
罕见!苹果开源VLM视觉语言模型,首令牌速度提高85倍,以后的AI服务一定会越来越便宜。

苹果开发的高效视觉语言模型FastVLM采用新型混合视觉编码器FastViTHD,实现高分辨率图像处理速度提升3.2倍的同时保持精度。
苹果开发的高效视觉语言模型FastVLM采用新型混合视觉编码器FastViTHD,实现高分辨率图像处理速度提升3.2倍的同时保持精度。
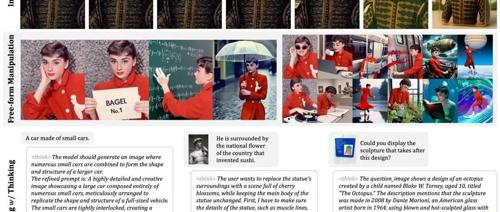
BAGEL 是一个开源多模态基础模型,拥有70亿活跃参数,在标准多模态理解排行榜上超越了当前顶尖开源模型,并展示了高级编辑能力及扩展至世界建模的能力。
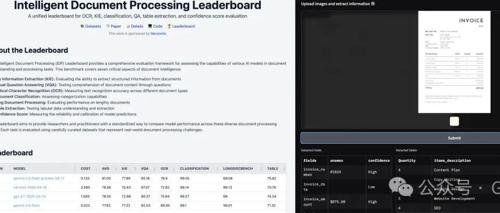
docext是无需OCR的新工具,用于从发票和护照等文档图像中提取结构化信息。它利用视觉语言模型准确识别并提取数据和表格信息。智能文档处理排行榜追踪和评估其在关键任务中的表现。
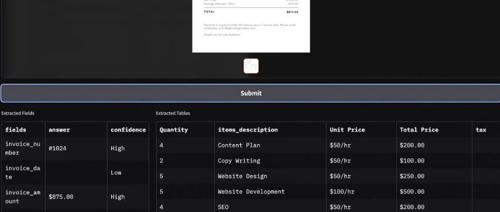
Docext 是一个基于视觉语言模型的文档结构化信息提取工具,支持发票、护照等敏感文档处理。它通过本地部署确保数据隐私,并提供自定义字段和表格提取功能,适用于多种场景如发票管理、证件录入等。

研究提出「描述一切模型」(DAM),能生成图像或视频中特定区域的详细描述。用户可通过点、框等方式指定区域,DAM则提供丰富的上下文描述。此模型在多个任务中均表现优异,并支持多粒度输出。

近日,大连理工大学与莫纳什大学的研究团队提出VLIPP框架,通过引入物理规律提升视频生成的物理真实性。论文指出视频扩散模型在物理场景下表现不佳的原因,并提出两阶段方法,利用视觉语言模型预测运动路径,再用细粒度的视频扩散模型生成符合物理规则的视频。

阿里千问开源Qwen2.5-VL-32B-Instruct,提升视觉语言能力与数学推理。相比同类模型,其在多模态任务中表现显著优势,且在同规模纯文本能力上也取得顶级表现。

文章介绍了一篇关于对抗攻击的研究成果,该研究提出了一种新的方法M-Attack来提高对大型视觉语言模型的攻击成功率,并成功应用于多个商业模型中。

