本文是对 Manus 创始人季逸超(Jiyichao)在其博客上发表的《Context Engineering for AI Agents: Lessons from Building Manus》一文的全文翻译。
这篇文章并非空泛的理论,而是 Manus 团队在构建 AI 智能体时,从无数次失败、踩坑和迭代中提炼出的宝贵实战经验,充满了在战壕里摸爬滚打后总结出的真知灼见。我们希望通过这次翻译,将这些宝贵的实战经验分享给更多中文世界的开发者。
出品丨AI 科技大本营(ID:rgznai100)
原文 | https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
在 Manus 项目伊始,我和团队面临一个关键抉择:是应该利用开源基础模型来训练一个端到端的 Agent,还是基于前沿模型的上下文学习(in-context learning)能力来构建?
回溯我从事自然语言处理(NLP)的头十年,我们根本没有这样的选择。在遥远的 BERT 时代(是的,已经七年了),模型必须先经过微调和评估,才能胜任新任务。尽管那时的模型比今天的大语言模型(LLM)小得多,但这个过程每次迭代仍需数周。
对于快速变化的应用,尤其是在产品尚未与市场契合(pre-PMF)的阶段,如此缓慢的反馈循环是致命的。这是我上一次创业时得到的惨痛教训,当时我为了实现开放信息抽取和语义搜索,从零开始训练模型。然而,GPT-3 和 Flan-T5 的横空出世,让我自研的模型一夜之间变得毫无价值。讽刺的是,也正是这些模型,开启了上下文学习的时代,并指明了一条全新的道路。
这个来之不易的教训让我们的选择变得异常清晰:Manus 将赌注押在上下文工程(Context Engineering)上。这使我们能将产品改进的周期从数周缩短至几小时,并让我们的产品与底层模型的发展保持正交:如果说模型技术的进步是上涨的潮水,我们希望 Manus 是水涨船高的船,而非被固定在海床上的桥墩。
即便如此,上下文工程的实践之路也远非一帆风顺。它是一门实验科学——我们已经重构了四次 Agent 框架,每一次都是因为发现了塑造上下文的更优方法。我们将这种手动进行架构搜索、调试提示(prompt)和凭经验猜测的摸索过程,戏称为“随机研究生下降”(Stochastic Graduate Descent)——这是对“随机梯度下降”(Stochastic Gradient Descent)的一个文字游戏。这个方法听起来不那么优雅,但确实有效。
