
上海交通大学

DeepSeek“防弹衣”来了,模型内生安全加固方案,拒绝杀敌一千自损八百|上海AI Lab

最新研究显示DeepSeek-R1模型存在安全隐患。上海交大与上海AI Lab联合提出X-Boundary防御方案,通过分离安全和有害表征并定向消除有害表征来实现精准高效的安全加固,避免了过度安全导致的模型性能下降的问题。
自动调整推理链长度,SCoT来了!为激发推理能力研究还提出了一个新架构

SCoT团队提出了一种新的推理范式SCoT,它能动态调整推理链长度来适应不同复杂度的问题。AtomThink框架则是一个全过程训练和评估的系统,旨在提升多模态大模型在复杂推理任务上的表现。
CVPR满分论文!一块2080Ti搞定数据蒸馏,GPU占用仅2G
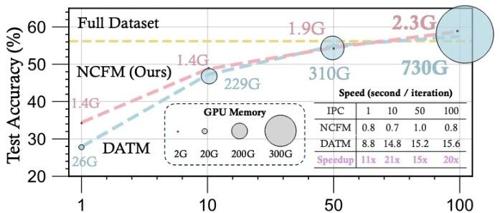
上交大EPIC实验室提出的新方法NCFM,利用辅助神经网络将数据集蒸馏转化为极小化极大优化问题。该方法在多个基准数据集中实现了显著性能提升,并展示了出色的可扩展性和下游任务应用能力。
上交CVPR 满分论文数据蒸馏技术,直接把 GPU 显存 “砍掉” 300 倍

一项研究提出了一种新的数据集蒸馏方法NCFM (Neural Characteristic Function Matching),大幅提升了性能并实现了资源效率的飞跃。它通过引入神经特征函数差异度量指标,解决了现有方法的局限性,仅需2.3GB显存即可在单张GPU上完成CIFAR-100无损蒸馏,并显著超越了现有的SOTA方法。
CVPR满分论文:一块2080Ti搞定数据蒸馏,GPU占用仅2G,来自上交大“最年轻博导”课题组
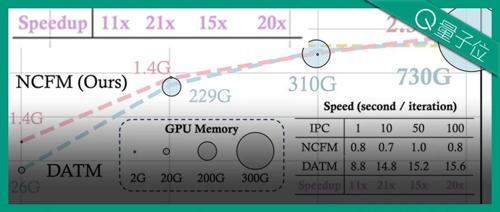
上交大EPIC实验室提出的新方法NFCM将数据集蒸馏转化为极小化极大优化问题,显著减少了显存占用和提升了训练速度,并且在多个基准数据集中取得了优异性能。
无需训练让扩散模型提速2倍,上交大提出Token级缓存方案|ICLR‘25

上海交通大学张林峰团队提出Toca方法,通过token粒度的缓存策略实现无需训练的图像和视频生成加速,相比现有方法具有更强适配性和优异性能。
机器人视觉控制新范式!ByteDance Research新算法实现通过性能SOTA

ByteDance Research团队提出WMP(World Model-based Perception),通过模拟训练世界模型和策略,实现在多种复杂地形上的出色控制表现。
视频版IC-Light来了!Light-A-Video提出渐进式光照融合,免训练一键视频重打光

上海交通大学等联合研发的Light-A-Video技术无需训练即可实现零样本视频重打光,解决了视频编辑中的关键技术难题。该方法利用预训练模型和创新模块确保光照一致性和稳定性。
DeepSeek团队新作:把代码变成思维链,大模型推理各种能力全面提升
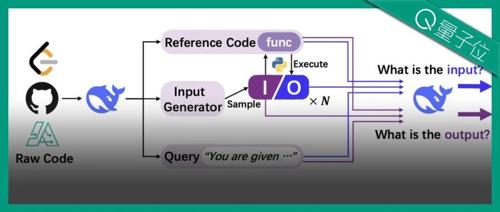
利用300多万个实例将代码转换成思考过程构建数据集CODEI/O,提升Qwen、Llama等模型推理能力,覆盖常识、数学、代码、物理、工程等多个领域。