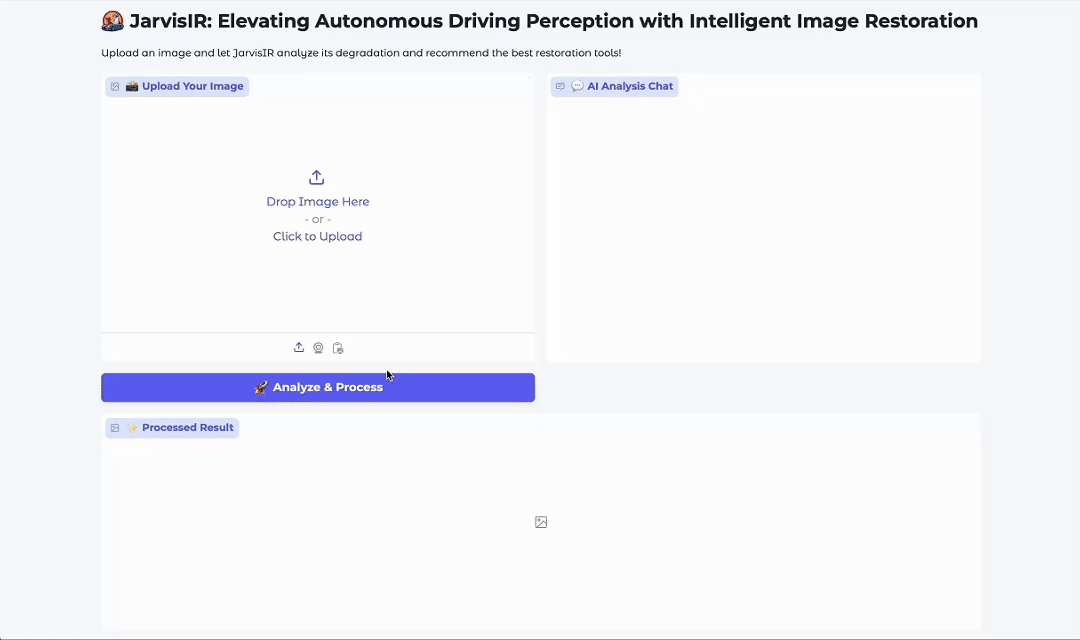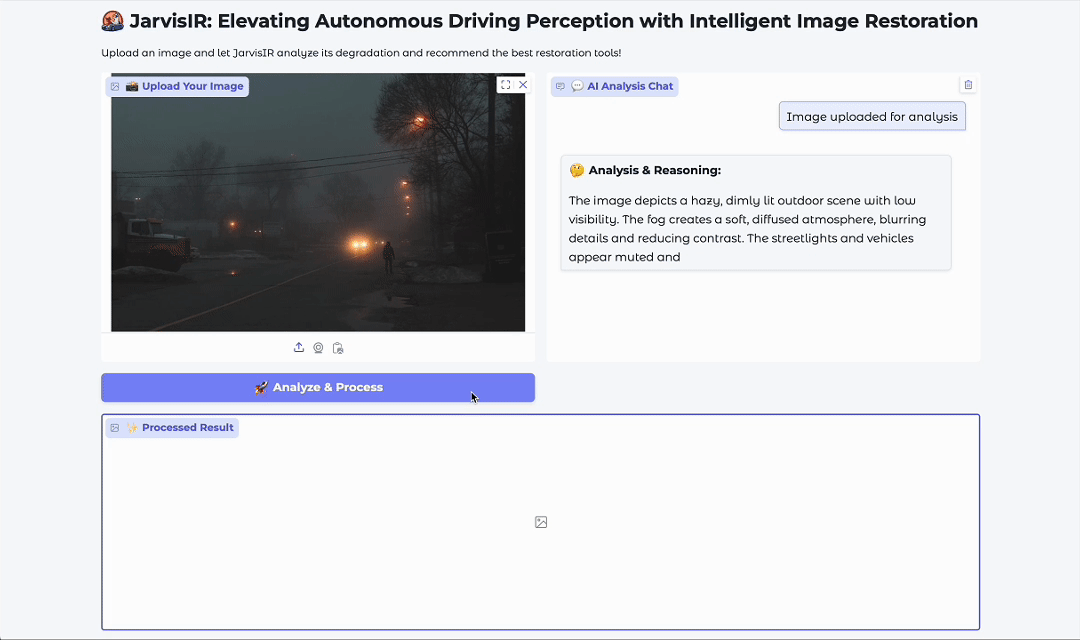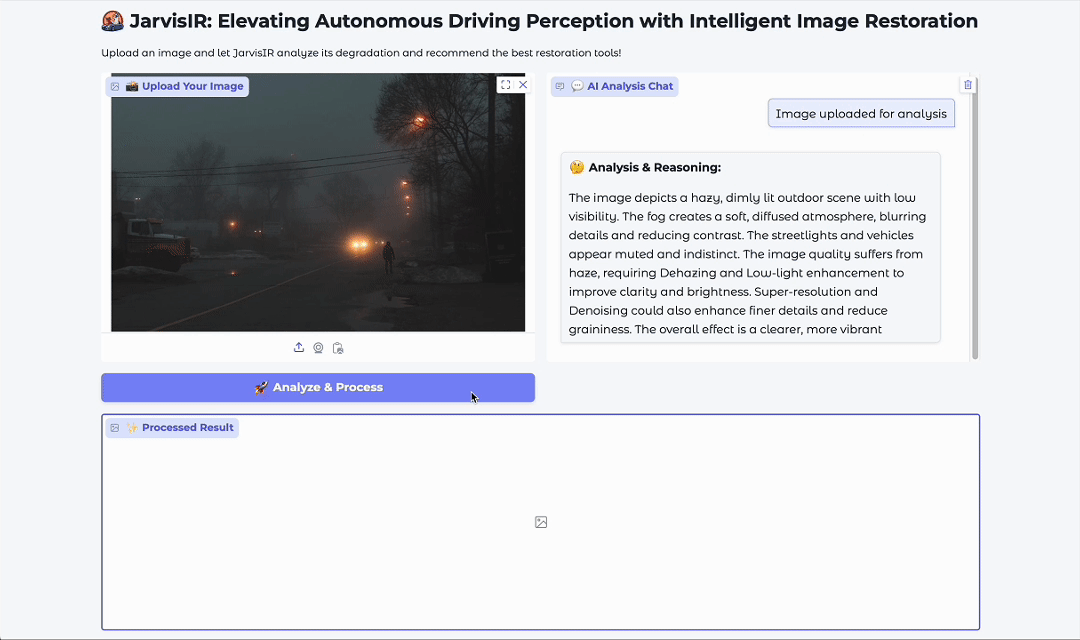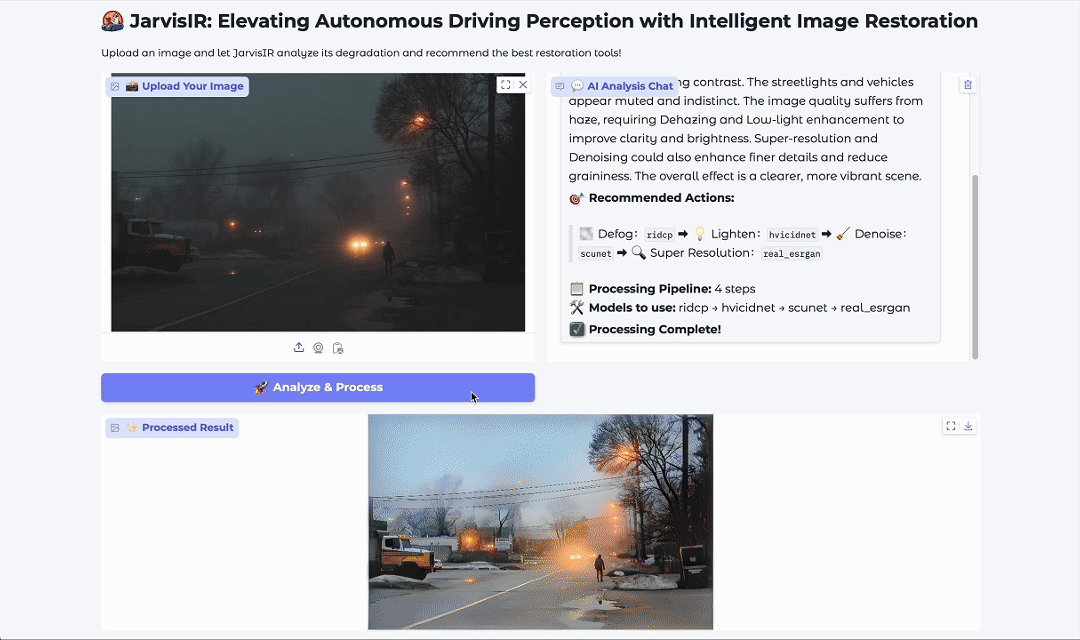
背景与动机
在自动驾驶等现实应用场景中,视觉感知系统常常受到多种天气退化(如雨、雾、夜间、雪)的影响。传统的单任务方法依赖特定先验知识,而 all-in-one 方法只能解决有限的退化组合同时又存在严重的领域差异,难以应对复杂的实际场景。
为了解决这一问题,研究团队提出了 JarvisIR —— 一个基于视觉语言模型(VLM)的智能图像恢复系统。该系统通过 VLM 作为控制器,动态调度多个专家模型来处理复杂天气下的图像退化问题,从而实现更鲁棒、更通用的图像恢复能力。

核心贡献
-
提出 JarvisIR 架构:首个将 VLM 作为控制器的图像恢复系统,能够根据输入图像内容和用户指令,自主规划任务顺序并选择合适的专家模型进行图像修复。 -
构建 CleanBench 数据集:包含 150K 合成数据 + 80K 真实世界数据,涵盖多种恶劣天气条件,支持训练与评估。 -
