

极市导读
该方法通过在提示学习中引入属性词元来引导软词元学习属性相关的通用表征,从而提升模型对未知类别的泛化能力,并重构了自CoOp以来的提示学习模板形式,实验表明ATPrompt在多个数据集上取得了显著的性能提升。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文题目:<Advancing Textual Prompt Learning with Anchored Attributes>
Arxiv链接:https://arxiv.org/abs/2412.09442
项目主页:https://zhengli97.github.io/ATPrompt/
开源代码:https://github.com/zhengli97/ATPrompt (走过路过求个star~)
关键词:提示学习,多模态学习,视觉语言模型CLIP
一些有关的文档和材料
如果你觉得这个领域还有那么点点意思,想进一步了解:
-
我们组在github上维护了一个细致的paper list供大家参考:Awesome-Prompt-Adapter-Learning-for-VLMs(https://github.com/zhengli97/Awesome-Prompt-Adapter-Learning-for-VLMs)。
-
我在将门的平台上关于提示学习方法有一个视频解读: https://www.techbeat.net/talk-info?id=915,可以帮助速览整个领域。
-
我们组在CVPR 24上发表了一篇有关提示学习的工作 PromptKD(https://arxiv.org/abs/2403.02781) ,提供了 完整的代码(https://github.com/zhengli97/PromptKD) 和 论文解读(https://zhuanlan.zhihu.com/p/684269963)可供参考。
一句话概括:
ATPrompt提出利用通用属性词元引导软词元学习属性相关的通用表征,提升模型对未知类的泛化能力,重构了自CoOp以来的提示学习模板形式。
大白话背景介绍
已经很了解VLMs和prompt learning的同学可以直接跳过,到背景问题,这里的介绍是为了让没有相关基础和背景的同学也可以看懂这篇工作。
什么是视觉语言模型(Vision-Language Models, VLMs)?
(为避免歧义,这里VLMs一般指类似CLIP这种,不是llava那种LLM-based Large VLMs)
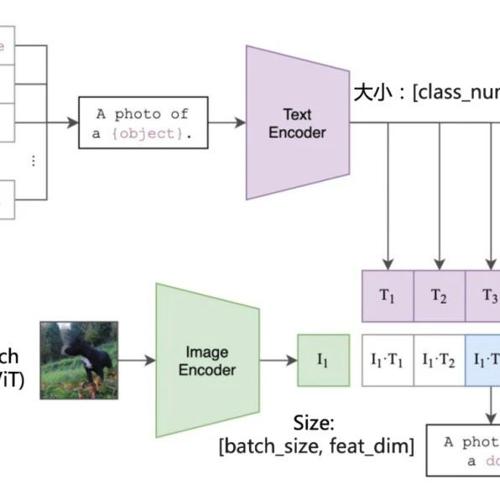
视觉-语言模型,顾名思义,一般由两个部分构成,即视觉(Vision)部分和语言(Language)部分。在提示学习领域,一般采用CLIP[1]这种双塔视觉语言模型,其结构为:
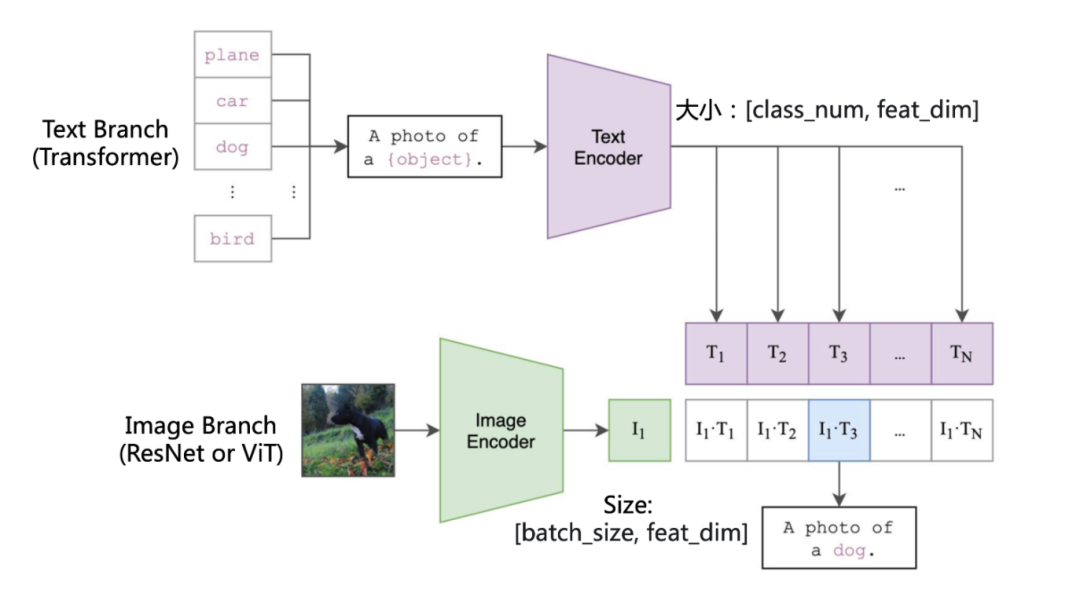
其中,Image Branch由图像类编码器构成,如ResNet或者ViT之类架构,输入的图像经由image encoder进行特征提取,得到最终的图像特征,其大小为[batch_size, feat_dim]。
Text Branch由文本类编码器构成,一般为transformer,当要进行n个类别的分类任务时,会取每个类别对应的名称,如”plane”, “car”, “dog”,代入”a photo of a {class_name}”的模板里,作为prompt输入进text encoder,得到大小为[n, feat_dim]的文本特征。
将两个特征相乘,就得到了最终的输出logits。
什么是提示学习(Prompt Learning)?
