
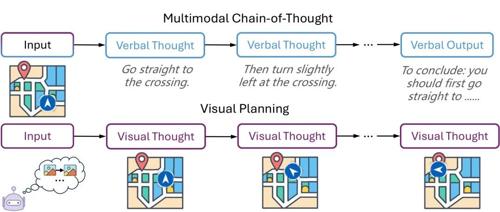

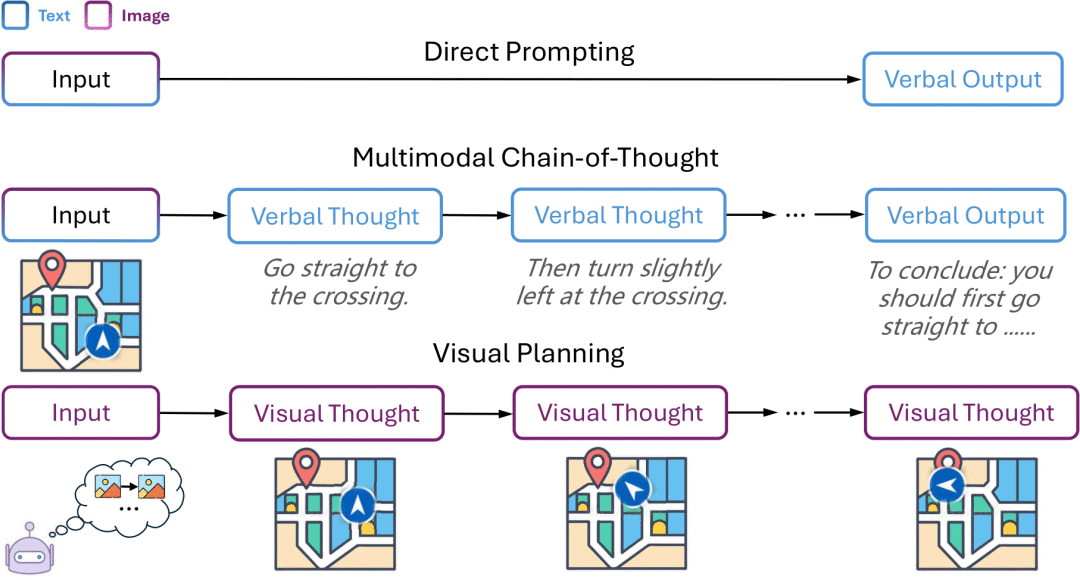
-
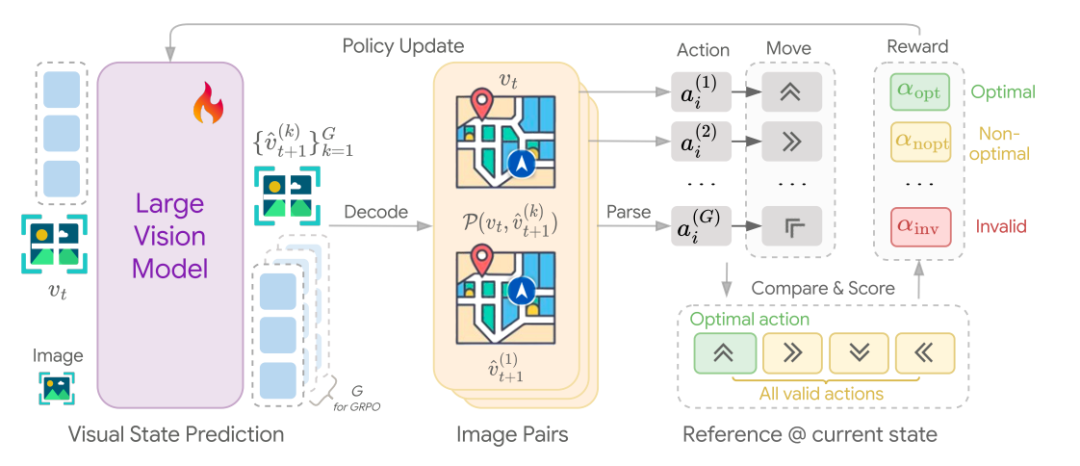
第一阶段:策略初始化(Policy Initialization):
-
使用随机游走(random walks)生成的轨迹来初始化模型,目的是让模型在模拟环境中生成有效的视觉状态序列,并保留探索能力。
-
通过监督学习(supervised learning)对模型进行训练,使其能够生成与随机游走相似的视觉轨迹。
-
训练过程中,模型从每个轨迹中提取图像对,并从多个有效轨迹中随机选择一个作为监督目标,以防止过拟合并鼓励随机性。
-
第二阶段:强化学习优化(Reinforcement Learning Optimization):
-
在第一阶段的基础上,利用强化学习(RL)进一步优化模型,使其能够生成更有效的视觉规划。
-
引入了GRPO(Group Relative Policy Optimization)算法,通过比较候选响应的相对优势来提供训练信号,从而避免了学习评估函数(critic)的复杂性。
-
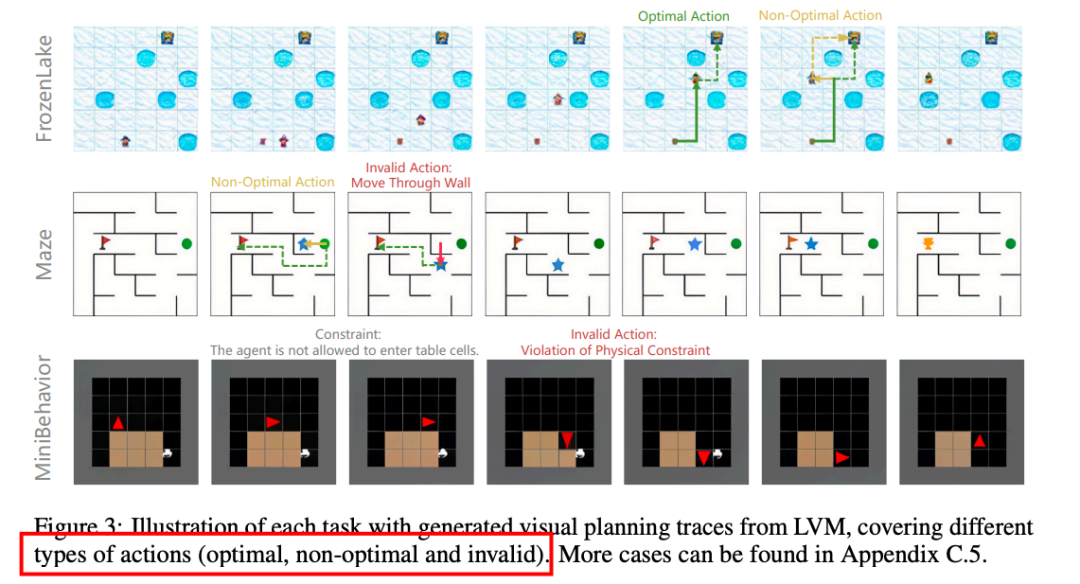
设计了一个基于进度的奖励函数(progress reward function),该函数通过比较当前状态和生成的候选状态之间的进度差异来评估动作的有效性。奖励函数分为三类:最优动作(optimal actions)、非最优动作(non-optimal actions)和无效动作(invalid actions),分别给予不同的奖励值。



https://arxiv.org/pdf/2505.11409https://github.com/yix8/VisualPlanningVisual Planning: Let’s Think Only with Images
(文:PaperAgent)