
视频理解

视频理解“隐秘的角落”:多任务视频文本理解评测新基准VidText发布

VidText 提出了一套全面的视频文本理解基准,覆盖 27 个真实场景和多种语言。它包含从视觉感知到跨模态推理的多个任务,评估模型在不同粒度上的表现,并揭示了影响性能的关键因素。
Pixel Reasoner:滑铁卢等高校联合打造的视觉语言模型,用好奇心驱动的强化学习解锁视觉推理新高度!
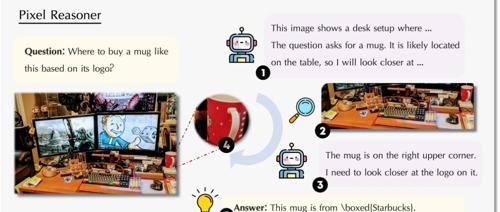
Pixel Reasoner 是一款基于像素空间推理增强的视觉语言模型,通过直接操作视觉输入提升对视觉细节的捕捉能力。它结合指令调优和好奇心驱动的强化学习,在多个视觉推理基准测试中表现出色。
AI 看片写 App!Gemini 2.5 首创音视频+代码原生融合+视频理解 SOTA,构建案例来了~

Google更新了两款Gemini新模型Gemini 2.5 Pro和Gemini 2.5 Flash,在视频理解和生成方面表现突出,能生成互动应用、p5.js动画及精准描述视频片段。
Gemini 2.5 Pro登顶三冠王!AI最强编程屠榜,全面碾压Claude 3.7

谷歌发布升级版Gemini 2.5 Pro,横扫文本、视觉和WebDev Arena基准,编程能力超越Claude 3.7。新版模型支持代码转换、编辑及复杂的AI智能体工作流,引发开发者广泛关注。
Gemini 2.5 Pro:编码再进化与AI能力边界新思考

谷歌发布的Gemini 2.5 Pro I/O预览版在编码能力上显著提升,尤其在前端开发和视频内容转化方面表现突出。尽管减少API“幻觉”进步获得肯定,但AI在高级代码抽象、软件架构设计及非主流技术栈的处理仍存审慎态度。
刚刚,Gemini 2.5 Pro升级,成编程模型新王

Google DeepMind的Gemini 2.5 Pro更新提升了编程能力和多模态推理功能,可构建Web应用、游戏和模拟程序,并根据自然图像生成代码。

社区供稿 | 阿里国际 Ovis2 系列模型开源: 多模态大语言模型的新突破
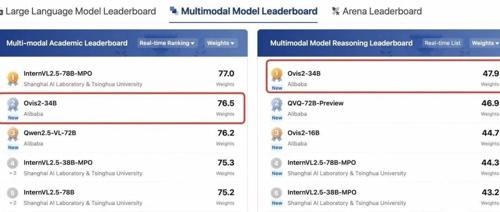
Ovis2是阿里巴巴提出的新型多模态大模型架构,显著提升了小规模和大规模模型的能力密度,并增强了思维链推理能力、视频处理能力和多语言OCR能力。它已在OpenCompass上展示了卓越的性能,并在多个数学推理榜单中排名前列。
北航推出TinyLLaVA-Video,有限计算资源优于部分7B模型,代码、模型、训练数据全开源

北京航空航天大学团队发布小尺寸简易视频理解框架TinyLLaVA-Video,其参数量不超过4B,在多个视频理解基准上优于7B以上模型。该项目开源模型权重、训练代码和数据集,并支持模块化设计和自定义训练策略,降低研究门槛。