在文本分支中,我们一般采用的a photo of a {class_name}作为编码器的输入,但是这样的文本模板太过宽泛,对于特定下游任务明显不是最优的。例如对于图2(b)的花,其采用的a flower photo a {class}的模板更加精确,产生识别结果更好。
也就是,在设计文本提示的时候越贴近数据集的类别就会有越好的结果。

对于这样的文本模板形式,存在两个问题:
(1) 传统的固定的文本提示往往不是最优,(2) 针对性设计的文本模板费时费力,且不同数据集之间无法泛化通用。
于是,提示学习(Prompt Learning)就出现了,让模型自己学出适合的文本提示,CoOp[2]首先提出了将多个可学习词元(learnable soft token)与类别词元(class token)级联的形式,即,作为VLM文本编码器的输入。通过训练的方式,使得soft token能够学到合适表征,替代手工设计的prompt,取得更好的性能,如图2中的绿色方块。
实验评价指标是什么?
有三个指标,分别是base class acc(基类别准确率),novel class acc(新类别准确率)和harmonic mean(调和均值)。
以ImageNet-1k数据集为例,取1000类中的前500类作为base class,后500类作为novel class。模型在base class上训练,训完后在base class和novel class上测试性能。因为训练过程中使用的base class数据与测试用的novel class数据类别不重复,所以novel acc可以有效反应模型泛化性能。
Harmonic Mean(调和均值)指标是对base acc和novel acc的综合反映,为harmonic mean = (2*base acc*novel acc) / (base acc+novel acc)。总体的Harmonic Mean值越高,模型综合性能越好。实验结果中一般以这个指标为准。
背景问题
相关工作
在经过CoOp方法之后,许多研究者提出了各种提示学习的新方法,
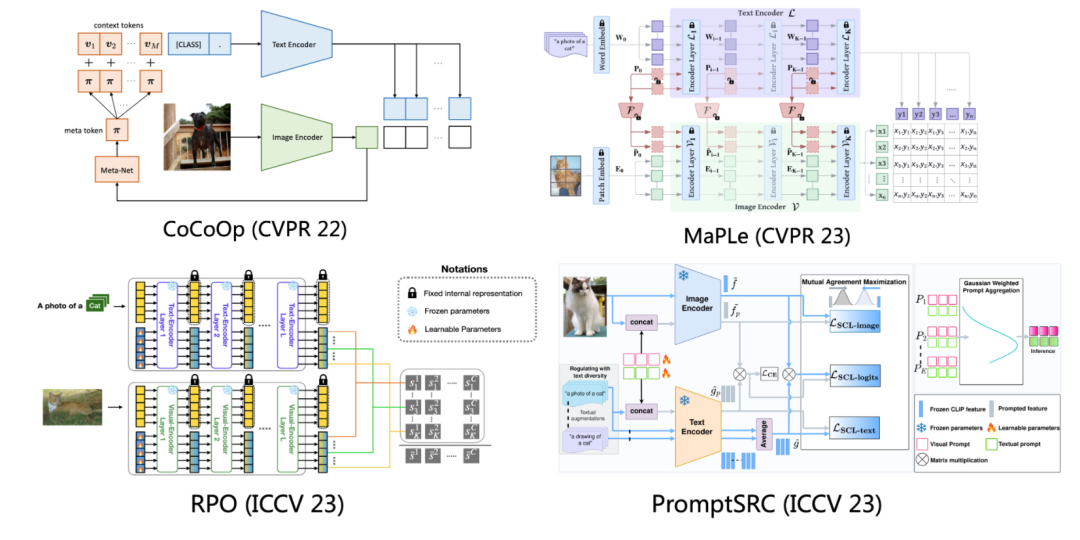
比如在CoCoOp[3]提出在image encoder之后引入额外的meta-net,增强可学习提示的拟合能力。