本文将分享我们通过自己的“SGD”方法所摸索出的局部最优解。如果你也在构建自己的 AI Agent,希望这些原则能帮助你更快地找到方向。
围绕 KV 缓存进行设计
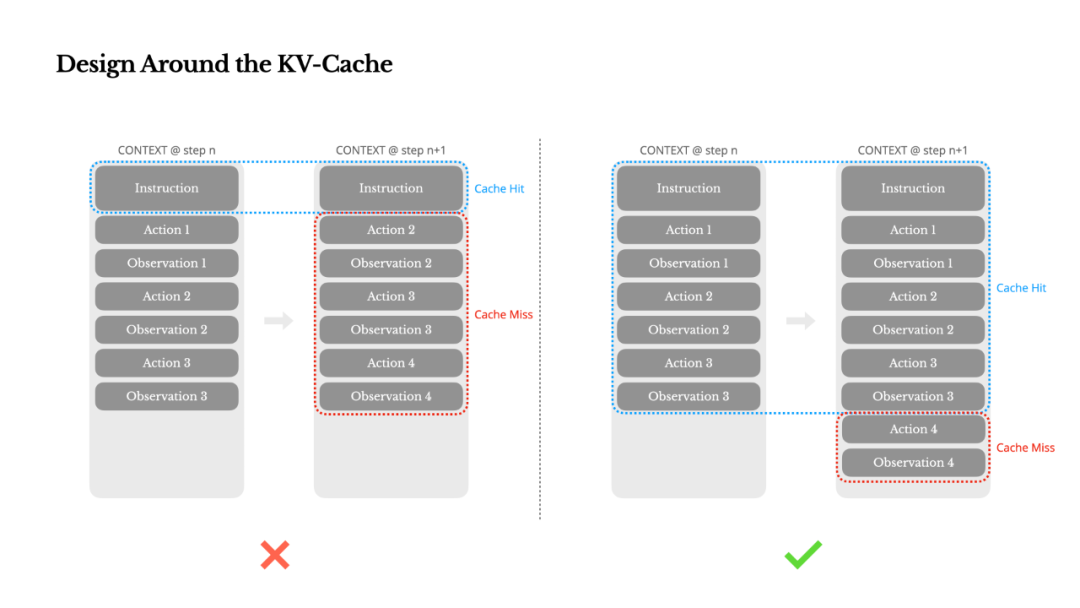
如果非要我只选一个指标,我认为 KV 缓存命中率(KV-cache hit rate)是生产级 AI Agent 最重要的单一指标,因为它直接影响延迟和成本。要理解这一点,我们先来看看一个典型 Agent 的工作流程:
收到用户输入后,Agent 会通过一系列工具调用来完成任务。在每次迭代中,模型根据当前上下文,从预定义的操作空间中选择一个动作。该动作在环境(如 Manus 的虚拟机沙箱)中执行后,产生一个观察结果。这个动作和观察结果会被追加到上下文中,作为下一次迭代的输入。此循环不断重复,直至任务完成。
可以想见,上下文会随着每一步而增长,而输出——通常是一个结构化的函数调用——则相对较短。这使得 Agent 的输入与输出 token 比例,和聊天机器人相比严重失衡。例如,在 Manus 中,这个比例平均约为 100:1。
幸运的是,拥有相同前缀的上下文可以利用 KV 缓存,从而大幅降低首个 token 生成时间(TTFT)和推理成本——无论你使用的是自托管模型还是第三方推理 API。这带来的成本节约是巨大的:以 Claude Sonnet 为例,缓存过的输入 token 成本为 0.30 美元/百万 token,而未缓存的则为 3 美元/百万 token,成本相差整整 10 倍。
从上下文工程的角度看,提高 KV 缓存命中率有几个关键实践:
-
保持提示词前缀的稳定性。由于 LLM 的自回归特性,哪怕只有一个 token 的差异,也会使该 token 之后的所有缓存失效。一个常见错误是在系统提示的开头包含时间戳——尤其是精确到秒的时间戳。这固然能让模型告知当前时间,但也会彻底破坏你的缓存命中率。
-
让上下文只增不减(append-only)。避免修改历史动作或观察结果。同时要确保序列化过程是确定性的。许多编程语言和库在序列化 JSON 对象时,不保证键的顺序稳定,这会悄无声息地破坏缓存。
-
