
视频生成1.3B碾压14B、图像生成直逼GPT-4o!港科&快手开源测试时扩展新范式

香港科技大学联合快手可灵团队提出EvoSearch方法,通过演化搜索提升视觉生成模型的性能。该方法无需训练参数,仅需计算资源即可在多个任务上取得显著最优效果,并且具有良好的扩展性和泛化性。
香港科技大学联合快手可灵团队提出EvoSearch方法,通过演化搜索提升视觉生成模型的性能。该方法无需训练参数,仅需计算资源即可在多个任务上取得显著最优效果,并且具有良好的扩展性和泛化性。
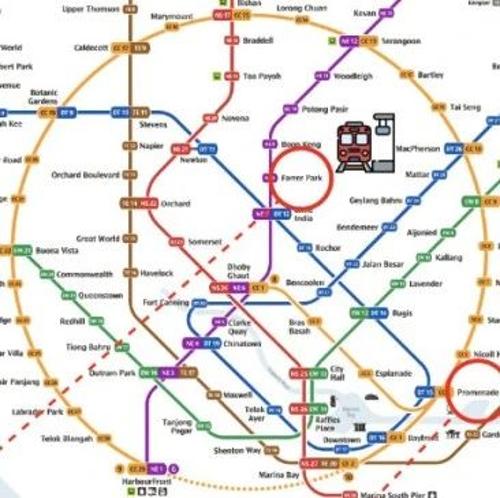
ReasonMap 是首个聚焦于高分辨率交通图的多模态推理评测基准,用于评估大模型在理解图像细粒度结构化空间信息方面的能力。

新晋图灵奖得主Richard Sutton预测大模型主导是暂时的,未来五年甚至十年内AI和强化学习将转向通过Agent与世界的第一人称交互获取‘体验数据’的学习。他强调AI需要新的数据来源,并且要随着增强而改进。他认为真正的突破还是来自规模计算。

西湖大学研究团队提出SLOT方法,在推理时通过优化delta参数向量调整输出词汇概率分布,显著提升语言模型在复杂指令上的表现。
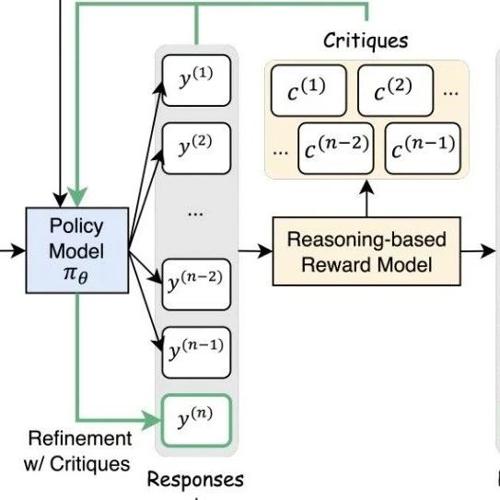
MLNLP社区是国内外知名的人工智能和技术交流平台,旨在促进机器学习和自然语言处理领域内的学术与产业界的交流合作。近日发布的论文探讨了改进语言模型推理能力的方法,并提出了一种名为Critique-GRPO的技术方案。

本文研究了语言模型对强化学习中奖励噪声的鲁棒性,即使翻转大部分奖励也能保持高下游任务表现。作者提出了思考模式奖励机制,并展示了其在数学和AI帮助性回复生成任务中的有效性。

特斯拉员工Milan Kovac因个人原因离职,Optimus项目负责人职务暂由Ashok Elluswamy接任。马斯克和特斯拉面临新挑战,近期股价波动加剧了公司的经营压力。