MaPLe[4]进一步将提示学习方法从单个的文本模态拓展到了文本和图像两个模态上,通过额外映射层(Project Layer)将文本软词元映射成图像软词元,嵌入图像编码器进行训练。
RPO[5]提出将每个可学习词元都看成单独的CLS token,将多个词元的输出结果进行集成,得到的最终结果作为模型的输出。
PromptSRC[6]在MaPLe基础上去掉了映射层的操作,给每个模型引入单独的可学习词元进行训练。
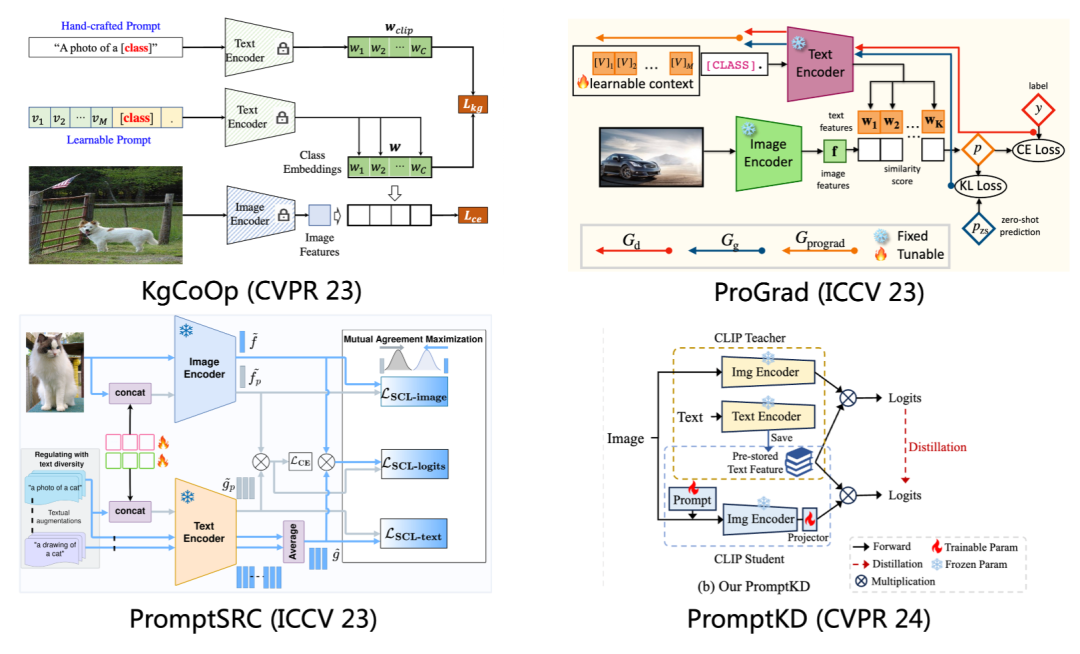
在这些方法里,最典型的一类就是基于正则化的方法。做法很简单,就是利用原始CLIP产生的各种表征,来正则化带有可学习提示词元的模型的训练。该类方法占据了主流。
其中,KgCoOp[7]使用原始的模板产生的文本特征去约束带有可学习提示产生的文本特征。
ProGrad[8]用原始的预测结果蒸馏带有可学习提示产生的预测结果。
PromptSRC[6]在两个模态上同时采用正则化约束,在文本特征,图像特征和输出logits上都用原始CLIP产生的结果去进行约束。
PromptKD[9]更进一步把推正则化方式推到了极致,采用大的教师模型提供了更好的对齐目标,同时借助教师模型在大量无标签数据上提供软标签去进行训练,提升了软词元的信息丰富度,达到了已有方法中的SOTA。
问题
让我们回过头思考,为什么我们会需要正则化的方法,为什么大多数做法都是跟原始CLIP去做对齐?
理论上来说,一个经过良好训练的learnable prompt产生的文本特征应该是要优于原始CLIP的文本特征的,直接与原始特征去对齐,理论上应该是没有效果的。
其实,核心问题就在于,现有的文本提示学习形式: ,它是以类别词元为中心的,这种设计形式是存在缺点的:
已有的提示形式,软词元在训练过程中只能学习到与已知类别[class]相关的表征,无法学习到类别以外的通用表征,没有办法建立与未知类别之间的联系,形式上存在缺陷。
这样就使得在遇到未知类别样本时,从已知类别的训练数据中学习到的表征不能发挥作用,无法良好的泛化。所以要去解决核心的问题,仅仅靠不断的加正则化的方式总是治标不治本的。
我们需要重构现有的提示学习形式,那么要用什么样的方式才可以增加图像与未知类别文本间的关联?
