103K「硬核」题,让大模型突破数学推理瓶颈

本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。
本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。

工学院举办的信息学研讨会上发表了一场演讲,主题为「
AI 的重要趋势:我们是如何走到今天的,我们现在

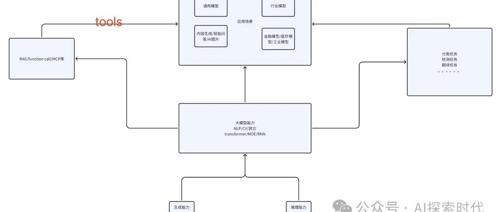
近期文章讨论了关于推理大模型以及DeepMath-103K数据集的相关进展和思考。主要内容包括推理大模型的研究方向、推理模型的数据集构建方案,以及RAG方向的发展与应用。

MLNLP是国内外知名的人工智能社区,致力于推动自然语言处理与机器学习领域的交流与发展。2025年出现的DeepSeek模型通过技术革新颠覆了行业现状,展示了技术实力和成本优势。

文章介绍了通过16块H100 GPU在26分钟内训练出低成本语言模型S1K的方法,该模型与OpenAI的o1系列和DeepSeek R1系列性能相当。但实际研究发现,论文核心是基于开源Qwen2.5-32B模型,进行小数据集监督微调,并非直接复制了DeepSeek R1。