
注意力机制


字节最新大模型秘籍:只挑能有推理潜力的数据训练!1.3B模型无需标签自动挑选
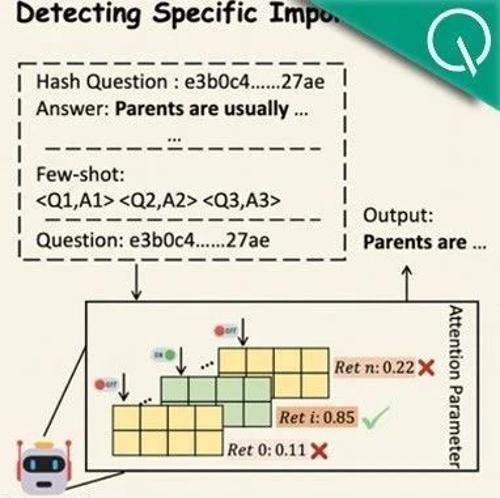
字节Seed团队提出AttentionInfluence方法,利用小型预训练模型选择对大语言模型推理能力有显著提升的数据。通过屏蔽关键头部并计算损失差异来评估数据重要性,最终在多个基准测试中提高了模型性能。
ICML 2025 视频生成模型无损加速两倍,秘诀竟然是「抓住attention的时空稀疏性」

Sparse VideoGen 提出了一种无需重新训练模型的方法来加速视频生成过程。通过挖掘注意力机制中的空间与时间稀疏性,该方法成功将推理时间减半,并保持了接近原模型的视觉质量。
大模型是怎么“思考”的?五分钟看懂大模型的底层逻辑!
近年来ChatGPT爆火,让大语言模型走进大众视野。本文系统梳理了其原理、训练方式及其应用,涵盖数据、架构和训练三大要素,并展示了微调与实际应用场景,如客户服务、内容创作等。

继VAE之后,Adam也拿到了ICLR 时间检验奖,OpenAI联创两次获奖

ICLR 2025 宣布 Adam 算法和 Neural Machine Translation by Jointly Learning to Align and Translate 分获时间检验奖一、二名。Adam 是深度学习领域应用最广泛的优化算法之一,而 Transformer 论文则较早引入注意力机制。
刚刚,ICLR 2025时间检验奖颁给Adam之父!Bengio「注意力机制」摘亚军

ICLR 2025时间检验奖揭晓,Adam优化器和注意力机制分别由Jimmy Ba、Yoshua Bengio领衔的两篇2015年论文摘得冠军与亚军。Adam让大模型训练更快更稳;注意力机制为Transformer奠定基础并广泛应用于各类AI模型。
VecSetX:基于VecSet框架的先进向量集合表示方法

VecSetX:一种先进的向量集合表示方法,采用多层注意力机制提升性能,引入SDF回归替代传统分类,并使用Flash Attention加速训练。
1000万上下文+2880亿参数的Llama4,却让DeepSeek们松了一口气

Meta发布的Llama4系列模型包括多模态MoE架构、超长上下文支持和优化的注意力机制。通过原生多模态预训练融合方法、轻量级后训练策略等创新技术提升了模型能力。