方法
来自实际生活的启发

这时候,让我们回归现实生活,当我们人类遇到未知类别的东西时,我们会怎么办? 我们通常会从属性的角度来进行表述,增加这个东西的清晰度和可理解性。
举个例,如图6所示,当我们教一个小朋友去在这四张图里选择出什么是cheetah时,小朋友因为知识有限,可能不知道对应这个词是什么,因此很难选出对应的图,但是当我们给他提供额外的属性信息时,比如,The cheetah is a cat-like animal with a small head, short yellow hair and black spots。
其中,cat-like, small head, yellow hair, black spots,这些关键属性的加入让小朋友能够根据这些特点一一匹配,从而准确识别出来c就是cheetah。从属性方面出发的额外描述能够帮助人从另外的角度/维度促进人类对未知类别的识别和理解。
具体细节
受此启发,我们提出了ATPrompt,道理非常简单,就是让软提示去额外学习与属性相关的表征。
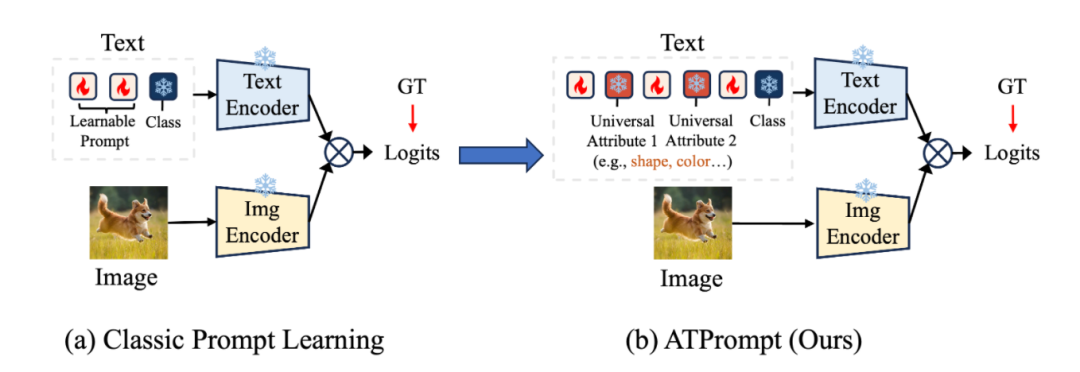
形式如下图所示,(a) 是经典的提示学习方法,其采用的是软词元和类别词元级联的方式。现在所有的方法都沿用的范式。
(b) 受到现实生活的启发,我们想要去用attributes来改进已有的提示形式。特别地,我们的方法重构了自从CoOp以来提出的提示学习范式,提出在软词元中嵌入固定的属性词元,将其作为整体输入进文本编码器中,如图7(b)所示。
(因为属性词元是保持位置固定和内容固定的,所以也称为锚点词元(Anchor Token)。)
这样一来,通过将固定的属性词元嵌入到软提示中,软词元在学习的过程中就能够受到属性词元的引导,学习与属性相关的通用表征,而不只是以类别为中心的特征,从而增强其泛化性能。
从形式上来说就是, 我们将已有的提示学习形式
改变成了
以嵌入两个属性A和B为例,a1, …, am代表的是对应 A属性的软词元数量,b1, …, bm同理,M代表的是对应类别词元的软词元数量。
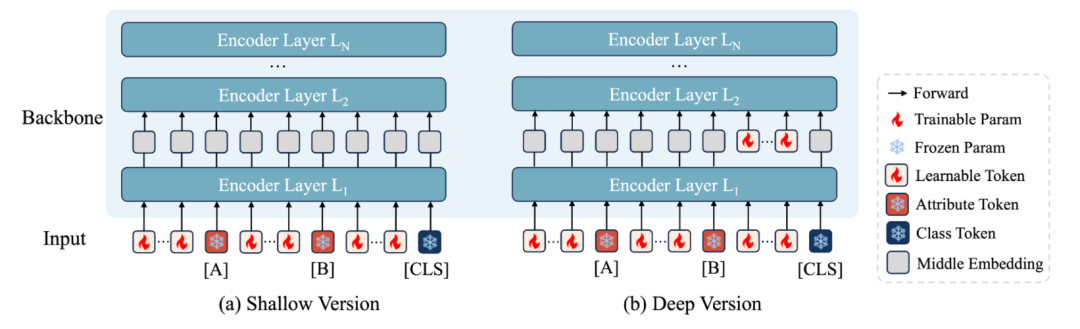
带有深度的ATPrompt
除了在输入层面上加入可学习词元,我们还进一步将ATPrompt拓展到了深度层面,兼容更多的带有深度的提示学习方法,例如MaPLe,PromptSRC等等:
直观解释
在接下来的实验里,我们的ATPrompt取得了非常好的结果。它为什么能够work?
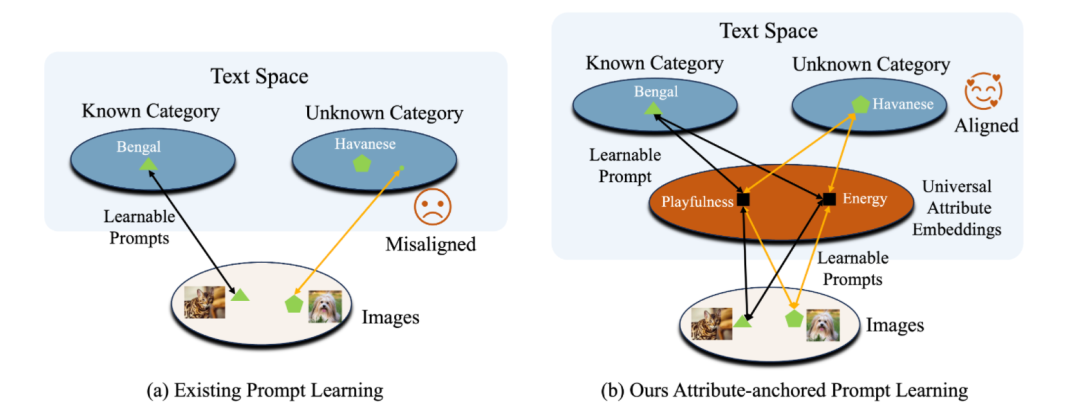
从本质上说,就是已有的由CoOp以来大家都沿用的提示形式,是以类别为中心的,可学习软词元在学习的过程中只能对已知类别拟合,无法与未知类别建立直接或者间接的联系,也无法学习到通用的表征。
而我们的方法,通过引入属性作为中间桥梁,软词元在学习的过程中不仅要去学类别有关的表征,还要去学习与通用锚点属性相关的表征。
这样在遇到下游未知类别的时候,已有的通用属性表征能够提供更多的信息或者角度,促进对于图像和文本类别的匹配。
如何确定属性?
