
仅用图像也能Think:Google等提出一种视觉规划的全新推理范式!
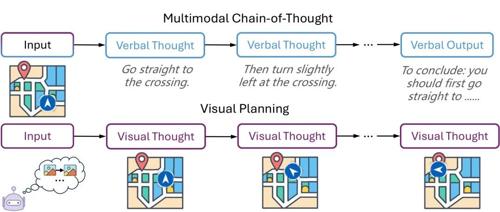
剑桥&Google提出视觉规划新范式Visual Planning,通过纯视觉表示进行规划,独立于文本。VPRL框架结合强化学习和GRPO技术优化视觉模型生成有效视觉轨迹。
剑桥&Google提出视觉规划新范式Visual Planning,通过纯视觉表示进行规划,独立于文本。VPRL框架结合强化学习和GRPO技术优化视觉模型生成有效视觉轨迹。
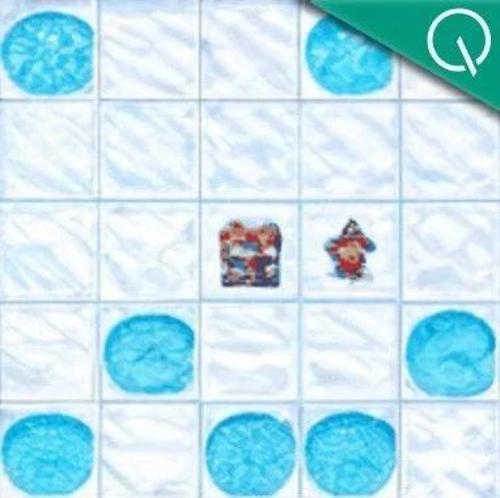
研究团队提出基于强化学习的视觉规划(VPRL)新范式,实现图像直接驱动推理,显著优于文本规划方法,未来有望推动多模态推理向更直观方向发展。