在需要时明确标记缓存断点。一些模型提供商或推理框架不支持自动的增量前缀缓存,需要手动在上下文中插入缓存断点。在设置断点时,要考虑到缓存的生命周期,并至少确保断点设在系统提示之后。
此外,如果你在使用 vLLM 等框架自托管模型,请确保启用了前缀/提示缓存功能,并使用会话 ID 等技术,将来自同一用户的请求持续路由到固定的工作节点上。
AI产品爆发,但你的痛点解决了吗?8.15-16 北京威斯汀·全球产品经理大会PM-Summit,3000+AI产品人社群已就位。
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
巧用掩码,而非直接移除
随着 Agent 的能力不断扩展,其操作空间(Action Space)会自然变得愈发复杂——简而言之,工具的数量会爆炸式增长。近期流行的 MCP 更是火上浇油。如果允许用户自定义工具,那总会有人把成百上千个稀奇古怪的工具塞进你精心设计的操作空间里。其结果是,模型更容易选错工具或采取低效路径。一言以蔽之,全副武装的 Agent 反而变笨了。
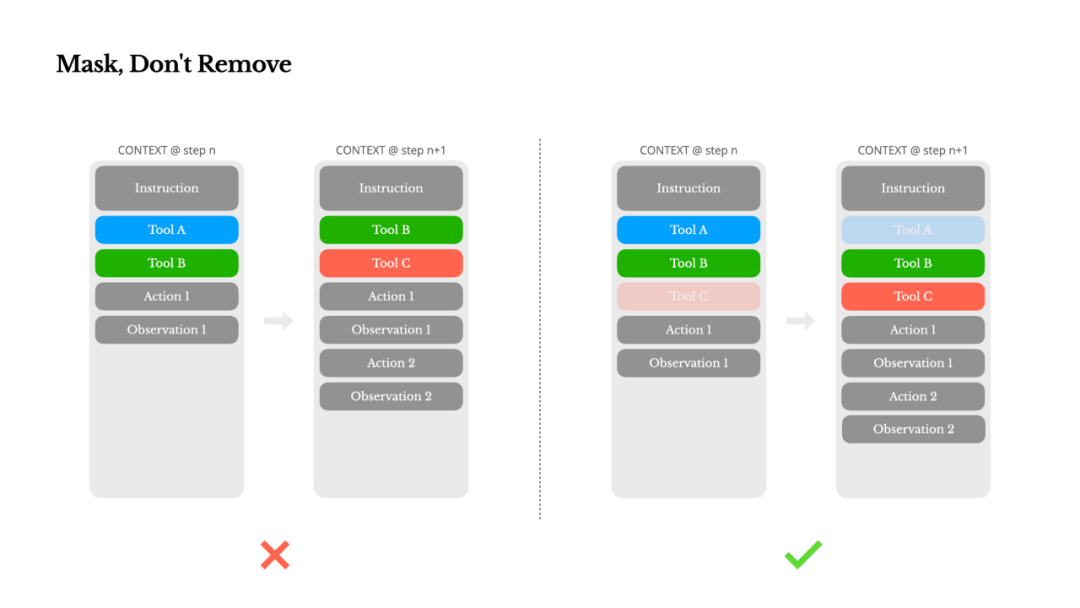
一个自然的想法是设计一个动态的操作空间——比如用类似 RAG 的方式按需加载工具。我们在 Manus 中也尝试过。但实验得出了一个明确的结论:除非绝对必要,否则不要在迭代过程中动态增删工具。 主要原因有二:
-
在大多数 LLM 中,工具定义在序列化后位于上下文的前部,通常紧跟在系统提示之后。因此,任何改动都会导致后续所有动作和观察结果的 KV 缓存全部失效。
-
如果历史动作和观察结果引用了当前上下文中已不复存在的工具,模型就会感到困惑。若不进行约束解码,这通常会导致输出格式错误(schema violation)或产生幻觉动作。
为了解决这个问题,同时又能优化动作选择,Manus 采用了一个感知上下文的状态机来管理工具的可用性。它并非直接移除工具,而是在解码阶段对 token 的对数几率(logits)进行掩码(masking),从而根据当前状态,阻止或强制模型选择某些动作。
实践中,大多数模型提供商和推理框架都支持某种形式的响应预填充(response prefill),让你可以在不修改工具定义的前提下约束操作空间。函数调用通常有三种模式(以 NousResearch 的 Hermes 格式为例):
-