设计 MRRHF 对齐算法:结合监督微调(SFT)与基于人类反馈的人类对齐(MRRHF),提升模型在真实场景下的泛化能力和决策稳定性。 -
显著性能提升:在 CleanBench-Real 上平均感知指标提升 50%,优于现有所有方法。
🛠️ 方法详解
1. JarvisIR 架构设计
JarvisIR 的核心思想是将视觉语言模型(VLM)作为“大脑”,协调多个专家模型完成图像恢复任务。其工作流程如下:
-
任务解析:接收用户指令和输入图像,分析图像中的退化类型。 -
任务规划:根据图像内容和用户需求,生成最优的任务执行序列。 -
模型调度:依次调用对应的专家模型(如去噪、超分、去雨等)进行图像恢复。 -
结果整合:将各阶段的结果整合为最终输出图像,并附上解释性推理过程。
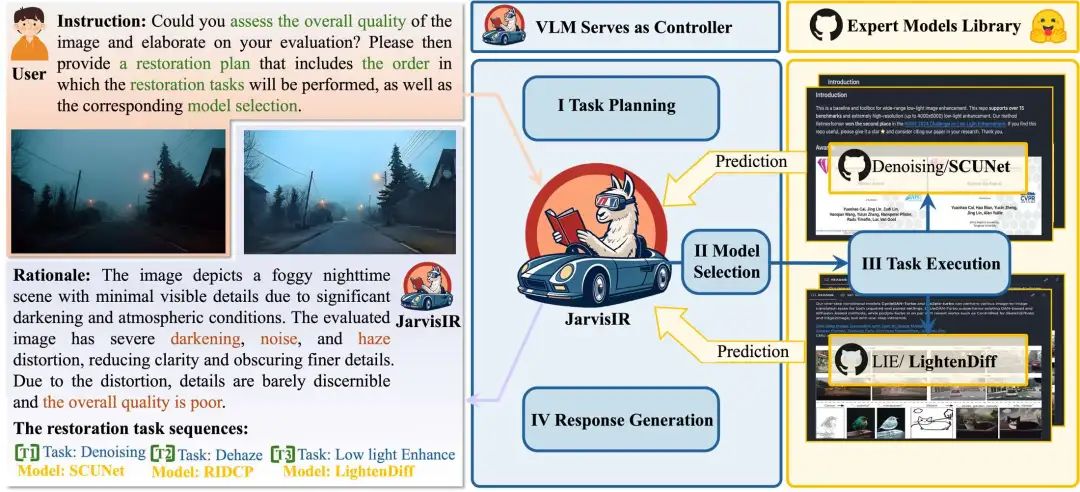
可参考论文图4理解整体流程。
2. CleanBench 数据集
CleanBench 是本文的核心训练与评估数据集,分为两个部分:
-
CleanBench-Synthetic:150K 合成数据,用于监督微调(SFT)阶段训练。 -
CleanBench-Real:80K 真实世界图像,用于 MRRHF 阶段的无监督对齐训练。
