
国产开源LLM大爆发的一周:腾讯、百度、华为,冲~

百度文心4.5系列开源10款混合专家模型,包含MoE和稠密参数模型;ERNIE-4.5-300B-A47B-Base在28个基准测试中超越DeepSeek-V3-671B-A37B-Base。腾讯Hunyuan-A13B语言模型采用混合推理,支持超长上下文理解;盘古Pro MoE模型使用分组混合专家架构,参数量高达72B、激活参数量16B。
百度文心4.5系列开源10款混合专家模型,包含MoE和稠密参数模型;ERNIE-4.5-300B-A47B-Base在28个基准测试中超越DeepSeek-V3-671B-A37B-Base。腾讯Hunyuan-A13B语言模型采用混合推理,支持超长上下文理解;盘古Pro MoE模型使用分组混合专家架构,参数量高达72B、激活参数量16B。

MiniMax发布首款推理模型M1,支持最高100万Token上下文输入和8万Token推理输出,采用混合专家架构及闪电注意力机制。其训练阶段仅需512张英伟达H800 GPU三周完成,成本仅为384万元人民币,提供低廉API服务。MiniMax采取区间定价策略,并透露该模式加速AI智能体大规模应用。
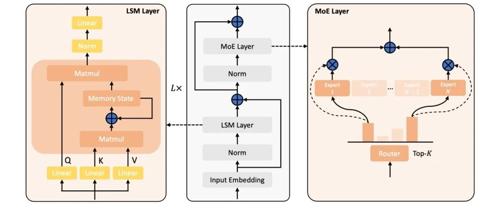
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。

阿里巴巴开源新一代通义千问Qwen3系列模型,包含8款不同尺寸。旗舰模型Qwen3 235B采用混合专家(MoE)架构,在多项测评中超越DeepSeek-R1、OpenAI-o1等主流模型。性能提升体现在推理、指令遵循、工具调用、多语言能力等方面。Qwen3全尺寸发布后,社区反响热烈,参数正在“变小”但保持出色表现。

腾讯发布混元 Turbo S模型,实现首字时延降低44%和吐字速度翻倍,重新定义人机交互即时性标准,揭示中国AI技术路径从’堆参数’到’拼效率’的转向。

OpenAI联合创始人Andrej Karpathy分享了中国开源大模型DeepSeek-v3,仅使用280万小时GPU算力即超越Llama-3。该模型在多种基准测试中表现优异,并采用MLA和MoE等高效策略节省大量计算资源。

华中科技大学提出MoE Jetpack框架,利用密集激活模型权重微调出混合专家(MoE)模型,大幅提升了精度和收敛速度,解决MoE预训练需求高问题。

