
量化技术



在CPU上运行100B模型只需4MB内存!微软BitNet掀了英伟达的桌子!
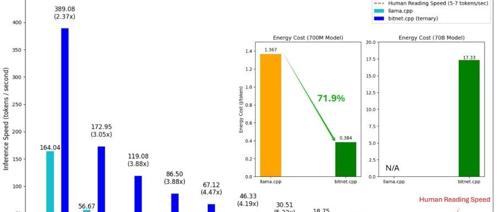
微软发布BitNet推理框架,通过三值量化将LLM模型大小瘦身至原来的1/16,在CPU上实现2.37到6.17倍加速,并节能82.2%,甚至可在普通笔记本CPU上运行100B参数级大模型。

FP8训练新范式:减少40%显存占用,训练速度提高1.4倍

近期研究提出COAT方法利用FP8量化技术,通过动态范围扩展和混合粒度精度流优化大型模型训练中的内存占用和加速速度,保持模型精度的同时显著减少显存使用并提升训练效率。
DeepSeek-R1秘籍轻松迁移,最低只需原始数据0.3% 邱锡鹏团队联合出品

研究人员提出MHA2MLA方法,通过微调预训练模型减少KV缓存大小90%,保持甚至提升性能。该技术利用低秩联合压缩键值技术和分组查询注意力策略,降低推理成本的同时维持精度。

英伟达视频模型Magic 1-For-1,1 分钟生成 1 分钟视频,且开源

近日英伟达联合北京大学和Hedra Inc开源了Magic 1-For-1 AI视频生成模型,其特点是生成速度快且开源,并通过量化技术将模型体积从32GB压缩至16GB。该模型支持多模态输入、扩散步骤蒸馏等技术。缺点在于高速运动场景的处理能力有限,以及视频分辨率较低。