

今天是2025年4月18日,星期五,北京,雨。
关于大模型数学推理数据集已经有很多了,也是一个论文研究方向,这里,我们来看最近的代表工作,DeepMath-103K。
此外,来看看关于推理模型以及GraphRAG相关的一些进展,有些观点可以看看,供批评指正。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、推理大模型以及KAG的进展和一些思考
最近,我和昊奋以及徐彬两位老师聊了聊推理模型革命,有一些有趣的观点供大家批评指正,内容较多,https://mp.weixin.qq.com/s/xqSZTtukR3DqfC8EBlfSIQ,大家感兴趣的可以看看,主要谈到了一些有趣的点,包括:什么是“慢思考”与推理模型革命、推理模型的核心技术突破与挑战、产业AI新范式:从“数据驱动”转向“知识+数据双驱动” 、推理模型的局限与破局之道以及人机协同与未来展望等。
例如,关于快思考 VS 慢思考:

又如,关于推理模型适合做什么?

又如推理大模型出来之后的陌生化现象

此外,RAG方向,蚂蚁梁磊老师团队的工作页更新啦,https://github.com/OpenSPG/openspg,https://github.com/OpenSPG/KAG,https://openspg.github.io/v2/,这里有个点,理清,就是OpenSPG和KAG关系。
OpenSPG是语义增强的可编程知识图谱,KAG是一个知识增强生成的专业领域知识服务框架,KAG依赖OpenSPG提供的引擎依赖适配、知识索引、逻辑推理等能力,用于构建垂直领域知识库的逻辑推理问答。

KAG的核心之一是提出一种逻辑符号引导的混合求解和推理引擎,该引擎包括三种类型的运算符:规划、推理和检索,将自然语言问题转化为结合语言和符号的问题求解过程。在这个过程中,每一步都可以利用不同的运算符,如精确匹配检索、文本检索、数值计算或语义推理,从而实现四种不同问题求解过程的集成:图谱推理、逻辑计算、Chunk 检索和 LLM 推理。
具体使用可以看看:https://openspg.yuque.com/ndx6g9/0.6/pse8ku7bpqsd5d3x
二、DeepMath-103K推理数据集构造方案
最近的工作《DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning》(https://arxiv.org/pdf/2504.11456,https://github.com/zwhe99/DeepMath),包括高难度、可验证的最终答案和多种解决方案路径。
其中关于数据构建上,可以看下怎么做的,如下所示,是一个数据生产流程:

1、数据集有什么特点
重点关注困难的数学问题(主要是 5-9 级),与许多现有的开放数据集相比,复杂性高一些,如下面就是代表性的数据集
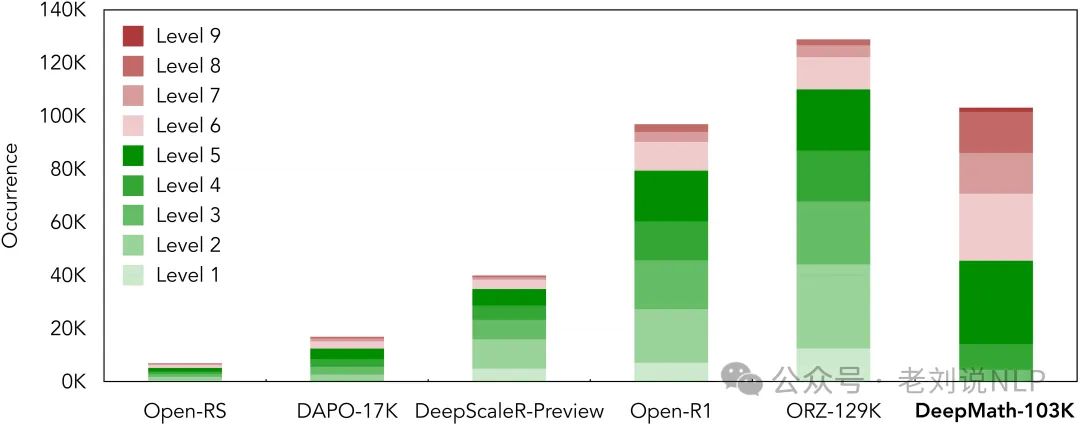
数据集涵盖了广泛的数学学科,包括代数、微积分、数论、几何、概率和离散数学。

由多种来源构建而成,并使用语义匹配技术,根据常用基准进行了细致的去污处理。这最大限度地减少了测试集泄漏,并促进了公平的模型评估。

每个样本都DeepMath-103K包含丰富的信息,包括:问题,数学问题陈述;最终答案,可靠且可验证的最终答案;难度,用于难度感知训练或分析的数值分数;主题,针对特定主题应用的层次分类;R1解决方案,来自DeepSeek-R1的三种不同的推理路径。

2、如何做去污染?
榜单污染是目前数据集普遍存在的问题,因此,为了降低这一问题的影响,有多种应对策略。
一个是语义相似度搜索,对于原始数据集中的每个候选问题,使用paraphrase-multilingual-MiniLM-L12-v2模型进行语义相似度搜索,识别出与目标基准测试集中最相似的例子。
一个是LLM-Judge比较,将每个候选问题与检索到的最相似示例进行比较,使用Llama-3.3-70B-Instruct模型判断它们是否构成相同的问题或同义句。为了减少位置偏差,每对候选问题进行两次比较,每次交换问题的顺序。
一个是去重处理,如果任何一次比较中发现潜在的同义或重复问题,则将该候选问题丢弃。
3、怎么做的难度?
采用了Omni-MATH(https://huggingface.co/datasets/KbsdJames/Omni-MATH,https://arxiv.org/pdf/2410.07985v3)的方案,通过提示GPT-4o为每个去污染的问题分配一个难度等级。

对每个问题进行了六次查询,并平均其结果评分以确定其最终难度等级。随后,采用了一个严格的过滤标准,只保留估计难度等级为5级或以上的问题。

4、这个数据集能用来做什么?
可以从一下几个方向上去开展下游应用。
一个是监督微调,每个问题提供三个不同的R1生成的解决方案,创建丰富的监督训练语料库。这种多样性有助于模型学习不同的解题策略,从而更好地泛化到未见过的问题。
一个是模型蒸馏,较大的教师模型(如R1-Distill-Qwen-1.5B)可以将多样化的解题风格传授给较小的学生模型,增强学生模型的覆盖范围和解题策略。
一个是基于规则的强化学习(如RL-Zero),每个问题提供可验证的最终答案,直接应用于RL框架中的规则奖励,促进深度推理。
一个是奖励建模,设计区分高质量和低质量推理步骤的奖励模型,这在RL框架中不仅可以改进策略梯度,还可以在多步解码管道中重新排序或评分候选解决方案。
参考文献
1、https://arxiv.org/pdf/2504.11456
2、https://mp.weixin.qq.com/s/xqSZTtukR3DqfC8EBlfSIQ
(文:老刘说NLP)