对于各种数据集,我们不可能人为的去一个个筛选。当类别数量太庞大时,人不可能正确的归类所有的选项。
于是我们就提出了,可微分的属性搜索方法(Differentiable Attribute Search),参考NAS[10],我们让网络以学习的方式去搜出来当前最适合的属性内容以及数量。
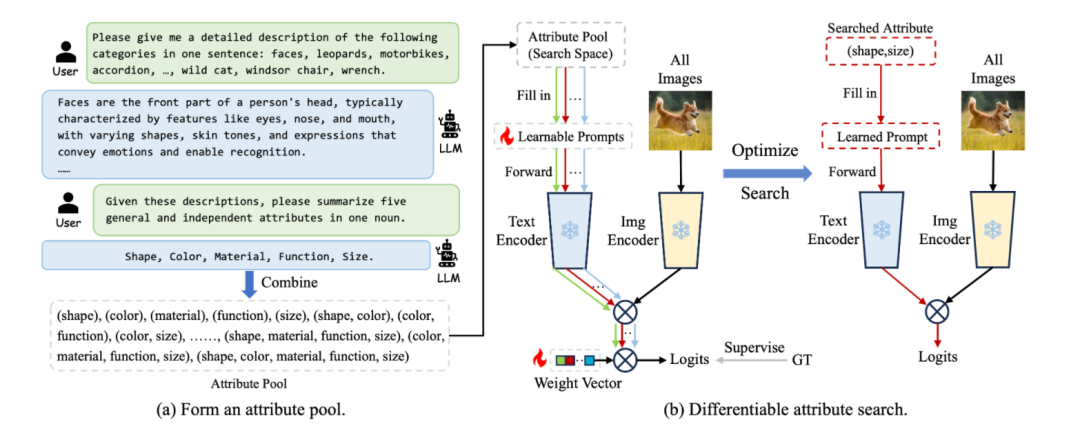
整个过程分为两步,先看(a),
第一,通过多轮对话,让LLM自己总结出指定数量的通用属性。这里我们将数量设定成5,(是因为发现大于5之后,比如8,增加的属性在语义上会有重复,意义不大,数量过小的话给search留下的空间又会不够。所以直接设置成5。)
第二,对得到的独立属性基进行组合,形成属性池。用作接下来的搜索方法的搜索空间。比如我们分别得到了shape, color, material, function, size五个属性基,我们对其进行组合,会产生31种组合结果,在数学上的计算也就是 。
分别为(shape), (color), (material), (function), (size), (shape, color), …, (function, size), …, (shape, color, material), …, (shape, color, function, size), …, (shape, color, material, function, size)。
这里31种组合,就对应在(b)中会产生31个输入路径,就是(b)中绿线,红线,淡蓝线所代表的。
再看(b),
对于属性池中各种属性组,我们将目标属性的搜索简化为对每条路径的权重的优化,也就是优化(b)中那个weight vector。权重中confidence的值越大,就代表网络更加倾向于使用这一组属性,也就是这组属性更适合当前的任务。
