
谷歌DeepMind深夜放核弹:世界模型Genie 3登场,重新定义“生成式AI”

谷歌DeepMind发布第三代通用世界模型Genie 3,可以生成实时交互式环境,实现实时导航、一致性和高分辨率。其突破包括实时性能、长时程一致性以及可提示的世界事件能力。
谷歌DeepMind发布第三代通用世界模型Genie 3,可以生成实时交互式环境,实现实时导航、一致性和高分辨率。其突破包括实时性能、长时程一致性以及可提示的世界事件能力。

Midjourney推出视频生成模型V1,主打高性价比、易于上手的视频生成功能。用户可以通过动画化图片或自己的图片来创作短视频,支持手动和自动两种模式,最低每月10美元即可使用,目标是构建实时交互的开放世界模拟系统。

本文介绍了一篇被ACL 2025主会议接收的语音语言模型综述论文,该文由香港中文大学团队撰写。文章探讨了当前语音大模型的发展及其在自然对话、实时交互等方面的应用前景,并提出了未来研究的重点和挑战。
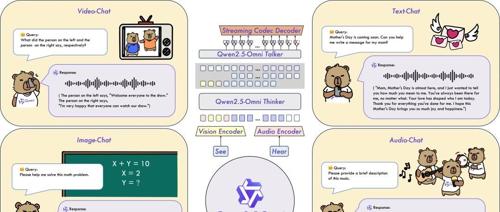
Qwen2.5-Omni 是一款端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,并以流式方式生成文本和语音响应。其关键特性包括Thinker-Talker架构、TMRoPE位置嵌入技术以及跨模态卓越性能等。
阿里巴巴开源的Qwen2.5-Omni大模型支持全模态感知与生成、实时交互和语音生成。Cursor Auto Register帮助用户自动化注册Cursor账号。字节跳动开发的FlowGram.AI是节点式工作流引擎,利用AI能力增强工作流程。n8n MCP Server是一个让AI助手通过自然语言控制n8n工作流的模型上下文协议服务器。LangGraph CUA库构建具有计算机操作能力的智能代理系统。