自动(Auto): 模型可自行决定是否调用函数。通过预填充回复前缀 <|im_start|>assistant 实现。
-
必需(Required): 模型必须调用一个函数,但可自由选择。通过预填充至 <|im_start|>assistant<tool_call> 实现。
-
指定(Specified): 模型必须从一个给定的子集中选择函数。通过预填充至函数名开头,如 <|im_start|>assistant<tool_call>{“name”: “browser_ 实现。
利用这种机制,我们通过直接掩码 logits 来约束动作选择。例如,当用户提供新输入时,Manus 必须立即回复而非执行动作。我们还有意将动作名称设计成拥有统一的前缀,例如,所有浏览器工具均以 browser_ 开头,所有命令行工具均以 shell_ 开头。这使得我们可以在特定状态下,轻松地强制 Agent 只从某一类工具中选择,而无需依赖复杂 Stateful Logits Processor。
这些设计确保了 Manus Agent 的执行循环,即便在模型驱动的架构下,也能保持高度的稳定性。
将文件系统作为外部上下文
当前的前沿 LLM 已提供 128K 甚至更长的上下文窗口。但在真实的 Agent 场景中,这往往还不够,有时甚至是一种负担。以下是三个常见痛点:
-
观察结果可能极其庞大,尤其是当 Agent 与网页、PDF 等非结构化数据交互时,极易超出上下文长度限制。
-
“大海捞针”问题,即模型性能在上下文长度超过某一阈值后会开始下降,即便窗口在技术上仍未溢出。
-
成本高昂,即使有前缀缓存,你仍需为传输和预填充每个 token 付费。
为了应对这些问题,许多 Agent 系统采用了上下文截断或压缩策略。但过于激进的压缩必然导致信息丢失。这是一个根本性矛盾:Agent 的天性决定了它必须基于所有历史状态来预测下一步动作,而你无法可靠地预知哪个观察结果会在十步之后变得至关重要。从逻辑上讲,任何不可逆的压缩都伴随着风险。
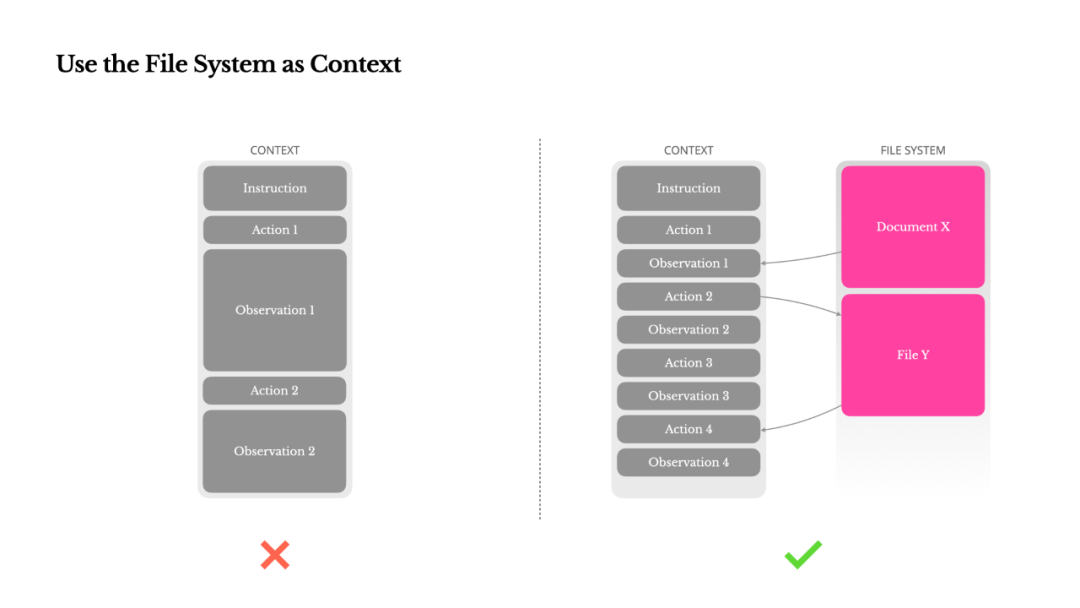
因此,在 Manus 中,我们将文件系统视为最终的上下文:它容量无限,天然持久,且能被 Agent 直接操作。我们训练模型按需读写文件,将文件系统不仅用作存储,更用作一种结构化的外部记忆。