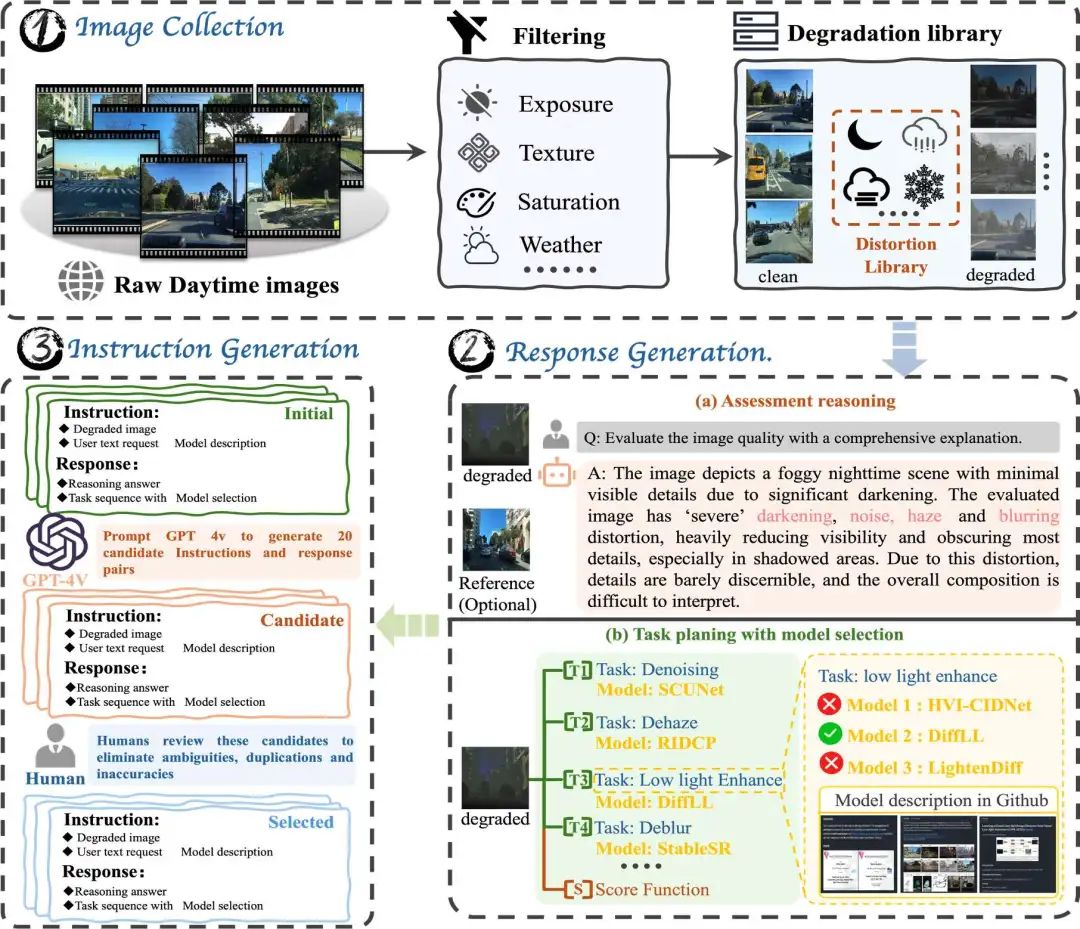
可参考论文图2理解CleanBench构建的过程。
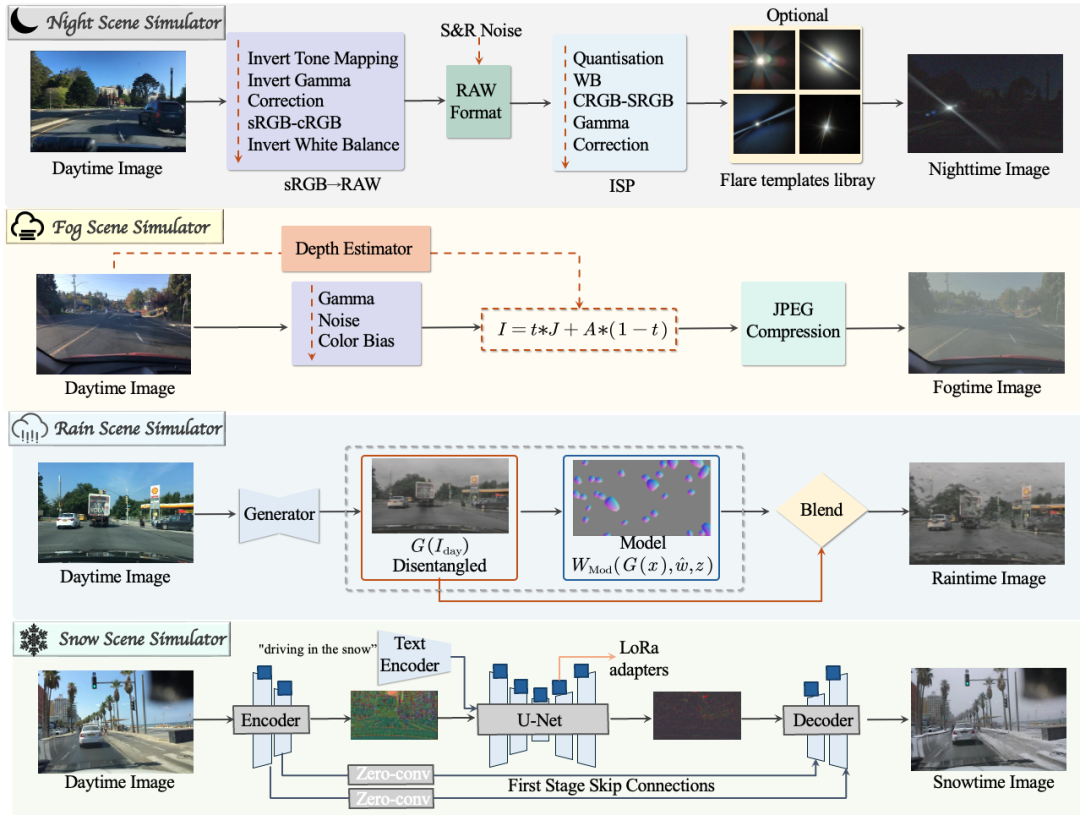
可参考论文附录图8了解构建数据所用到的合成退化库。
该数据集涵盖了四种主要天气退化场景类型:夜景、雨天、雾天、雪天。注意每个退化场景中可能包含多种退化(比如夜晚可能是暗光、噪声、雾、低分辨率)。
📚 数据构成
每条训练样本是一个包含三个元素的三元组:
其中:
-
:用户指令(instruction),描述希望执行的图像恢复任务; -
:退化图像(degraded image),即待处理的原始图像; -
:响应(response),包含了 Chain-of-Thought(COT)推理过程和最终选定的任务序列及模型选择。
例如:
-
指令:“请改善这张夜晚拍摄的照片质量。” -
退化图像:一张夜间低光模糊照片; -
响应:先进行低光增强,再进行去噪,使用的模型为 Img2img-turbo和SCUnet。

合成的退化样本。
3. 两阶段训练框架
第一阶段:监督微调(SFT)
在 JarvisIR 的整体训练流程中,监督微调(SFT)是第一阶段的核心任务。其目的是让视觉语言模型(VLM)初步掌握如何:
-
