
“ Embedding和Rerank模型是RAG系统中的核心模型。”
在RAG系统中,有两个非常重要的模型一个是Embedding模型,另一个则是Rerank模型;这两个模型在RAG中扮演着重要角色。
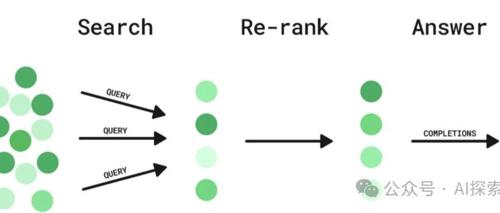
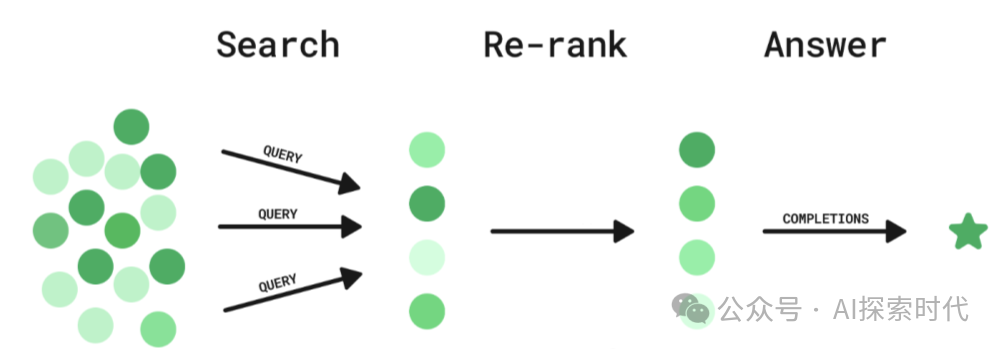
Embedding模型的作用是把数据向量化,通过降维的方式,使得可以通过欧式距离,余弦函数等计算向量之间的相似度,以此来进行相似度检索。
而Rerank的作用是在Embedding检索的基础之上,进行更加准确的数据筛选;如果说Embedding模型进行的是一维筛选,那么Rerank模型就是从多个维度进行筛选。

Embedding模型和Rerank模型
在自然语言处理和信息检索系统中,Embedding模型和Rerank模型是两类功能不同但常结合使用的技术。
Embedding和Rerank模型都是基于深度学习方式实现的神经网络模型,但由于其功能不同,因此其实现方式和训练方法也有一定的区别。
从使用的角度来看,Embedding一般用于数据向量化并快速检索,而Rerank模型是在快速检索的基础之上进行重排序,提升相似度。
但从技术实现的角度来说,两种模型使用的学习方式和架构是不一样的;原因就在于两个模型的实现目的和处理数据的方式。
它们的核心区别在于目标、应用阶段和技术实现。以下是详细对比:
1. 功能目标
| 维度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 核心任务 |
|
|
| 输出形式 |
|
|
| 关注点 |
|
|
示例
-
Embedding模型:将“如何训练神经网络?”转换为向量,用于检索相似问题。
-
Rerank模型:对初步检索的100个答案排序,将最相关的答案排到前3。
2. 应用阶段
| 维度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 所处流程 | 检索阶段
|
精排阶段
|
| 数据规模 |
|
|
| 性能要求 |
|
|
典型场景
-
Embedding模型:用于搜索引擎的初步召回(如从10亿文档中筛选出Top 1000)。
-
Rerank模型:在推荐系统中对Top 100结果精细化排序,提升点击率。
3. 技术实现
| 维度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 模型类型 |
|
|
| 输入输出 |
|
|
| 特征依赖 |
|
|
模型举例
-
Embedding模型:
-
通用语义编码:BERT、RoBERTa
-
专用场景:DPR(Dense Passage Retrieval)
-
Rerank模型:
-
传统方法:BM25 + 特征工程
-
深度模型:ColBERT、Cross-Encoder
(文:AI探索时代)