
多模态大模型文心4.5后训练详解
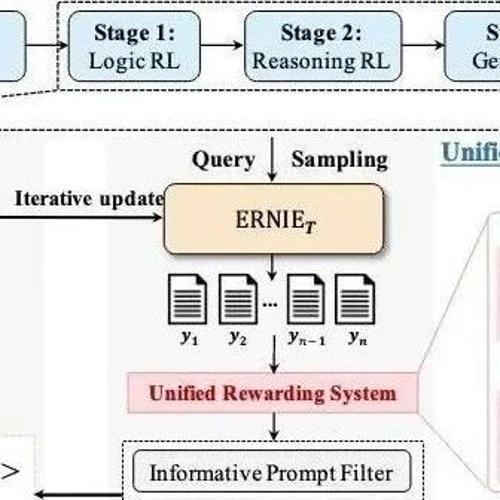
MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与发展,涵盖硕博生、高校老师及企业研究人员。文心4.5开源10个多模态大模型,并介绍其后训练阶段的技术细节。
MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与发展,涵盖硕博生、高校老师及企业研究人员。文心4.5开源10个多模态大模型,并介绍其后训练阶段的技术细节。
型。
这款被马斯克称之为“宇宙最强模型”的大模型由20万块GPU组成的Colossus超级计算机集群
新智元报道
编辑:桃子 好困
全球最强的开源定理证明器登场!Goedel-Prover-V2仅用8B参数击败671B的DeepSeek-Prover,并再次夺下数学PutnamBench冠军。十位核心贡献者,八大顶尖机构联手发布第二版模型。
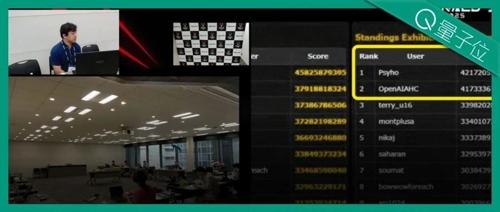
人类选手Psycho在AtCoder世界巡回总决赛中两次反超,最终获得冠军。OpenAI排名第二,并承认自己是亚军。比赛过程中,Psycho表现出色,而OpenAI则在后半段出现多次错误。

普林斯顿大学联合多所顶尖机构推出Goedel-Prover-V2模型,实现形式化数学推理的新突破。该模型在MiniF2测试集上性能超越DeepSeek-Prover-671B和Kimina-Prover-72B。

国外小哥受皮克斯台灯机器人启发,手搓出一款结构简单的AI桌宠Shoggoth,具备对话和互动能力。通过3D打印、GPT-4o API及RL策略控制,实现类似宠物的陪伴感。

Jason Wei 提出了‘验证者定律’,指出训练 AI 解决任务的难易程度与其可验证性成正比。他还提出了 ‘On-Policy RL’ 的概念,认为要想超越他人,必须走自己的路,并直面环境给予的风险与回报。