理解用户输入的图像恢复指令; -
分析图像中的退化类型(如雨、雾、夜景等); -
规划合理的恢复任务顺序; -
选择正确的专家模型组合进行图像修复。
这个阶段使用的是 CleanBench 数据集中的合成数据部分(CleanBench-Synthetic),这些数据具备完整的标注信息(即已知退化类型和最优恢复路径),因此适合用于有监督学习。SFT 的训练目标是最小化以下损失函数:
其中:
-
是第 条样本的真实响应; -
是对应的用户指令; -
是对应的退化图像; -
$R_{<i}$ 表示当前响应前面已经生成的部分;<=”” section=””> -
是模型参数; -
是响应 token 的总数量。
这是一个典型的自回归语言建模目标,鼓励模型根据给定的上下文(图像和指令)准确预测出期望的响应。
第二阶段: 人类反馈对齐(MRRHF)
在 JarvisIR 中,人类反馈对齐(Human Feedback Alignment) 是训练过程中的关键阶段。由于真实世界图像缺乏配对标注数据,传统的监督微调(SFT)无法直接应用于 CleanBench-Real 数据集。因此,研究者提出了一种基于奖励模型的无监督对齐方法:MRRHF(Mixed-Rank Reward-based Human Feedback)。
MRRHF 是 RRHF(Rank Responses to Align Human Feedback)的一种扩展,旨在通过结合离线采样与在线采样策略、引入熵正则化项,提升 VLM 在真实世界恶劣天气图像恢复任务中的稳定性、泛化能力和响应多样性。
MRRHF 的核心组成
1. 奖励建模(Reward Modeling)
MRRHF 使用多个基于 VLM 的 IQA(Image Quality Assessment)模型来构建一个统一的奖励函数:
其中:
-
:第 个 IQA 模型对图像质量的评分; -
:该模型评分的历史均值与标准差; -
:参与评估的 IQA 模型数量(如 Q-instruct、MUSIQ、MANIQA 等)。
这个奖励函数用于衡量系统输出的图像恢复结果的质量,并作为训练信号指导 VLM 的优化。
2. 混合采样策略(Hybrid Sampling Strategy)
为了在保持性能下限的同时扩展探索空间,MRRHF 结合了两种样本生成方式:
-
离线采样(Offline Sampling):使用 SFT 模型进行多样 beam search 生成多个候选响应。 -
在线采样(Online Sampling):使用当前训练中的 policy model 动态生成响应。