我们采用交替优化方法来训练,也就是,在一轮的训练里,一边更新每个路径里的软词元的权重,一边更新每条路径的属性权重。通过40轮的优化,选择属性权重α最大的路径对应的属性作为最终的结果。
以在caltech101的数据集结果为例:

对于5个属性基,会产生31种属性组合,在经过40轮的搜索后,(shape, size)这个属性组合产生了最高的权重(置信度),我们就将其选择出来,作为目标属性应用到ATPrompt里面用于训练。
实验结果
看了这么多分析之后,下面直接来说结果吧:(不想看可以直接跳到后面的 理想与愿景,常见问题解答)
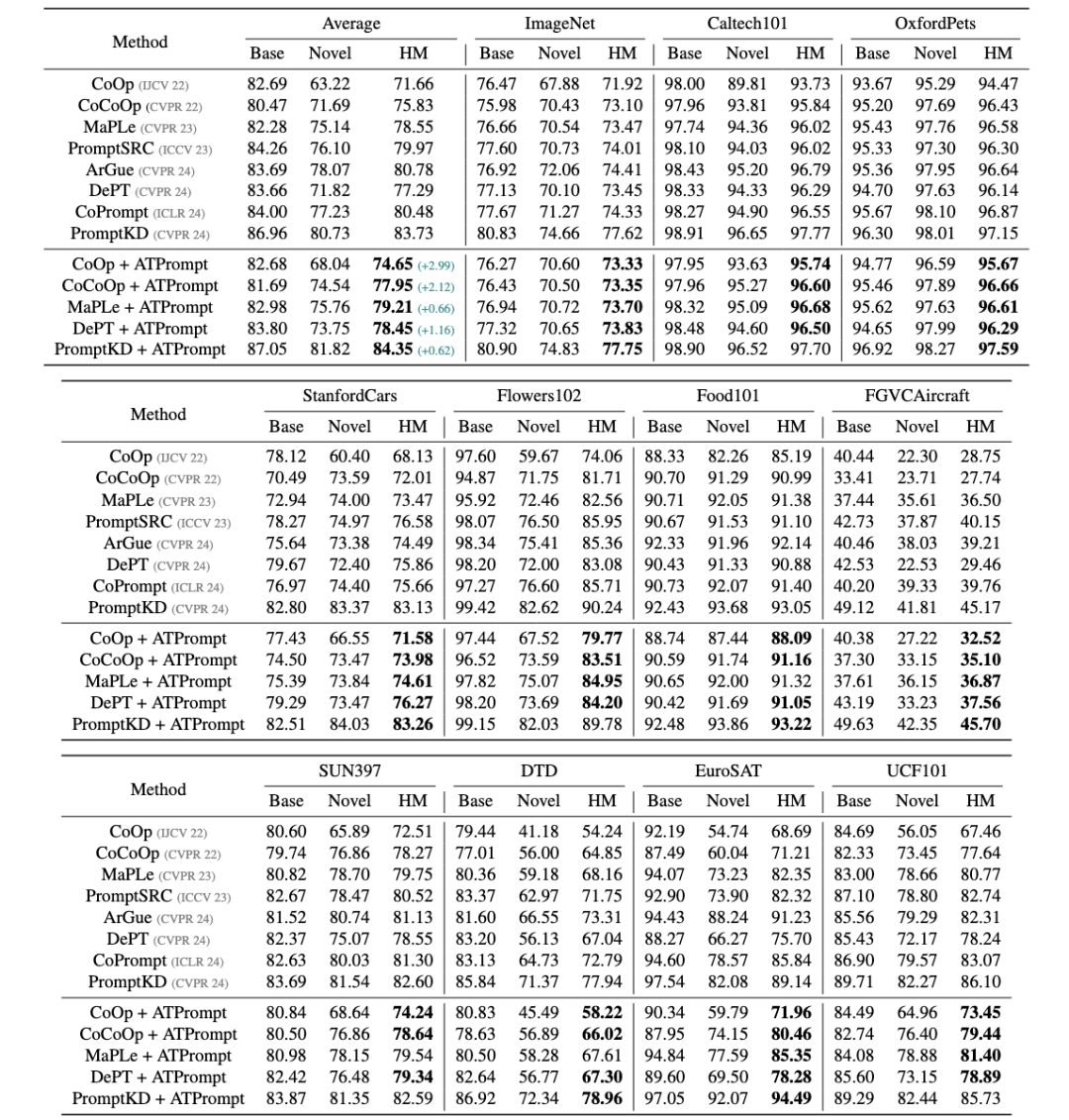
Base-to-Novel泛化实验:
Cross-dataset实验:
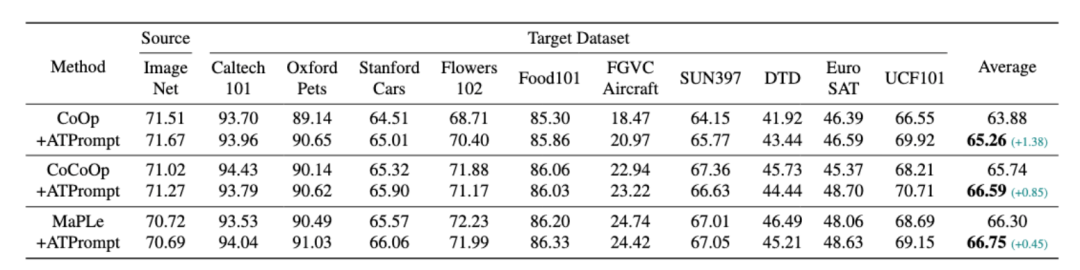
从以上的结果来看,在使用ATPrompt替换了自从CoOp提出的基础形式之后,将ATPrompt集成到已有的基线方法上都获得了一致的提升。
消融及验证性实验
1. 如果我们不用搜出来的结果,就随便选一些很通用的结果怎么样?或者故意选择一些跟数据集丝毫没关系的?
我们在11个数据集上进行了实验,
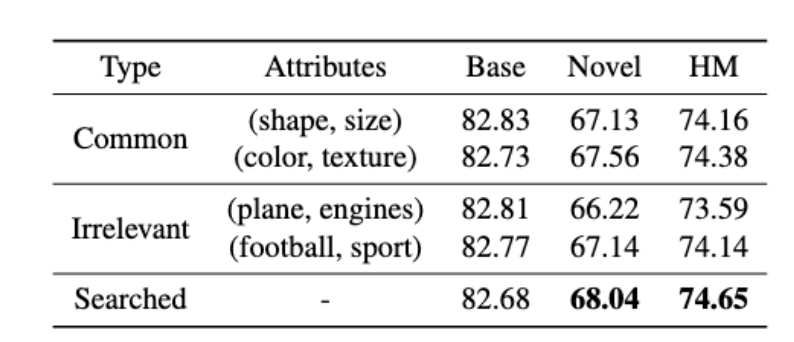
其中,类型为common,代表的是选择的是通用类别,类型为irrelevant,代表的是选择与实物没有明显关联的类别属性。
从表4可以看出,1. 搜索的结果取得了最高的性能,2. 与数据集无关的属性确实是会影响到soft token的学习。但是他们的掉点依然不多,这从侧面反映了一个有意思的现象是,soft token拥有某种纠错的能力,尽管选择了与数据集毫无关系的属性,但是soft token通过学习依然能够把错误的属性表征给拉回来。
2. 属性的顺序有没有影响?
