RAG检索系统的两大核心利器——Embedding模型和Rerank模型
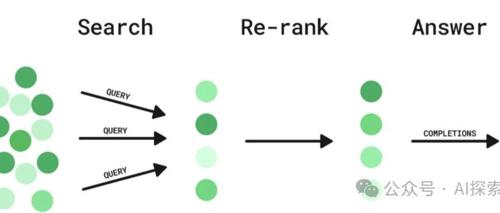
在RAG系统中,Embedding和Rerank模型是核心组成部分。前者将文本转化为低维向量以捕捉语义信息;后者则用于对候选结果进行重排序,提升其相关性。
在RAG系统中,Embedding和Rerank模型是核心组成部分。前者将文本转化为低维向量以捕捉语义信息;后者则用于对候选结果进行重排序,提升其相关性。
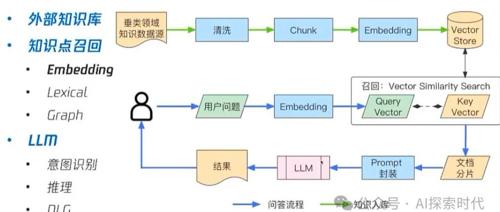
最近在RAG项目中使用milvus向量数据库时遇到问题,文档格式复杂导致相似度较低,提出通过重排序、多路召回等方式解决数据干扰因素变多的问题。
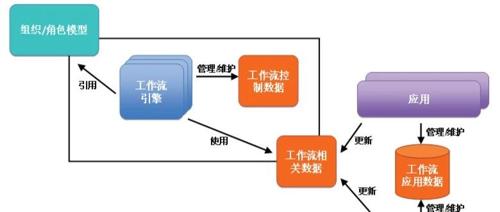
文章介绍了工作流与智能体在自动化任务中的作用,并指出其作为中间解决方案来解决大模型能力不足的问题。工作流通过定义执行流程并使用不同的工具(包括智能体)来完成特定任务。目前有很多平台支持这种工作流技术,如字节跳动的coze平台、开源Dify和德国产n8n等。

文章讲述了作者从技术开发转向人工智能技术服务创业的想法及可行性分析。作者认为选择垂直领域切入,并结合自身技术优势为中小企业提供解决方案是一个可行的选择。
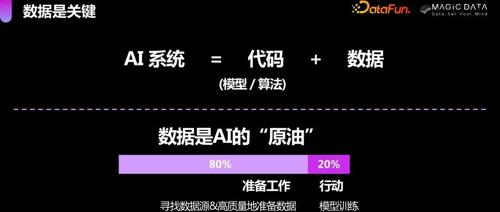
阿里开源的Qwen2.5系列训练数据规模达18万亿 token,推动AI大模型发展。但大规模训练带来幻象问题,RAG技术及工业场景应用以数据为中心成为趋势。国家和行业正积极推进数据标注产业发展规范,提升数据标注行业的合规能力。