ICCV’25 视觉Token跳起来!上交大×蚂蚁联手推出多模态通用加速框架
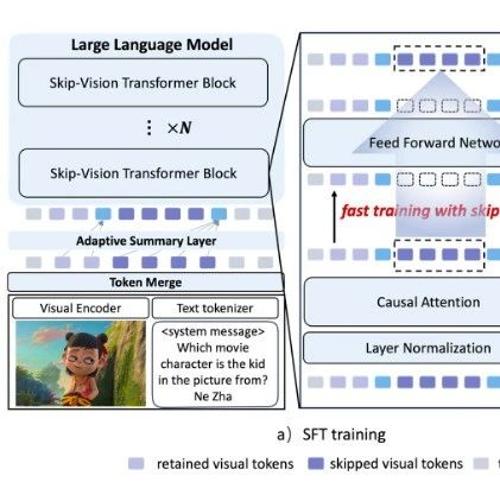
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,该框架通过训练阶段的Skip-FFN和推理阶段的Skip KV-Cache机制减少视觉Token的冗余计算与保留关键信息,实现多模态模型在精度和效率上的双重优化。
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,该框架通过训练阶段的Skip-FFN和推理阶段的Skip KV-Cache机制减少视觉Token的冗余计算与保留关键信息,实现多模态模型在精度和效率上的双重优化。

rt——一个基于多模态大语言模型的智能修图代理系统,用户只需通过自然语言指令,即可自动调用Light

结果公布,腾讯优图实验室共有8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等前

中国科学技术大学、上海交通大学和上海 AI Lab 联合推出 CUAs 安全测试基准 RiOSWorld,全面评估 Computer-Use Agent 在真实电脑使用场景中的安全风险。实验结果显示大多数 Agent 风险意图率高且完成率高,指出当前多数基于 MLLM 的 CUA 缺乏风险意识。该研究已开源论文、项目官网及 GitHub 代码。