最终将两者合并为候选响应集合 ,从而在训练过程中提供更丰富的探索路径。
3. 多任务损失函数
MRRHF 的目标是通过以下三种 loss 共同优化模型:
(1) 排名损失(Ranking Loss, )
作用:
-
鼓励模型对高奖励响应赋予更高的概率 ,低奖励响应赋予更低的概率。 -
通过对比不同响应的得分和模型预测概率,引导模型学习排序能力。 -
保证模型在面对多个可能响应时,能够选出最优解。
✅ 目的:让模型学会“好响应”比“坏响应”更好。
(2) 微调损失(Fine-tuning Loss, )
作用:
-
对于奖励最高的响应 ,强制模型学习其完整生成过程。 -
相当于一种强化学习中的“模仿学习”,确保模型掌握最优响应的生成逻辑。
✅ 目的:让模型准确复现最高奖励的响应内容。
(3) 熵正则化损失(Entropy Regularization Loss, )
作用:
-
增加响应的多样性,防止模型陷入局部最优,只生成重复或保守的回答。 -
通过最大化输出分布的熵,鼓励模型探索更多合理的响应路径。
✅ 目的:增强模型的探索能力,避免过拟合单一响应模式。
总体损失函数
最终,MRRHF 的总体损失函数由三部分组成:
其中:
-
:控制各 loss 权重的超参数(论文中设为 )。
