
MATH基准测试
8块A100,32B碾压DeepSeek V3、o1-preview!普林斯顿北大首提分层RL推理

座。普林斯顿联手北大提出全新ReasonFlux框架,直接AIME上碾压o1-preiview。
仅
仅817样本超越o1-preview,上交大LIMO”少即是多”推理新范式
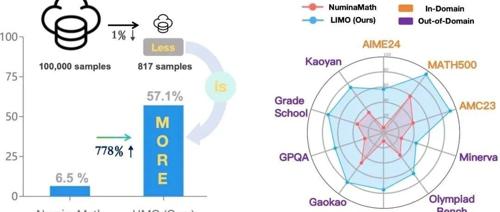
LIMO提出了一种新的假设:基础模型中已全面编码领域知识,在预训练阶段通过最少但精心策划的认知过程可以激发复杂的推理能力。使用817个高质量问题和相应的推理链进行监督式微调的Qwen2.5-32B-Instruct模型在数学基准测试中的表现显著优于先前的工作。