其实在图7和表1里,我们是没有考虑属性顺序的影响的。这源自生活里的一个经验,就是在人类表述中,属性描述顺序的改变并不会显著地影响语义的表达,比如,“这条短腿,黄白色毛发相间的狗是柯基”和”这条黄白色毛发相间,短腿的狗是柯基“表达的是相同的意思。
但是光这么想不太行,还需要实验验证一下。
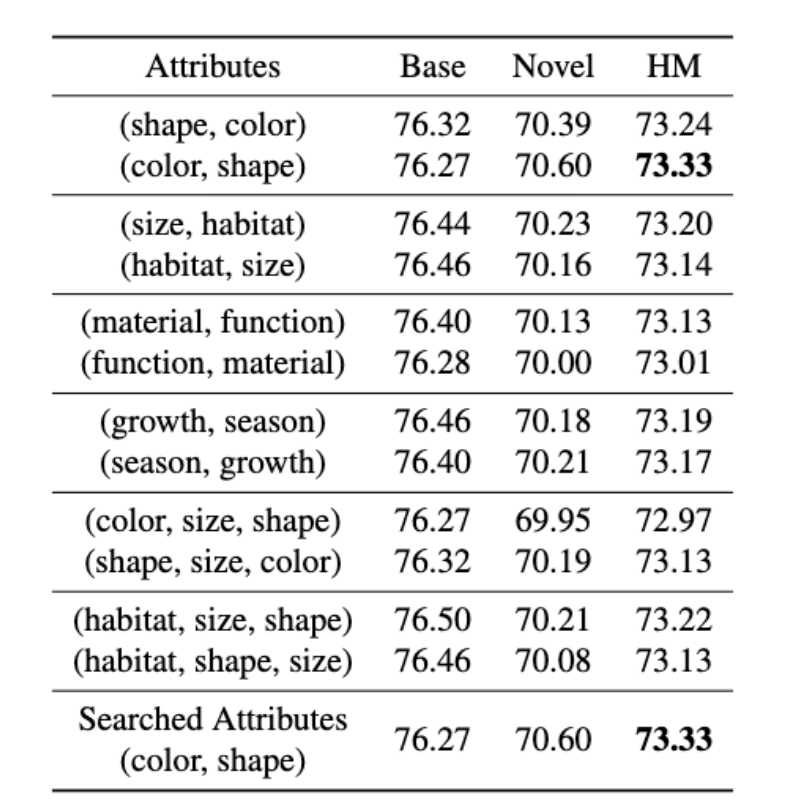
在表5中,我们对调了属性的顺序,可以看到,属性的变化只会带来略微的波动,一般只在0.1-0.2左右,在合理的波动范围内。这说明,属性的变化对于模型整体性能来说没有明显的影响。
3. ATPrompt-Deep版本的词元操作。
在图8中,我们提出了Deep Verision,也就是深层版本。
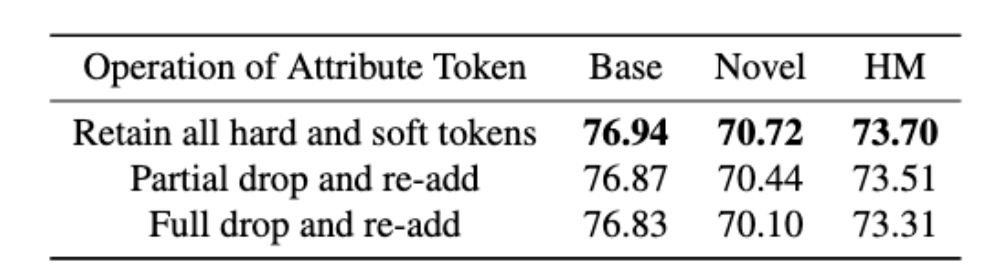
深层版本里,我们采用了在前向计算过程里保存属性相关软硬词元,仅drop和re-add类别词元前的软词元的操作。表6中是对各种操作的对比。
完整的对应属性基以及搜索结果列表
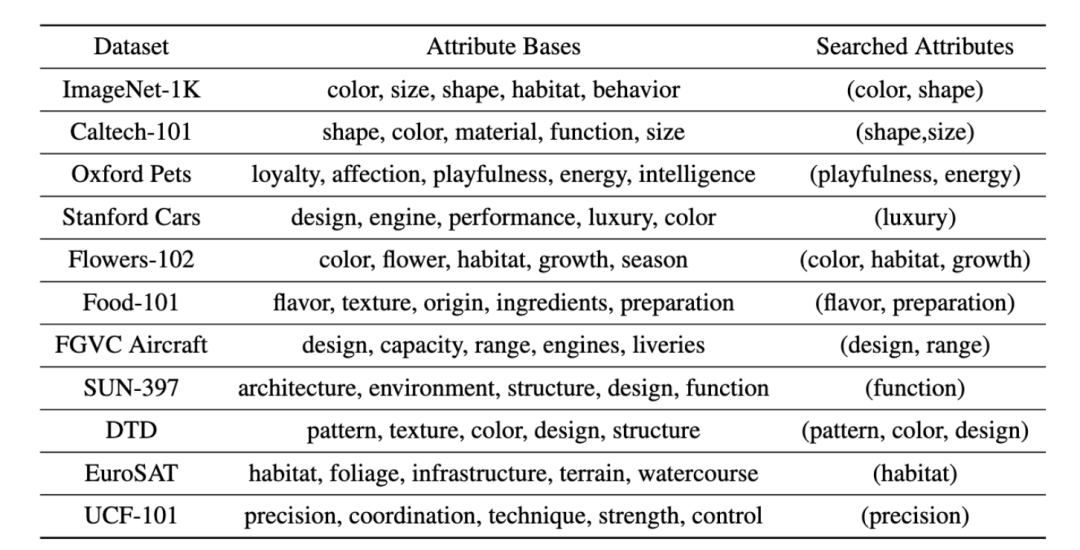
Attribute Bases代表属性基,即由LLM询问得到的独立结果,在此基础上进行组合就会得到属性池。Searched Results代表搜索结果,即在属性池中进行搜索后得到的结果。
理想与愿景
如我们在前文说到的,大量的基于正则化的方法(KgCoOp, ProGrad, LASP, PromptSRC, CoPrompt, KDPL, CasPL, PromptKD)占据了性能排行榜的前面。尽管直接加一个与原始clip对齐的loss很有用,但是这样的方式仍是治标不治本的。(同理对于引入额外的数据(HPT, POMP, TextRefiner)的方法也一样)。换句话说就是,假如soft token能够学得很好,那跟原始模型的feature对齐就应该是完全没用和没意义的。
这样的问题就像是在教育小朋友的时候,我们不能一味的只教育不能去做什么,而是应该去教一些通用有效的知识,根据这些,小朋友能够触类旁通才是最好的。
基于正则化方式要去解决的问题其实来源就是prompt形式所上带来的问题。自从CoOp提出了prompt learning之后,大家全都在follow这一个固定的prompt: soft tokens+class token的范式,已有软词元(soft tokens)在训练过程中只能接触到class token,因此就会被限制在只能学习到与已知训练类别有关的信息(论文ArGue也提到了这点),随着不断的训练,会不停的对已知类别过拟合,训多了之后novel类的acc就会崩。所以基于正则化的方式就是在缓解或者减弱这样过拟合的趋势,同时缩短训练的epoch,大幅提升novel性能从而增加HM。
要根本上改进这个问题,就需要改进或者reformulate自coop提出以来的learnable prompt形式,而不是不停的加各种正则化项(这不elegant)。我们的目标是要让prompt中不能够只含有class token,而要包含一些其他有意义的token来促进识别。
所以在ATPrompt里,我们就首先提出通过引入一些额外的属性作为锚点嵌入在soft tokens+class token中,引导软词元在适配到下游任务的过程中,不仅拟合已知类别,还能够学到更多的与属性相关的通用信息。相比于原来的coop,训练时以无额外代价的方式增加模型对于未知类别的泛化能力。