我们的压缩策略始终被设计为可恢复的。例如,只要保留了网页的 URL,其内容就可以从上下文中移除;只要文档的路径在沙箱中可用,其内容就可以被省略。这使得 Manus 可以在不永久丢失信息的前提下,有效缩减上下文长度。
在开发此功能时,我常常思考:如何让状态空间模型(SSM)在 Agent 场景中高效工作?与 Transformer 不同,SSM 缺乏全局注意力,难以处理长程依赖。但如果它们能掌握基于文件的记忆——将长期状态外化存储,而非全部保留在上下文中——那么它们的速度和效率优势或许能催生一类全新的 Agent。具备这种能力的 Agent SSM,或许才是神经图灵机的真正继承者。
通过复述(Recitation)操控注意力
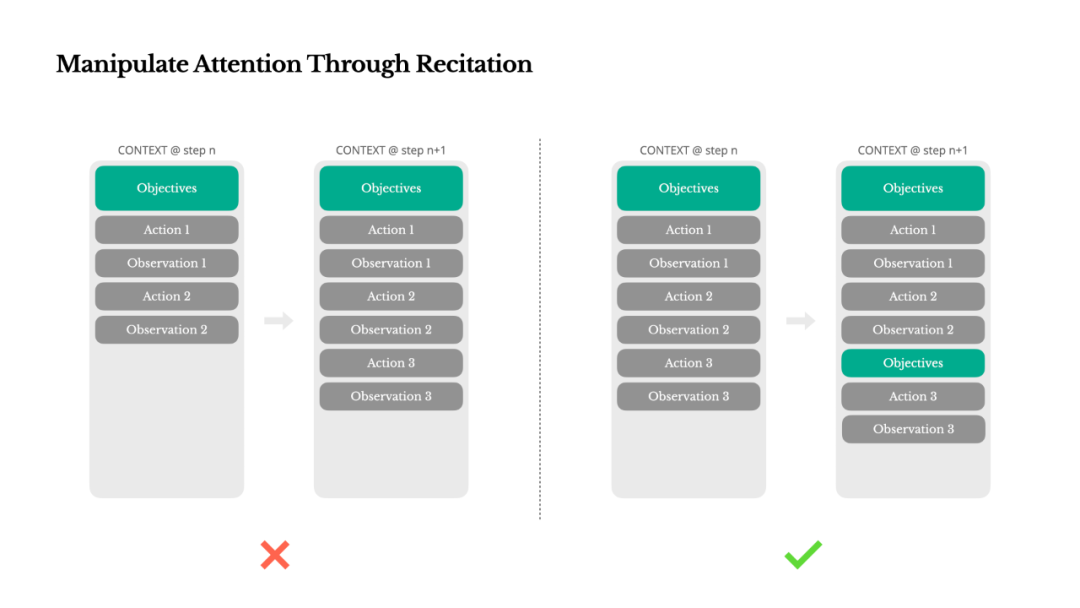
如果你使用过 Manus,可能会注意到一个有趣的现象:在处理复杂任务时,它会创建一个 todo.md 文件,并随着任务的推进逐步更新,勾掉已完成的项。
这并非简单的装饰行为,而是一种有意为之的注意力操控机制。
在 Manus 中,一个典型任务平均需要约 50 次工具调用。这是一个相当长的执行链。由于 Manus 的决策依赖 LLM,它很容易在长上下文或复杂任务中偏离主题或忘记早期目标。
通过不断重写这个待办事项列表,Manus 相当于在将它的核心目标“复述”到上下文的末尾。这使得全局计划始终处于模型近期的注意力范围内,有效避免了“迷失在中间”(lost-in-the-middle)的问题,降低了目标漂移的风险。实际上,它是在用自然语言来引导自身的注意力,使其聚焦于任务目标,而无需任何特殊的架构调整。
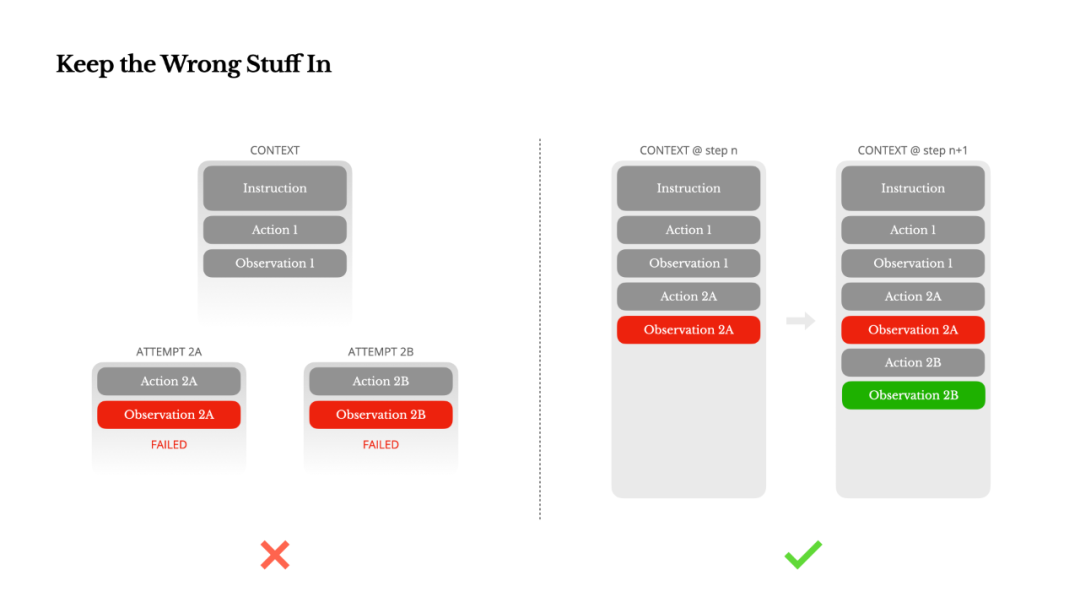
保留失败的尝试
Agent 会犯错。这不是缺陷,而是现实。语言模型会产生幻觉,环境会返回错误,外部工具会出故障,各种意想不到的边缘情况总会发生。在多步骤任务中,失败不是例外,而是循环的一部分。
然而,人们有一种常见的冲动,想要隐藏这些错误:清理执行记录、重试动作,或者重置模型状态,然后寄希望于调高“temperature”参数来“随机”出正确结果。这看似更安全、更可控,但代价是:抹去失败,也就抹去了学习的证据。 没有证据,模型就无法适应和改进。
根据我们的经验,提升 Agent 行为最有效的方法之一,简单得令人意外:将失败的尝试保留在上下文中。当模型看到一个失败的动作——以及由此产生的错误信息或堆栈跟踪(stack trace)——它会隐式地更新其内部认知,从而降低在未来采取类似动作的先验概率,减少重复犯错的可能。
