OpenAI 开源gpt-oss权重,Huggingface开源微调gpt-oss权重方法 2025年8月6日12时 作者 每日AI新工具 的 gpt-oss 项目发布了 gpt-oss-120b 和 gpt-oss-20b 两款开放权重模
Tile级原语与自动推理机制融合,TileAI社区发起人深度剖析TileLang核心技术与优势 2025年7月23日23时 作者 HyperAI超神经 「Bridge Programmability and Performance in Modern
斯坦福意外用AI生成超强CUDA内核,性能比人类专家优化得还要好!翻倍碾压原生PyTorch,华人主创 2025年5月31日16时 作者 量子位 斯坦福团队通过意外发现,由AI生成的内核性能超越了人类专家专门优化过的版本。这项研究展示了大模型在探索高级优化和硬件特性的能力。
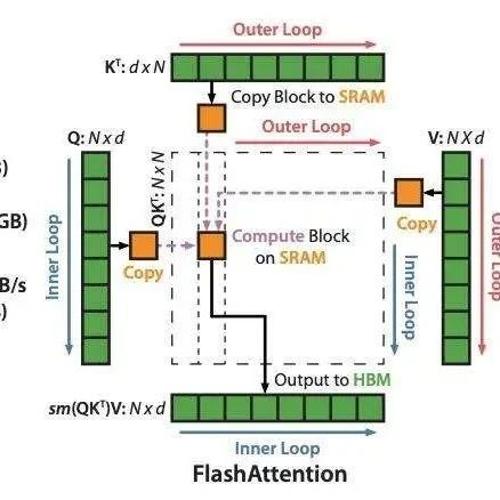
结合代码聊聊FlashAttentionV3前向过程的原理 2025年3月18日23时 作者 极市干货 绍了FlashAttentionV3(FA3)的前向过程原理,结合代码分析了其数学公式和工程实现的细
在长文本上比Flash Attention快10倍!清华等提出APB序列并行推理框架 2025年3月12日12时 作者 机器之心 线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。 随之
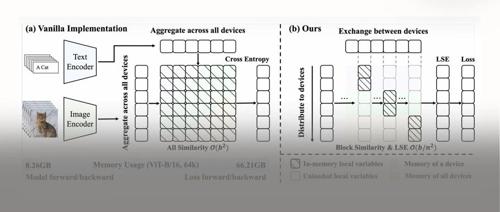
Inf-CL: 把 Contrastive Loss 的 Batch Size 冲到100M! 2024年11月24日23时 作者 极市干货 ↑ 点击 蓝字 关注极市平台 作者丨藤原豆腐皮儿@知乎(已授权) 来源丨https://zhuanl