展望
ATPrompt所做的事情只是对于高效learnable prompt结构设计的一小步,我们希望抛砖引玉,未来能够有更多的工作关注在设计高效结构上,使得能够不过度依赖正则化loss,通过良好的prompt结构,soft token通过训练就能够达到comparable的性能。
常见问题解答
Q1: 用提示学习微调VLMs有什么实际意义?
A1: VLM的模型如CLIP,拥有非常好的零样本泛化能力,可以作为基础模型部署在许多业务场景里。
但是CLIP的优势往往指的是对通用类别的识别上,在对于特定类别数据,例如猫狗和飞机类型的细粒度鉴别,或者罕见类别的识别,往往性能表现不行。
这时要提升模型在特定任务上的预测性能,一种直接的做法是全参数微调,但是这需要大量的image-text pair数据训练,费时费力,如果仅有少量训练数据,则可能会让CLIP overfit到下游数据上,破坏原先的泛化性能。
另一种可行的做法就是用提示学习,通过引入少量可学习参数去微调CLIP,因为参数量少,所以对于训练数据量需求低,又因为不涉及参数模块(例如fc层)的训练,在遇到未知类时能够保持CLIP原始的零样本泛化性能。
Q2: 学习到的属性是每个样本都有一个吗?
A2:不是的,是整个数据集只对应一个。在属性搜索阶段,整个数据集只对应一个weight vector,在训练完成后,会选择vector中score最高的对应的属性作为目标属性用于接下来的ATPrompt提示学习训练。
参考
[1] Learning Transferable Visual Models From Natural Language Supervision. ICML 21.
[2] Learning to Prompt for Vision-Language Models. IJCV 22.
[3] Conditional Prompt Learning for Vision-Language Models. CVPR 22.
[4] MaPLe: Multi-modal Prompt Learning. CVPR 23.
[5] Read-only Prompt Optimization for Vision-Language Few-shot Learning. ICCV 23.
[6] Self-regulating Prompts: Foundational Model Adaptation without Forgetting. ICCV 2023.
[7] Visual-Language Prompt Tuning with Knowledge-guided Context Optimization. CVPR 2023.
[8] Prompt-aligned Gradient for Prompt Tuning. ICCV 2023.
[9] PromptKD: Unsupervised Prompt Distillation for Vision-Language Models. CVPR 2024.
[10] DARTS: Differentiable Architecture Search. ICLR 2019.
(文:极市干货)