事实上,我们认为错误恢复(error recovery)能力是衡量真正 Agent 智能最清晰的标志之一。然而,在大多数学术研究和公开基准测试中,这一点仍然被严重低估,它们往往只关注理想条件下的任务成功率。
警惕少样本提示的陷阱
少样本提示(Few-shot prompting)是提升 LLM 输出质量的常用技巧,但在 Agent 系统中,它可能会以一种微妙的方式适得其反。
语言模型是出色的模仿者,它们会模仿上下文中的行为模式。如果上下文中充满了大量相似的“动作-观察”对,模型就会倾向于遵循这种模式,即便它已不再是当前情况下的最优解。
这在涉及重复性决策或动作的任务中尤其危险。例如,在使用 Manus 审阅 20 份简历时,Agent 常常会陷入一种固定的节奏——仅仅因为上下文中充满了类似的操作记录,它就开始机械地重复这些动作。这会导致行为漂移、过度泛化,有时甚至产生幻觉。
解决方法是增加多样性。Manus 会在动作和观察结果中引入少量结构化的变体——例如,使用不同的序列化模板、调整措辞、在顺序或格式上引入微小的噪音。这种受控的随机性有助于打破行为定式,并重新激活模型的注意力。
换言之,不要让少样本提示把自己困在思维定式里。你的上下文越是千篇一律,你的 Agent 就会变得越脆弱。
结语
上下文工程仍是一门新兴的科学,但对于 Agent 系统而言,它已是成功的基石。模型也许正变得更强、更快、更便宜,但任何原始能力的提升,都无法取代对记忆、环境和反馈的精心设计。你如何塑造上下文,最终决定了你的 Agent 将如何行事:它的运行速度、纠错能力,以及扩展的潜力。
在 Manus,我们通过一次次的重构、失败的尝试以及对数百万用户的真实世界测试,才学到了这些经验。本文分享的并非放之四海而皆准的真理,但它们是于我们行之有效的模式。如果这些经验能帮助你哪怕只避免一次痛苦的迭代,那这篇文章就实现了它的价值。
Agent 的未来,将由一个个上下文精心构建而成。
· · ·
📢 AI 产品爆发,但你的痛点解决了吗?
2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人
12 大专题分享,洞察趋势、拆解路径、对话未来。
立即扫码领取大会PPT
抢占 AI 产品下一波红利
(文:AI科技大本营)