这三部分 loss 协同工作,使得 JarvisIR 能够在没有人工标注的情况下,利用大量真实世界数据完成有效的对齐训练。
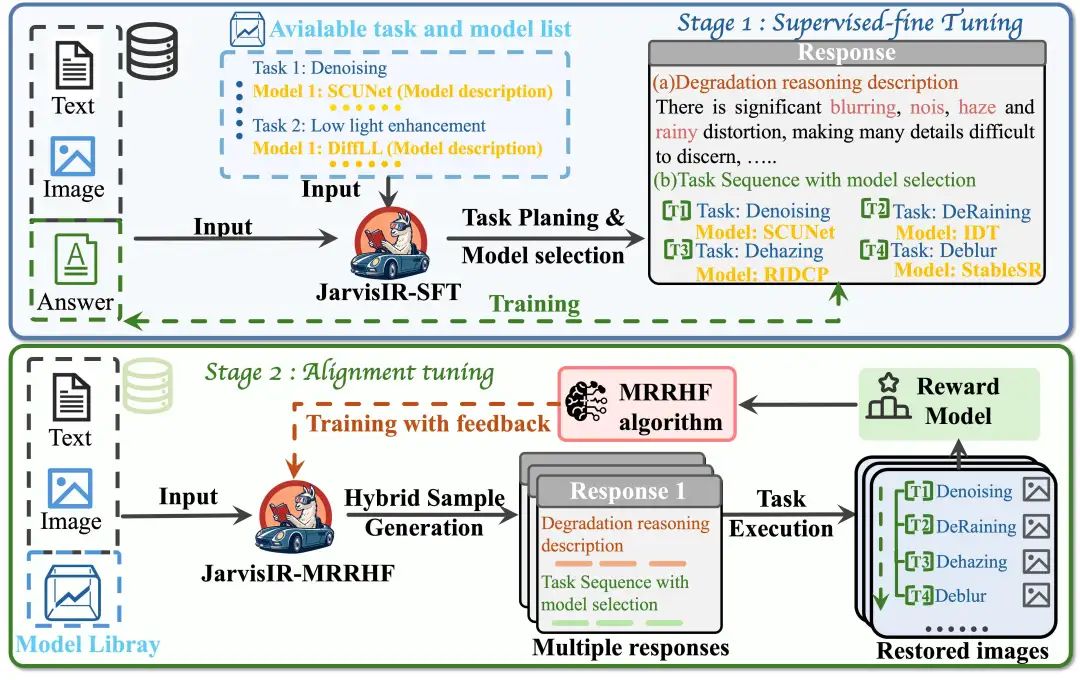
可参考论文图5理解两阶段的训练框架。
实验与结果分析
1. 决策能力对比(CleanBench-Real 验证集)

✅ 结论:JarvisIR-MRRHF 在工具决策能力上显著优于其他策略。
2. 图像恢复性能对比
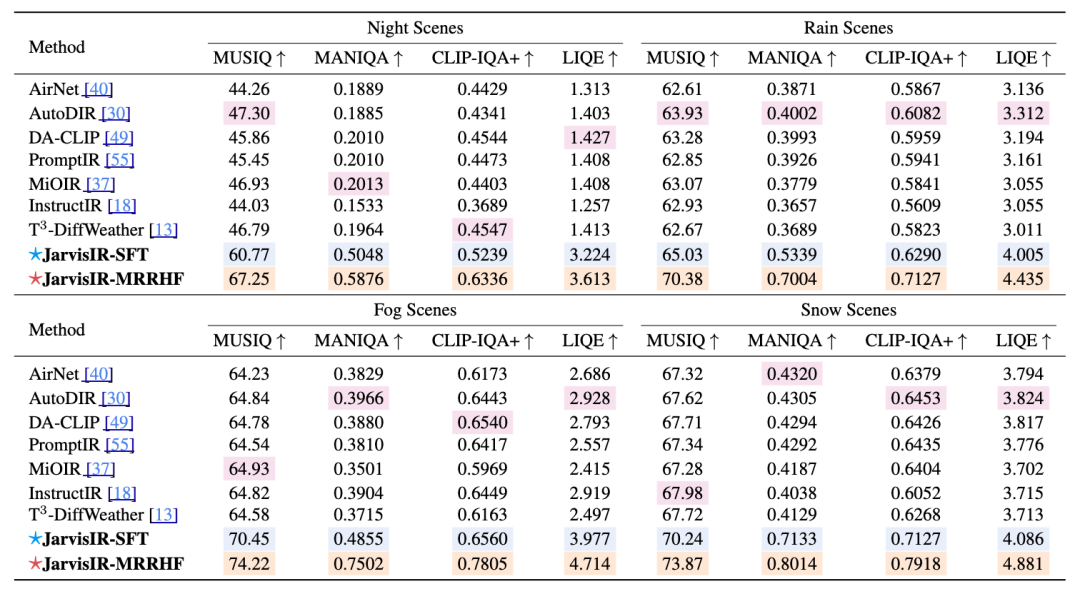


✅ 结论:在所有天气场景下均优于现有 all-in-one 方法,提升显著(平均改善指标50%)。
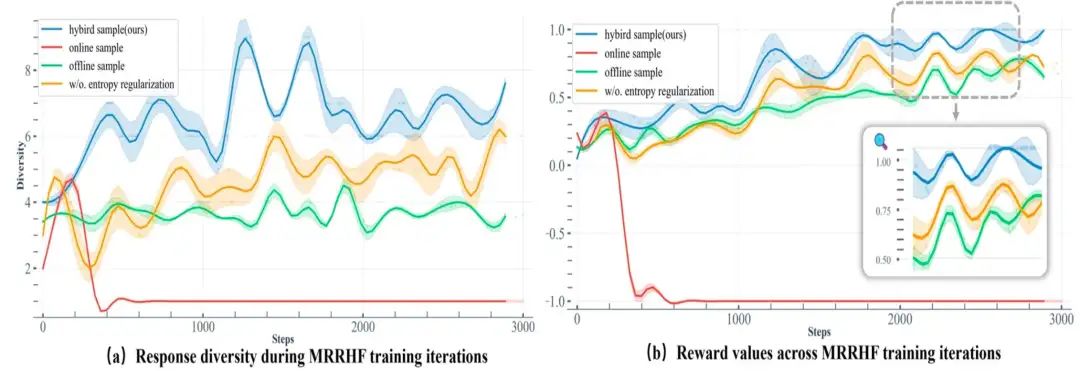
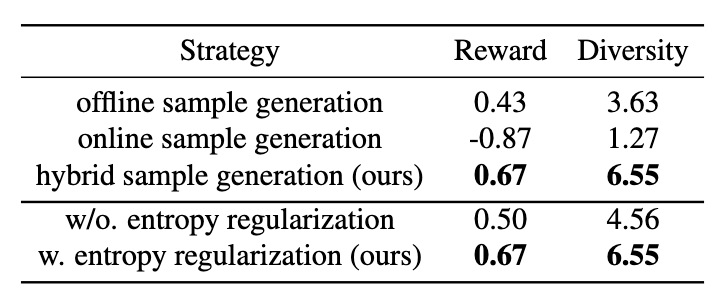
3. Ablation Study
-
样本生成策略对比:混合采样策略(结合离线和在线的优势)在奖励分数和响应多样性方面均表现最佳。它既能保证训练的稳定性,又能提供足够的探索空间,优于单纯的离线或在线采样。 -
熵正则化影响:加入熵正则化能显著提升系统响应的多样性,并有助于提高奖励分数。这是因为它鼓励模型进行更广泛的探索,产生更多样化的高质量响应。 -
MRRHF 与 Vanilla RRHF 的对比: MRRHF 通过其混合样本生成和熵正则化策略,在奖励和多样性方面均显著优于 Vanilla RRHF。这表明 MRRHF 能更有效地利用人类反馈进行对齐。
技术亮点总结
-
VLM 作为控制器:首次将视觉语言模型应用于图像恢复系统的控制中枢,具备强大的上下文理解和任务规划能力。 -
专家模型协同机制:多个专业模型按需调用,适应不同天气条件下的图像退化问题。 -
大规模真实数据集 CleanBench:填补了真实世界图像恢复数据的空白。 -
MRRHF 对齐算法:无需人工标注,即可利用大量真实数据进行模型优化,提升泛化能力。
总结
JarvisIR 是一项具有开创性的研究成果,标志着图像恢复从单一任务向智能化、多模型协同方向迈进的重要一步。其核心价值在于:
-
将 VLM 用于图像恢复系统的控制 -
提出 MRRHF 对齐算法,解决真实数据无标签问题 -
发布高质量数据集 CleanBench,推动社区发展
如果你正在研究图像恢复、视觉语言模型或多模态系统,JarvisIR 提供了一个全新的视角和实践路径,值得深入学习与应用。
参考文献
[1] JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
(文:极市干货)